This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Have you ever wondered how big IT giants store and process huge amounts of data? Different organizations make use of different databases like an oracle database storing transactional data, MySQL for storing product data, and many others for different tasks. storing the data […].
Hadoop has become synonymous with big data processing, transforming how organizations manage vast quantities of information. As businesses increasingly rely on data for decision-making, Hadoop’s open-source framework has emerged as a key player, offering a powerful solution for handling diverse and complex datasets.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Hadoop systems and data lakes are frequently mentioned together.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
This article was published as a part of the Data Science Blogathon. Introduction Apache SQOOP is a tool designed to aid in the large-scale export and import of data into HDFS from structured data repositories. Relational databases, enterprise datawarehouses, and NoSQL systems are all examples of data storage.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases. Understand data warehousing concepts: Data warehousing is the process of collecting, storing, and managing large amounts of data.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
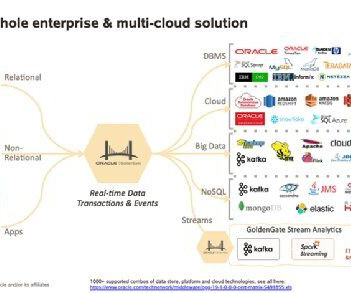
The task of keeping multiple databases in sync so that data is accurate, up-to-date, and highly available is every data consumer’s biggest challenge. Oracle is one of the largest IT companies whose flagship product, Oracle Database, is a relational database management system. What is Oracle?
Without the right skillsets, no value can be created from data. New Big Data Concepts vs Cloud Delivered Databases? So, what has the emergence of cloud databases done to change big data? For starters, the cloud has made data more affordable. “Setting up Hadoop on-premises was a huge undertaking.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or data lake.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a datawarehouse or a database. First, the data is extracted from the various sources and brought into a staging area.
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
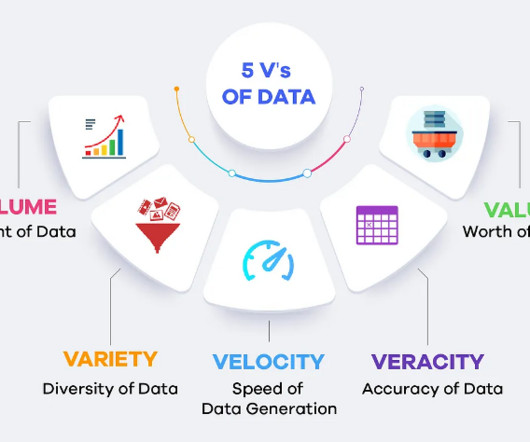
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions. Once data is collected, it needs to be stored efficiently.
First, lets understand the basics of Big Data. Key Takeaways Understand the 5Vs of Big Data: Volume, Velocity, Variety, Veracity, Value. Familiarise yourself with essential tools like Hadoop and Spark. Practice coding skills in languages relevant to Big Data roles. Veracity Data reliability and quality vary significantly.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
The real advantage of big data lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
Because of its distributed nature, Presto scales for petabytes and exabytes of data. The evolution of Presto at Uber Beginning of a data analytics journey Uber began their analytical journey with a traditional analytical database platform at the core of their analytics. It also provides features like indexing and caching.”
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
Consequently, here is an overview of the essential requirements that you need to have to get a job as an Azure Data Engineer. In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Sound knowledge of relational databases or NoSQL databases like Cassandra.
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services. Database Extraction: Retrieval from structured databases using query languages like SQL. DataWarehouses : Centralised repositories optimised for analytics and reporting.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. It will automatically scale queries to handle any size data set, so you can focus on analyzing your data.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and datawarehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
Below are some prominent use cases for Apache NiFi: Data Ingestion from Diverse Sources NiFi excels at collecting data from various sources, including log files, sensors, databases, and APIs. IoT Data Processing With the rise of the Internet of Things (IoT), NiFi is increasingly used to process data generated by IoT devices.
Types of Unstructured Data As unstructured data grows exponentially, organisations face the challenge of processing and extracting insights from these data sources. Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. First of all, machine learning engineers and data scientists often use data from different data vendors.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. By harnessing the power of Big Data tools, organisations can transform raw data into actionable insights that foster innovation and competitive advantage.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content