This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A SageMaker domain. A QuickSight account (optional).
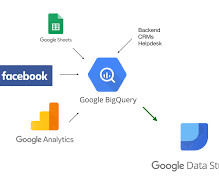
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a MachineLearning Model in BigQuery appeared first on Analytics Vidhya.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Some NoSQL databases are also utilized as platforms for data lakes.
It powers business decisions, drives AI models, and keeps databases running efficiently. But heres the problem: raw data is often messy. Without proper organization, databases become bloated, slow, and unreliable. Thats where data normalization comes in. Thats where data normalization comes in.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-cloud datawarehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
Organisations must store data in a safe and secure place for which Databases and Datawarehouses are essential. You must be familiar with the terms, but Database and DataWarehouse have some significant differences while being equally crucial for businesses. What is a Database?
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. Cloud based solutions are the future of the data warehousing market.
Since databases store companies’ valuable digital assets and corporate secrets, they are on the receiving end of quite a few cyber-attack vectors these days. How can database activity monitoring (DAM) tools help avoid these threats? What are the ties between DAM and data loss prevention (DLP) systems? How do DAM solutions work?
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Dataiku is an advanced analytics and machinelearning platform designed to democratize data science and foster collaboration across technical and non-technical teams. Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machinelearning models.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
Data is the foundation for machinelearning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Import the Parquet data to Canvas using Athena. Use the imported Parquet data to build ML models with Canvas.
Now they can access databases and datawarehouses, as well as unstructured business data, like emails, reports, charts, graphs, and images. Access all your data whether its stored in data lakes, datawarehouses, third-party or federated data sources. And now, it still is.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machinelearning (ML) and analytics solutions in R at scale. Loading data in Amazon Redshift Serverless. The CloudFormation script created a database called sagemaker.
Azure Synapse provides a unified platform to ingest, explore, prepare, transform, manage, and serve data for BI (Business Intelligence) and machinelearning needs. DWUs (DataWarehouse Units) can customize resources and optimize performance and costs.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Data mining is a fascinating field that blends statistical techniques, machinelearning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure Data Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. R Support for Azure MachineLearning. Azure Synapse. It’s true, I saw it happen this week.
Other uses may include: Maintenance checks Guides, resources, training and tutorials (all available in BigQuery documentation ) Employee efficiency reviews Machinelearning Innovation advancements through the examination of trends. (1). Big data analytics advantages. Is Google BigQuery the future of big data analytics?
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
Get ready to supercharge your machine-learning projects and unlock new levels of productivity. Image by Author Configure PostgreSQL Database Step 1. Search for RDS Services, click on Create database, and select Standard create & move down. But how EC2 will communicate with this database? Let’s dive in!
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Complete the following steps: On the project page, choose Data.
A point of data entry in a given pipeline. Examples of an origin include storage systems like data lakes, datawarehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
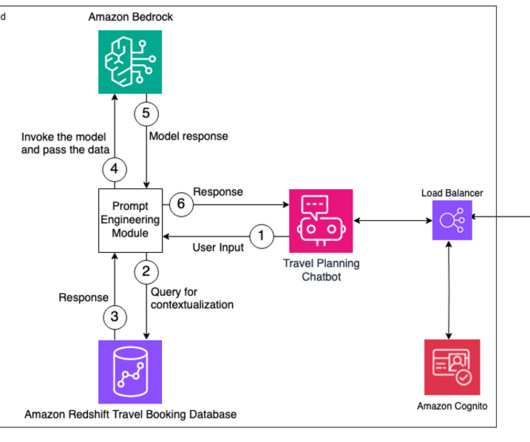
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. Now you’re ready to connect to the EC2 instance using SSH. Open an SSH client.
Enhanced insights through AI : Fabric’s generative AI capabilities, such as Copilot, enhance Power BI by enabling users to use conversational language to create data flows, build machinelearning models, and derive deeper insights.
Machinelearning (ML) is only possible because of all the data we collect. However, with data coming from so many different sources, it doesn’t always come in a format that’s easy for ML models to understand. Why Prepare Data for MachineLearning Models? As the saying goes: “Garbage in, garbage out.”
Five Best Practices for Data Analytics. Extracted data must be saved someplace. There are several choices to consider, each with its own set of advantages and disadvantages: Datawarehouses are used to store data that has been processed for a specific function from one or more sources. Select a Storage Platform.
Machinelearning (ML)—the artificial intelligence (AI) subfield in which machineslearn from datasets and past experiences by recognizing patterns and generating predictions—is a $21 billion global industry projected to become a $209 billion industry by 2029.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
Considering the nature of the time series dataset, Q4 also realized that it would have to continuously perform incremental pre-training as new data came in. This would have required a dedicated cross-disciplinary team with expertise in data science, machinelearning, and domain knowledge.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificial intelligence and machinelearning to unify and securely manage disparate data sources without migrating them to a centralized location.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificial intelligence and machinelearning to unify and securely manage disparate data sources without migrating them to a centralized location.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content