This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
To further explore this topic, I am surveying real-world serverless, multi-tenant data architectures to understand how different types of systems, such as OLTP databases, real-time OLAP, cloud datawarehouses, event streaming systems, and more, implement serverless MT.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
Since databases store companies’ valuable digital assets and corporate secrets, they are on the receiving end of quite a few cyber-attack vectors these days. How can database activity monitoring (DAM) tools help avoid these threats? What are the ties between DAM and data loss prevention (DLP) systems? How do DAM solutions work?
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
When it comes to data sources, analytic apps developers are facing new and increasingly complex challenges, such as having to deal with higher demand from eventdata and streaming sources. The post Is Your Database Built for Streaming Data? Yet while streams are clearly the […].
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
The task of keeping multiple databases in sync so that data is accurate, up-to-date, and highly available is every data consumer’s biggest challenge. Oracle is one of the largest IT companies whose flagship product, Oracle Database, is a relational database management system. What is Oracle?
The Q4 Platform facilitates interactions across the capital markets through IR website products, virtual events solutions, engagement analytics, investor relations Customer Relationship Management (CRM), shareholder and market analysis, surveillance, and ESG tools. Use case overview Q4 Inc.,
This open format allows for seamless storage and retrieval of data across different databases. By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos.
Snowflake’s solution to this was to create a Streaming API that can be used to connect and write directly to the database using your own managed application, which lowers latency and removes the requirement of storing files in a stage. Next, we create a request and we set the Database, Schema, and Table that the request should point at.
Thus, was born a single database and the relational model for transactions and business intelligence. Its early success, coupled with IBM WebSphere in the 1990s, put it in the spotlight as the database system for several Olympic games, including 1992 Barcelona, 1996 Atlanta, and the 1998 Winter Olympics in Nagano.
Batch-processing systems that process data rows in batch (mainly via SQL ). Examples include real-time and datawarehouse systems that power Meta’s AI and analytics workloads. Data annotation can be done at various levels of granularity, including table, column, row, or potentially even cell.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a datawarehouse or a database. First, the data is extracted from the various sources and brought into a staging area.
Overall, this partnership enables the retailer to make data-driven decisions, improve supply chain efficiency and ultimately boost customer satisfaction, all in a secure and scalable cloud environment. The platform provides an intelligent, self-service data ecosystem that enhances data governance, quality and usability.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Some even provide a relational layer specifically designed for analytics, while others expose APIs.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. On the Name, review, and create page, enter a role name, review the settings, and choose Create role.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Must Read Blogs: Exploring the Power of DataWarehouse Functionality. Data Lakes Vs. DataWarehouse: Its significance and relevance in the data world. Exploring Differences: Database vs DataWarehouse. It is commonly used in datawarehouses for business analytics and reporting.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Building and maintaining data pipelines Data integration is the process of combining data from multiple sources into a single, consistent view. This involves extracting data from various sources, transforming it into a usable format, and loading it into datawarehouses or other storage systems.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud datawarehouse or data lake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Best Practice 5.
Production databases are a data-rich environment, and Fivetran would help us to migrate data by moving data from on-prem to the supported destinations; ensuring that this data remains uncorrupted throughout enhancements and transformations is crucial. We will now go over all the topics one by one.
With the database services launched soon after, developers had all the tools they needed to create applications without having to create the infrastructure to run them. AWS positions itself as an end-to-end solution with full integration of BI, ML, storage and database tools, and customer stories support this.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
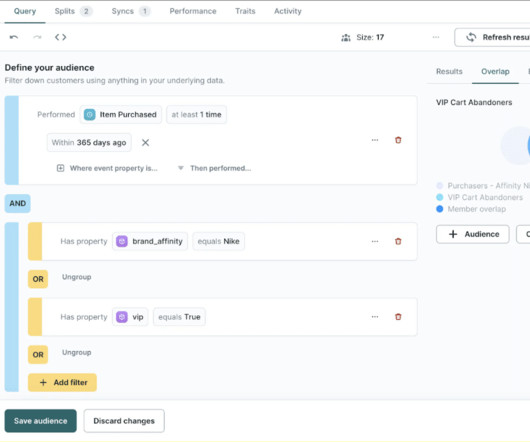
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data. Event Tracking : Capturing behavioral events such as page views, add-to-cart, signup, purchase, subscription, etc.
