This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
Since databases store companies’ valuable digital assets and corporate secrets, they are on the receiving end of quite a few cyber-attack vectors these days. How can database activity monitoring (DAM) tools help avoid these threats? What are the ties between DAM and data loss prevention (DLP) systems? How do DAM solutions work?
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse. Database size limits of 10GB.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. A document is susceptible to change.
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). Project documentation ¶ As data science codebases live longer, code is often refactored into a package.
Other uses may include: Maintenance checks Guides, resources, training and tutorials (all available in BigQuery documentation ) Employee efficiency reviews Machine learning Innovation advancements through the examination of trends. (1). Big data analytics advantages. What is Big Data?” References.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. When documents are split into smaller chunks, search systems can find relevant sections more precisely and quickly.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
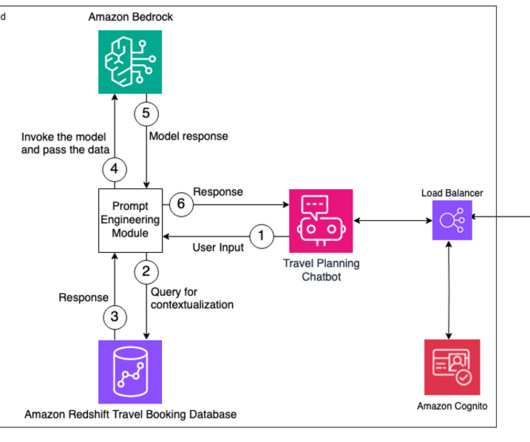
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. Now you’re ready to connect to the EC2 instance using SSH. Open an SSH client.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
You need to make sure that all departments are data-friendly and in sync with each other. Most will include documentation of data sources, the KPIs of the specific industry, the kind of reporting necessary, and whether or not the data flow will require automation. Set Up Data Integration. Develop a Strategy.
Snowflake’s solution to this was to create a Streaming API that can be used to connect and write directly to the database using your own managed application, which lowers latency and removes the requirement of storing files in a stage. Next, we create a request and we set the Database, Schema, and Table that the request should point at.
For our hypothetical car company, we will use Dataiku’s Answers application to create a personalized customer service chatbot that can pull data from warranty contracts, car spec manuals, and customer history to respond to inquiries. Dataiku and Snowflake: A Good Combo?
Examples of data sources and destinations include: Shopify Google Analytics Snowflake Data Cloud Oracle Salesforce Fivetran’s mission is to, “make access to data as easy as electricity” – so for the last 10 years, they have developed their platform into a leader in the cloud-based ELT market. What is Fivetran Used For?
To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses. The importance of ETL tools is underscored by their ability to handle diverse data sources, from relational databases to cloud-based services.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Without the right skillsets, no value can be created from data. New Big Data Concepts vs Cloud Delivered Databases? So, what has the emergence of cloud databases done to change big data? For starters, the cloud has made data more affordable. “Setting up Hadoop on-premises was a huge undertaking. [You
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract has a Tables feature within the AnalyzeDocument API that offers the ability to automatically extract tabular structures from any document.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. This type of next-generation data store combines a data lake’s flexibility with a datawarehouse’s performance and lets you scale AI workloads no matter where they reside.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
A data lake is a centralized repository containing extensive storage for raw, unfiltered data coming into a company’s data storage system. This data can be structured, semi-structured, or unstructured and comes from various sources such as databases, IoT devices, log files, etc.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Production databases are a data-rich environment, and Fivetran would help us to migrate data by moving data from on-prem to the supported destinations; ensuring that this data remains uncorrupted throughout enhancements and transformations is crucial. We will now go over all the topics one by one.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. Warehouse for loading the data (start with XSMALL or SMALL warehouses). See the Salesforce documentation for more information. Click Next.
Modernizing your data infrastructure to hybrid cloud for applications, analytics and gen AI Adopting multicloud and hybrid strategies is becoming mandatory, requiring databases that support flexible deployments across the hybrid cloud. This ensures you have a data foundation that grows with your data needs, wherever your data resides.
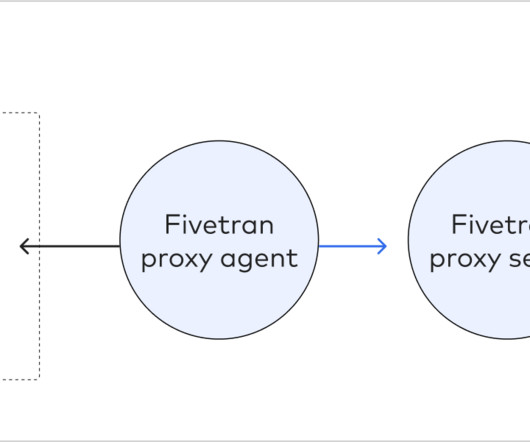
This post was co-written by Arnab Mondal and Ayush Kumar Singh Fivetran’s LDP, or Local Data Processing (which was previously known as HVR or High Volume Replicator), is a data replication tool that helps businesses move data from one data source to another. For more information on HVA, visit the official documentation.
This post was co-written by Arnab Mondal and Ayush Kumar Singh Fivetran’s LDP, or Local Data Processing (which was previously known as HVR or High Volume Replicator), is a data replication tool that helps businesses move data from one data source to another. For more information on HVA, visit the official documentation.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. She is passionate about data-driven AI and the area of depth in machine learning.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Like most Gen AI use cases, the first step to achieving customer service automation is to clean and centralize all information in a datawarehouse for your AI to work from. Document Search Everyone who’s ever read a product manual knows it can be notoriously complex, and finding the information you’re looking for is difficult.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The stored data is visualized in a BI dashboard using QuickSight.
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 data lake, Snowflake cloud datawarehouse and Tableau (and how it can be fixed). Time is money,” said Leonard Kwok, Senior Data Analyst, ARC.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
Consider factors such as data volume, query patterns, and hardware constraints. Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. Use indexing and partitioning strategies to improve query performance.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. This documentation is invaluable for future reference and modifications. Simplify hierarchies where possible and provide clear documentation to help users understand the structure.
The product collected an impressive amount of metadata, from the user interface to the database structure. It wouldn’t be until 2013 that the topic of data lineage would surface again – this time while working on a datawarehouse project. It then translated all that metadata into an image resembling a spider’s web.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content