This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
The platform helped the agency digitize and process forms, pictures, and other documents. The federal government agency Precise worked with needed to automate manual processes for document intake and image processing. For image processing, the agency does a lot of inspections and takes a lot of pictures.
Testing: Various methods are used to support or refute these hypotheses, incorporating both quantitative and qualitative data. Evaluation: Finally, researchers document their findings, including potential limitations and implications. Deduction: This step involves creating testable hypotheses derived from broader explanations.
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). Project documentation ¶ As data science codebases live longer, code is often refactored into a package.
When needed, the system can access an ODAP datawarehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. The central concept is the idea of a document.
Other uses may include: Maintenance checks Guides, resources, training and tutorials (all available in BigQuery documentation ) Employee efficiency reviews Machine learning Innovation advancements through the examination of trends. (1). Big data analytics advantages. What is Big Data?” What is Google BigQuery? References.
Do you have a data governance document? What data do you collect? Technical Questions Before Starting a Data Strategy. How and where is your current data stored? What is the current data infrastructure? Do you have a datawarehouse? Do you use any external data?
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
As a standalone product, this software helps professionals with rich sets of spreadsheets, charts and documents. Quip integration tool will allow teams to improve collaborations, export and import live data, enhanced visibility and outstanding device support. This tool will help you to sync and store data from multiple sources quickly.
How to build a chatbot that answers questions about documentation and cites its sources The tutorial was initially hosted via a live stream on our Learn AI Discord. Three 5-minute reads/videos to keep you learning 1.How
is not just for data scientists and developers — business users can also access it via an easy-to-use interface that responds to natural language prompts for different tasks. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs. Watsonx.ai
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract has a Tables feature within the AnalyzeDocument API that offers the ability to automatically extract tabular structures from any document.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse.
Examples of data sources and destinations include: Shopify Google Analytics Snowflake Data Cloud Oracle Salesforce Fivetran’s mission is to, “make access to data as easy as electricity” – so for the last 10 years, they have developed their platform into a leader in the cloud-based ELT market. What is Fivetran Used For?
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
You need to make sure that all departments are data-friendly and in sync with each other. Most will include documentation of data sources, the KPIs of the specific industry, the kind of reporting necessary, and whether or not the data flow will require automation. Set Up Data Integration. Develop a Strategy.
For our hypothetical car company, we will use Dataiku’s Answers application to create a personalized customer service chatbot that can pull data from warranty contracts, car spec manuals, and customer history to respond to inquiries. Dataiku and Snowflake: A Good Combo?
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
To start using OpenSearch for anomaly detection you first must index your data into OpenSearch , from there you can enable anomaly detection in OpenSearch Dashboards. To learn more, see the documentation. To learn more, see the documentation. To learn more, see the documentation.
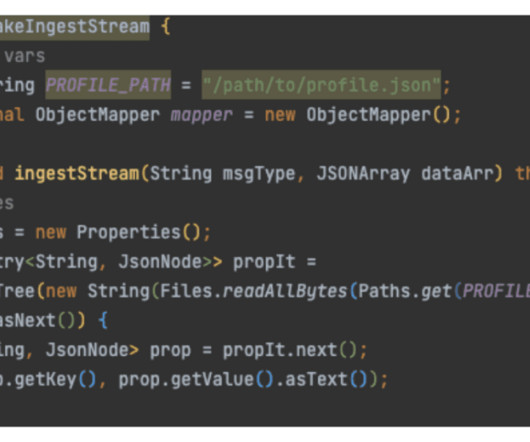
This SDK allows you to directly connect to your Snowflake DataWarehouse and create a mapping of values and rows that need to be inserted. Once this step is complete, you can then insert the data. So how does Snowflake do this? Snowflake provides a Streaming Ingest SDK that you can implement using Java.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Great Expectations GitHub | Website Great Expectations (GX) helps data teams build a shared understanding of their data through quality testing, documentation, and profiling. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. When documents are split into smaller chunks, search systems can find relevant sections more precisely and quickly.
By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake. With the amounts of data involved, this can be crucial to utilizing a data lake effectively. However, this can be time-consuming and prone to human error, leading to misinformation.
Volume – Companies gather data from different sources such as business transactions, social media, and other relevant data. Variety – It means all data can be presented in a variety of formats – from structured numeric data to the unstructured ones, which include text documents, audio, video, and email.
Like most Gen AI use cases, the first step to achieving customer service automation is to clean and centralize all information in a datawarehouse for your AI to work from. Document Search Everyone who’s ever read a product manual knows it can be notoriously complex, and finding the information you’re looking for is difficult.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
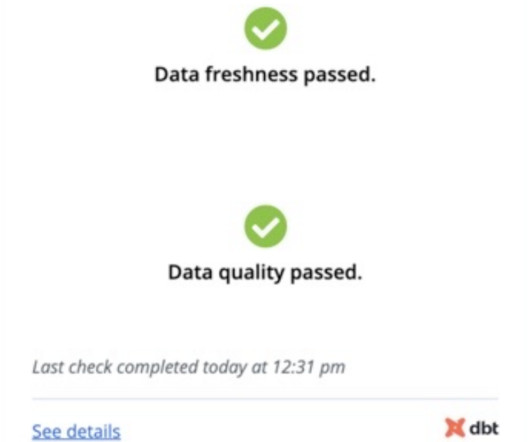
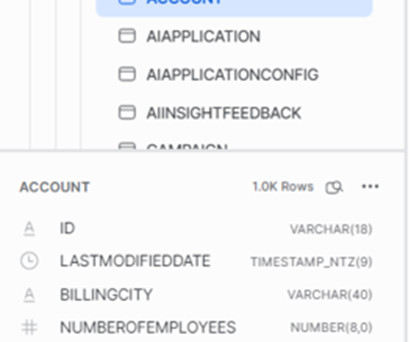
Hosted Doc Site for Documentation One of the most powerful features of dbt can be the documentation you generate. This documentation can give different users insight into where data came from, what the profile of the data is, what the SQL looked like, and the DAG to know where the data is being used.
“File-based storage of data is the norm even under more relational models. [In In the cloud], Graph databases, document stores, file stores, relational stores all now exist, each addressing different challenges.” In this way, the cloud has democratized access to some of the best outputs of big data.
In addition, well-known products boast a lot of implementations and use cases that are comprehensively reflected in the documentation. Another direction in the progress of database monitoring systems is the interoperability with so-called datawarehouses, which are increasingly popular among corporate customers.
How to Get Started with Matillion Data Productivity Cloud That looks unbelievable, but trust me, you can get started with Matillion Data Productivity Cloud from 0 to start your first job in around 5 minutes. Creating Your Account First things first, let’s create your Matillion account in order to deploy your Data Productivity Cloud.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. She is passionate about data-driven AI and the area of depth in machine learning.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. Warehouse for loading the data (start with XSMALL or SMALL warehouses). See the Salesforce documentation for more information. Click Next.
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud data lake or datawarehouse. File – Fivetran offers several options to sync files to your destination.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content