This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift datawarehouse.
It powers business decisions, drives AI models, and keeps databases running efficiently. But heres the problem: raw data is often messy. Without proper organization, databases become bloated, slow, and unreliable. Thats where data normalization comes in. Thats where data normalization comes in.
Published: June 11, 2025 Announcements 5 min read by Ali Ghodsi , Stas Kelvich , Heikki Linnakangas , Nikita Shamgunov , Arsalan Tavakoli-Shiraji , Patrick Wendell , Reynold Xin and Matei Zaharia Share this post Keep up with us Subscribe Summary Operational databases were not designed for today’s AI-driven applications.
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
In the modern, cloud-centric business landscape, data is often scattered across numerous clouds and on-site systems. This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machine learning (ML) initiatives.
Second, based on this natural language guidance, our algorithms intelligently translate the guidance into technical optimizations – refining the retrieval algorithm, enhancing prompts, filtering the vector database, or even modifying the agentic pattern.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose Continue. Review the input, and choose Create project.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
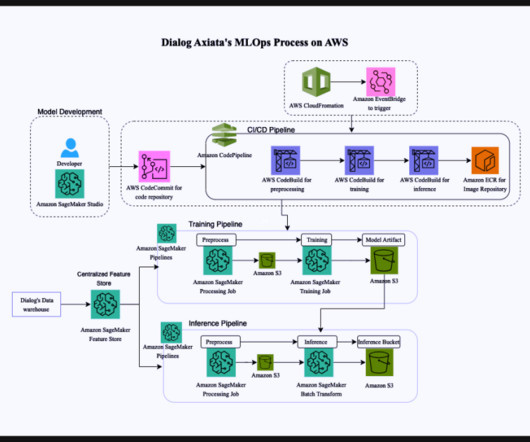
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. million subscribers, which amounts to 57% of the Sri Lankan mobile market.
With our cleaned data from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science. This capability can reveal hidden patterns and optimize data for improved model performance. Dataiku and Snowflake: A Good Combo?
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
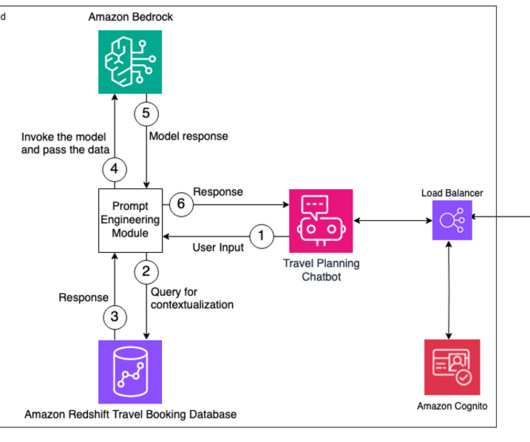
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. Now you’re ready to connect to the EC2 instance using SSH. Open an SSH client.
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Loading data in Amazon Redshift Serverless. The CloudFormation script created a database called sagemaker.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. This tool automatically detects problems in an ML dataset.
To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures. Now, let’s chat about why datawarehouse optimization is a key value of a data lakehouse strategy. To effectively use raw data, it often needs to be curated within a datawarehouse.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and data lakes.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The generated query is then run against the database to fetch the relevant context. Based on the initial tests, this method showed great results.
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. Answer : Yes, Amazon RDS for Db2 can support analytics workloads, but it is not a datawarehouse. Amazon RDS
With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Import the Parquet data to Canvas using Athena. Use the imported Parquet data to build ML models with Canvas.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Thus, was born a single database and the relational model for transactions and business intelligence. Its early success, coupled with IBM WebSphere in the 1990s, put it in the spotlight as the database system for several Olympic games, including 1992 Barcelona, 1996 Atlanta, and the 1998 Winter Olympics in Nagano.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Are you interested in exploring Snowflake as a vector database? Contact phData Today!
Although these traditional machine learning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
Without the right skillsets, no value can be created from data. New Big Data Concepts vs Cloud Delivered Databases? So, what has the emergence of cloud databases done to change big data? For starters, the cloud has made data more affordable. To improve ML and Ethics, data literacy training is critical.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
The Microsoft Certified Solutions Associate and Microsoft Certified Solutions Expert certifications cover a wide range of topics related to Microsoft’s technology suite, including Windows operating systems, Azure cloud computing, Office productivity software, Visual Studio programming tools, and SQL Server databases.
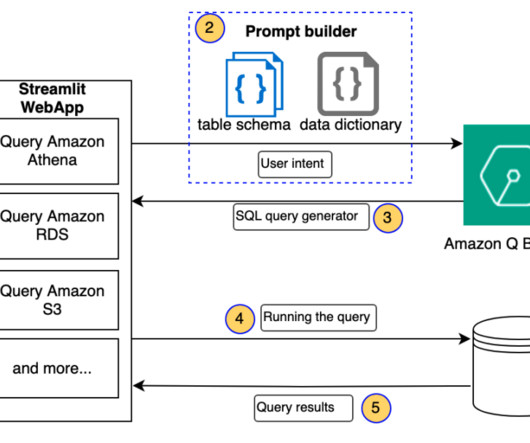
To bridge this gap, you need advanced natural language processing (NLP) to map user queries to database schema, tables, and operations. In this post, we discuss an architecture to query structured data using Amazon Q Business, and build out an application to query cost and usage data in Amazon Athena with Amazon Q Business.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content