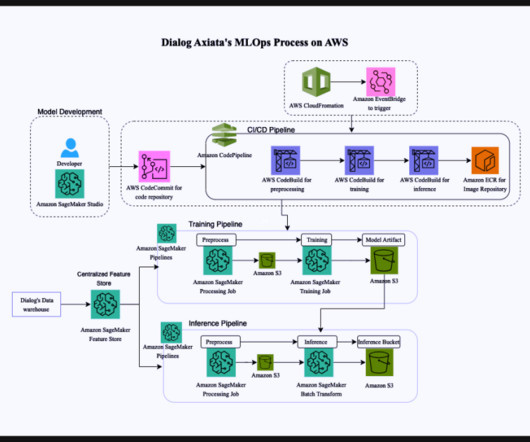
This meticulous approach allows Dialog Axiata to gain valuable insights into customer behavior, enabling them to predict potential churn events with remarkable accuracy. Instead of directly ingesting data from the datawarehouse, the required features for training and inference steps are taken from the feature store.
We have built one of the largest databases of brand impressions in the world with over 6 billion data points. The analyst is given direct access to the raw data or through our datawarehouse. He excels in building and deploying deep learning models to handle large-scale data efficiently.
Snowflake’s built-for-the-cloud architecture is highly performant and designed to handle large volumes of data and data consumers. Because of its cloud architecture, users do not have to worry about the maintenance of the infrastructure and the database going down at an inopportune time.
Like most Gen AI use cases, the first step to achieving customer service automation is to clean and centralize all information in a datawarehouse for your AI to work from. As with customer service automation, the main challenge is to have all your product manuals and documentation in a central database for the AI to process.
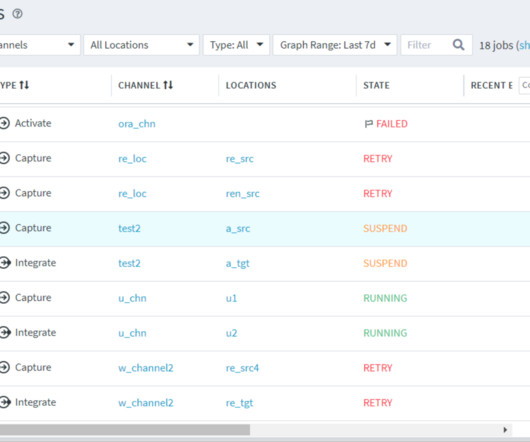
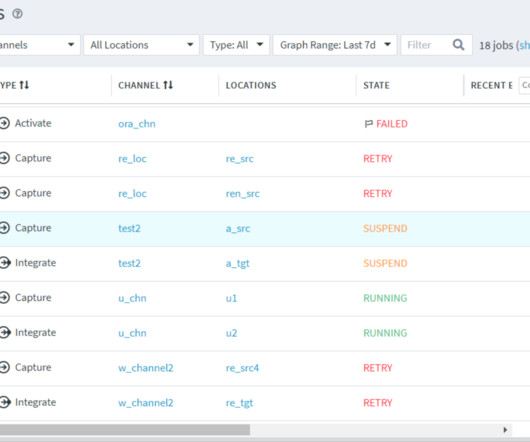
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 data lake, Snowflake cloud datawarehouse and Tableau (and how it can be fixed). Time is money,” said Leonard Kwok, Senior Data Analyst, ARC.
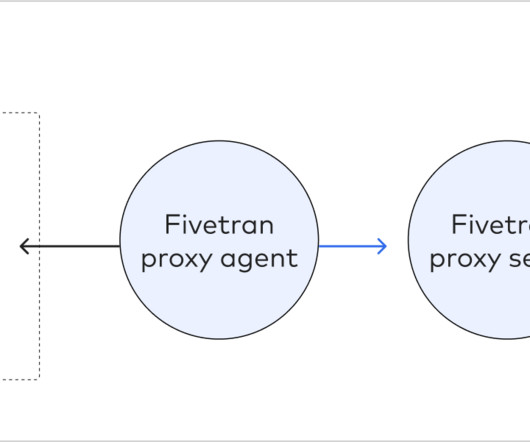
This post was co-written by Arnab Mondal and Ayush Kumar Singh Fivetran’s LDP, or Local Data Processing (which was previously known as HVR or High Volume Replicator), is a data replication tool that helps businesses move data from one data source to another. POWERPC-64BIT (AIX: 6.1, Linux (x86-64 bit) based on GLIBC 2.12
This post was co-written by Arnab Mondal and Ayush Kumar Singh Fivetran’s LDP, or Local Data Processing (which was previously known as HVR or High Volume Replicator), is a data replication tool that helps businesses move data from one data source to another. POWERPC-64BIT (AIX: 6.1, Linux (x86-64 bit) based on GLIBC 2.12
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions. Once data is collected, it needs to be stored efficiently.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of data pipelines. Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures.
