This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction SQL is easily one of the most important languages in the computer world. It serves as the primary means for communicating with relational databases, where most organizations store crucial data. However, writing optimized SQL queries can often […] The post How to Build a SQL Agent with CrewAI and Composio?
Introduction Data is the new oil in this century. The database is the major element of a data science project. To generate actionable insights, the database must be centralized and organized efficiently. So, we are […] The post How to Normalize Relational Databases With SQL Code?
Introduction Data from different sources are brought to a single location and then converted into a format that the datawarehouse can process and store. For example, a company stores data about its customers, products, employees, salaries, sales, and invoices. A boss may […].
Introduction The STAR schema is an efficient database design used in data warehousing and business intelligence. It organizes data into a central fact table linked to surrounding dimension tables. A major advantage of the STAR […] The post How to Optimize DataWarehouse with STAR Schema?
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The datasets range in size from a few 100 megabytes to a petabyte. […].
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
This results in the generation of so much data daily. This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases. Introduction In today’s world, technology has increased tremendously, and many people are using the internet.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Some NoSQL databases are also utilized as platforms for data lakes.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
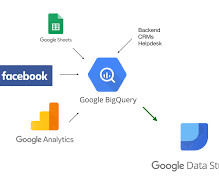
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-cloud datawarehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
Enter AnalyticsCreator AnalyticsCreator, a powerful tool for data management, brings a new level of efficiency and reliability to the CI/CD process. It offers full BI-Stack Automation, from source to datawarehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models.
. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century. Enterprises are focused on data stockpiling because more data leads to meticulous and calculated decision-making and opens more doors for business […].
It powers business decisions, drives AI models, and keeps databases running efficiently. But heres the problem: raw data is often messy. Without proper organization, databases become bloated, slow, and unreliable. Thats where data normalization comes in. Thats where data normalization comes in.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
A unified SQL query interface and portable runtime to locally materialize, accelerate, and query data tables sourced from any database, datawarehouse, or data lake. spiceai/spiceai
Introduction Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs. DWUs (DataWarehouse Units) can customize resources and optimize performance and costs.
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
The main solutions on the market are decentralized file storage networks (DSFN) like Filecoin and Arweave, and decentralized datawarehouses like Space and Time (SxT). Built to seamlessly integrate with existing enterprise systems, the datawarehouse lets businesses tap into blockchain data while publishing query results back on-chain.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Since databases store companies’ valuable digital assets and corporate secrets, they are on the receiving end of quite a few cyber-attack vectors these days. How can database activity monitoring (DAM) tools help avoid these threats? What are the ties between DAM and data loss prevention (DLP) systems? How do DAM solutions work?
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale.
However, the value of the data you gather is determined by the quality of the insights you derive from it and how successfully you can incorporate these insights into your company’s infrastructure and future business strategies. This helps companies extract the maximum amount of value from their data sets. 2 – Leverage caching.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. The following screenshot shows an example of the unified notebook page.
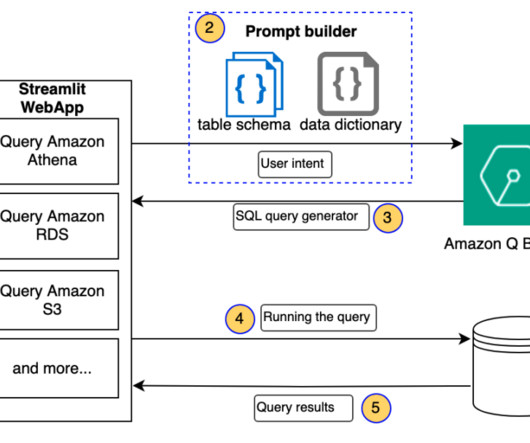
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQLDatabase connector and an Azure Data Lake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. March 30, 2021.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse. Database size limits of 10GB.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Natural language is ambiguous and imprecise, whereas data adheres to rigid schemas. For example, SQL queries can be complex and unintuitive for non-technical users. Handling complex queries involving multiple tables, joins, and aggregations makes it difficult to interpret user intent and translate it into correct SQL operations.
Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
Now they can access databases and datawarehouses, as well as unstructured business data, like emails, reports, charts, graphs, and images. Access all your data whether its stored in data lakes, datawarehouses, third-party or federated data sources. And now, it still is.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content