This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictiveanalytics, that enable faster decision making and insights.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Predictiveanalytics: Predictiveanalytics leverages historical data and statistical algorithms to make predictions about future events or trends. For example, predictiveanalytics can be used in financial institutions to predict customer default rates or in e-commerce to forecast product demand.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
From data ingestion and cleaning to model deployment and monitoring, the platform streamlines each phase of the data science workflow. Automated features, such as visual data preparation and pre-built machine learning models, reduce the time and effort required to build and deploy predictiveanalytics.
Thus, was born a single database and the relational model for transactions and business intelligence. Its early success, coupled with IBM WebSphere in the 1990s, put it in the spotlight as the database system for several Olympic games, including 1992 Barcelona, 1996 Atlanta, and the 1998 Winter Olympics in Nagano.
Open source business intelligence software provides a cost-effective and flexible way for businesses to access and analyze their data. Data visualization: Open source BI software offers a range of visualization options, including charts, graphs, and dashboards, to help businesses understand their data and make informed decisions.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Defining OLAP today OLAP database systems have significantly evolved since their inception in the early 1990s.
Overall, this partnership enables the retailer to make data-driven decisions, improve supply chain efficiency and ultimately boost customer satisfaction, all in a secure and scalable cloud environment. The platform provides an intelligent, self-service data ecosystem that enhances data governance, quality and usability.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictiveanalytics that enable faster decision making and insights.
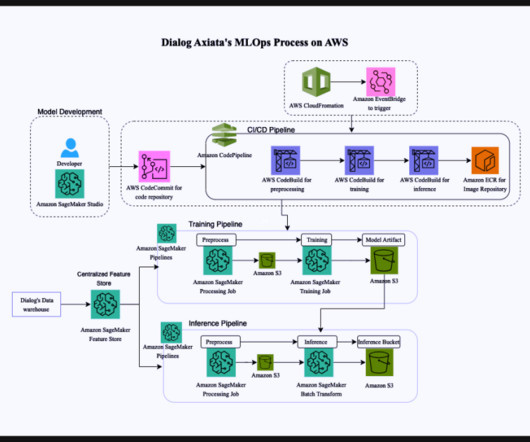
SageMaker Feature Store – By using a centralized repository for ML features, SageMaker Feature Store enhances data consumption and facilitates experimentation with validation data. Instead of directly ingesting data from the datawarehouse, the required features for training and inference steps are taken from the feature store.
Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent. 1 Watsonx.data offers built-in governance and automation to get to trusted insights within minutes, and integrations with existing databases and tools to simplify setup and user experience.
Using the right dataanalytics techniques can help in extracting meaningful insight, and using the same to formulate strategies. The analytics techniques like descriptive analytics, predictiveanalytics, diagnostic analytics and others find application in diverse industries, including retail, healthcare, finance, and marketing.
Snowflake’s built-for-the-cloud architecture is highly performant and designed to handle large volumes of data and data consumers. Because of its cloud architecture, users do not have to worry about the maintenance of the infrastructure and the database going down at an inopportune time.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
Summary: Oracle’s Exalytics, Exalogic, and Exadata transform enterprise IT with optimised analytics, middleware, and database systems. AI, hybrid cloud, and advanced analytics empower businesses to achieve operational excellence and drive digital transformation.
These tools enable organizations to convert raw data into actionable insights through various means such as reporting, analytics, data visualization, and performance management. Data Processing: Cleaning and organizing data for analysis. How Do I Choose the Right BI Tool for My Organization?
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling.
Snowflake’s data sharing enables AMCs to join internal data with third-party market data, as well as data that sits across applications and datawarehouses. Closing As the financial industry increasingly becomes more data-driven, the demand for futuristic, cloud-based solutions will continue to grow.
It utilises Amazon Web Services (AWS) as its main data lake, processing over 550 billion events daily—equivalent to approximately 1.3 petabytes of data. The architecture is divided into two main categories: data at rest and data in motion. What Technologies Does Netflix Use for Its Big Data Infrastructure?
Log Analysis These are well-suited for analysing log data from various sources, such as web servers, application logs, and sensor data, to gain insights into user behaviour and system performance. Integration with Existing Systems Integrating a Hadoop cluster with existing data processing systems and applications can be complex.
. “ This sounds great in theory, but how does it work in practice with customer data or something like a ‘composable CDP’? Well, implementing transitional modeling does require a shift in how we think about and work with customer data. It often involves specialized databases designed to handle this kind of atomic, temporal data.
Data Version Control for Data Lakes: Handling the Changes in Large Scale In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content