This ensures that BI applications can handle data growth without sacrificing performance or responsiveness. BI workloads can be dynamic, with varying demands depending on factors such as time of day, seasonality, or specific business events. Snowflake supports encryption at rest and in transit. Contact our Team of Snowflake Experts!
These tables are called “factless fact tables” or “junction tables” They are used for modelling many-to-many relationships or for capturing timestamps of events. Dealing with Sparse Data In some cases, fact tables may contain a large number of null values due to missing data.
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
Data Pipeline Architecture — Stop Building Monoliths Elliott Cordo | Founder, Architect, Builder | Datafutures Although common, data monoliths present several challenges, especially for larger teams and organizations that allow for federated data product development. Interested in attending an ODSC event?
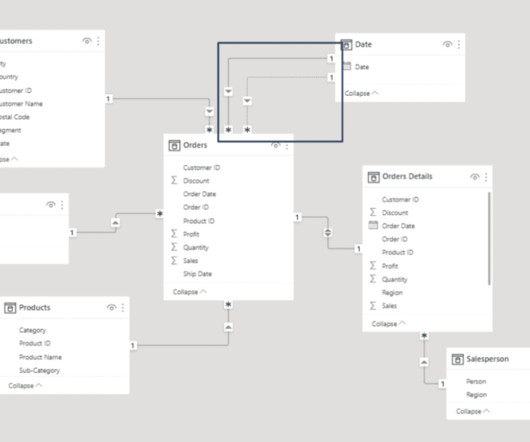
A data model typically consists of one or more data sources, which can be anything from Excel spreadsheets to cloud-based databases and one or more tables that represent the data in those sources. The relationships that connect these tables are the cornerstone of data modeling and the main topic of this blog.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






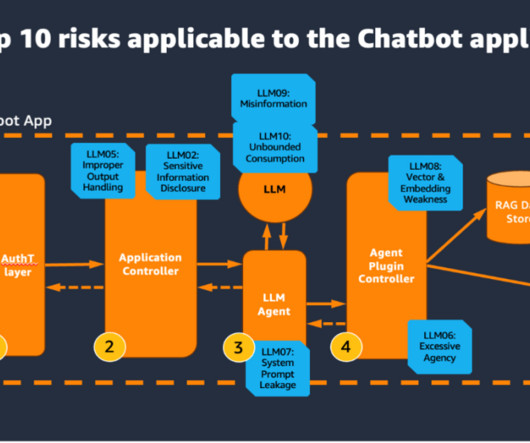



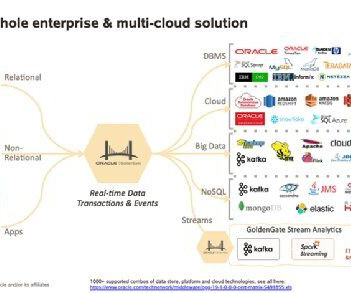


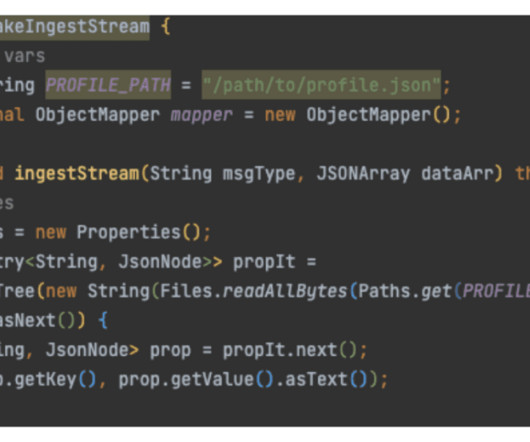



























Let's personalize your content