This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. You can try this platform that can handle all your data-related tasks without even paying the Microsoft Fabric price.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. With this Spark connector, you can easily ingest data to the feature group’s online and offline store from a Spark DataFrame.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling. A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle.
Its functionality comprises standing as an intermediary between raw data and visualizations and, thereby, acts as the place to facilitate ease of data exploration and analysis. It represents a centralized, shared datadefinition, allowing aggregations and other transformations. Select Dataset from the dropdown menu.
How you now anonymize Data more easily Photo by Dušan veverkolog on Unsplash Google has just announced the public preview of BigQuery differential privacy with SQL building blocks. You can use these functions to anonymize their data.
Another unexpected challenge was the introduction of Spark as a processing framework for big data. It gained rapid popularity given its support for data transformations, streaming and SQL. But it never co-existed amicably within existing data lake environments. Comprehensive data security and data governance (i.e.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines. The following figure shows schema definition and model which reference it.
This allows data that exists in cloud object storage to be easily combined with existing datawarehousedata without data movement. The advantage to NPS clients is that they can store infrequently used data in a cost-effective manner without having to move that data into a physical datawarehouse table.
However, with the evolution of the internet, the definition of transaction has broadened to include all types of digital interactions and engagements between a business and its customers. The core definition of transactions in the context of OLTP systems remains primarily focused on economic or financial activities.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Snowflake Cortex stood out as the ideal choice for powering the model due to its direct access to data, intuitive functionality, and exceptional performance in handling SQL tasks. Looking at the SQL code, it appears that CONTRACT_BREAK is hardcoded as a constant value ‘1’ in the final SELECT statement.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. Data Profiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape.
Security – Administers Snowflake’s security, such as data encryption. Sharing and Collaboration – Manages how data is shared between Snowflake accounts. SQL Optimization – Processes the user-entered SQL queries to be run in Snowflake. Transactions – Ensures SQL queries are ACID compliant.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
Consider factors such as data volume, query patterns, and hardware constraints. Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. Establish data governance policies and processes to ensure consistency in definitions, calculations, and data sources.
Using SQL-centric transformations to model data to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. Data Ingestion with Fivetran Fivetran is used to move your source(s) into a centralized space for storage.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. This ensures the maximum amount of Snowflake consumption possible.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. Retail Industry In a retail datawarehouse , hierarchies can be used to organise product categories. Avoid excessive levels that may slow down query performance.
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt.
This process introduces considerable time and effort into the overall data ingestion workflow, delaying the availability of data to end consumers. Fortunately, the client has opted for Snowflake Data Cloud as their target datawarehouse. Go back to the SQL worksheet and verify if the files exist.
Regarding retrieval, DBMS utilises query languages like SQL to retrieve information swiftly and accurately based on user requests. Moreover, DBMS systems manage data through functionalities such as indexing, which enhances retrieval speed by logically organising data. Best Data Engineering and SQL Books for Beginners.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services.
First, you generate predictions and you store them in a datawarehouse. So what that means is that when we write feature definitions, instead of writing them in Python, we write the feature for the online prediction process. So we write a SQLdefinition. So we need to access fresh data.
To create a Scheduled Query, the initial step is to ensure your SQL is accurately entered in the Query Editor. A user-defined function (UDF) lets the user create a function by using a SQL expression or JavaScript code. These functions can then be used in your SQL queries in BQ to simplify and optimize your analysis.
These range from data sources , including SaaS applications like Salesforce; ELT like Fivetran; cloud datawarehouses like Snowflake; and data science and BI tools like Tableau. This expansive map of tools constitutes today’s modern data stack. We are starting with personalized homepages.
First, you generate predictions and you store them in a datawarehouse. So what that means is that when we write feature definitions, instead of writing them in Python, we write the feature for the online prediction process. So we write a SQLdefinition. So we need to access fresh data.
First, you generate predictions and you store them in a datawarehouse. So what that means is that when we write feature definitions, instead of writing them in Python, we write the feature for the online prediction process. So we write a SQLdefinition. So we need to access fresh data.
Data fabric is now on the minds of most data management leaders. In our previous blog, Data Mesh vs. Data Fabric: A Love Story , we defined data fabric and outlined its uses and motivations. The data catalog is a foundational layer of the data fabric. ” 1.
Taking it one step further, if you don’t want your data traversing the public internet, you can implement one of the private connections available from the cloud provider your Snowflake account is created on, i.e., Azure Private Link, AWS Privatelink, or Google Cloud Service Private Connect. Snowflake has you covered with Cortex.
Overall, these powerful cloud-based tools provide a scalable and cost-effective solution for managing, processing, and analyzing large volumes of data from Google Analytics in Snowflake. Need help setting up a data ingestion pipeline? It provides a fully managed datawarehouse as a service.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes.
Now, a single customer might use multiple emails or phone numbers, but matching in this way provides a precise definition that could significantly reduce or even eliminate the risk of accidentally associating the actions of multiple customers with one identity.
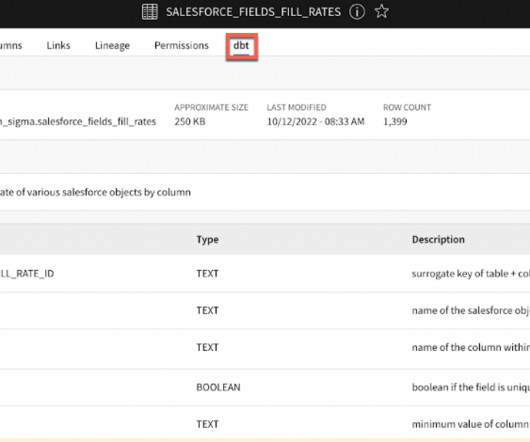
Sidebar Navigation: Provides a catalog sidebar for browsing resources by type, package, file tree, or database schema, reflecting the structure of both dbt projects and the data platform. Efficient Data Retrieval: Quick access to metric datasets from your data platform is made possible by MetricFlow’s optimized processes.
Data pipeline orchestration. Support for languages and SQL. Moving/integrating data in the cloud/data exploration and quality assessment. Similar to a datawarehouse schema, this prep tool automates the development of the recipe to match. It’s not a simple definition. Collaboration and governance.
dbt Labs is a robust platform that allows individuals comfortable with SQL to incorporate software engineering’s best practices into their data transformation pipelines. To do this, you’ll need to create a free dbt account , a Snowflake trial account (or another DataWarehouse), and a GitHub account.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content