This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Top Big Data CRM Integration Tools in 2021: #1 MuleSoft: Mulesoft is a data integration platform owned by Salesforce to accelerate digital customer transformations. This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes.
Extraction, Transform, Load (ETL). The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud datawarehouse like Snowflake. Document business rules and assumptions directly within the workflow. Data tables used and their role in the workflow.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. How Much Does Fivetran Cost? The answer to that question is, it depends.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
To start using OpenSearch for anomaly detection you first must index your data into OpenSearch , from there you can enable anomaly detection in OpenSearch Dashboards. To learn more, see the documentation. To learn more, see the documentation. To learn more, see the documentation.
Typically, this data is scattered across Excel files on business users’ desktops. Typically, this data is scattered across Excel files on business users’ desktops. They usually operate outside any data governance structure; often, no documentation exists outside the user’s mind.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake. With the amounts of data involved, this can be crucial to utilizing a data lake effectively. However, this can be time-consuming and prone to human error, leading to misinformation.
As a result, Matillion is an excellent choice for businesses wishing to optimize their data operations in a scalable and user-friendly environment. Matillion’s Data Productivity Cloud is a pivotal tool for modern data teams, designed to accelerate data delivery and transform the ETL process. No problem.
How can an organization enable flexible digital modernization that brings together information from multiple data sources, while still maintaining trust in the integrity of that data? To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions. Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The stored data is visualized in a BI dashboard using QuickSight.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. This documentation is invaluable for future reference and modifications. Simplify hierarchies where possible and provide clear documentation to help users understand the structure.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. The Open Connector Framework SDK enables engineers to custom-build data source connectors , which are indexed by Alation. Open Data Quality Initiative.
It wouldn’t be until 2013 that the topic of data lineage would surface again – this time while working on a datawarehouse project. Datawarehouses obfuscate data’s origin In 2013, I was a Business Intelligence Engineer at a financial services company.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
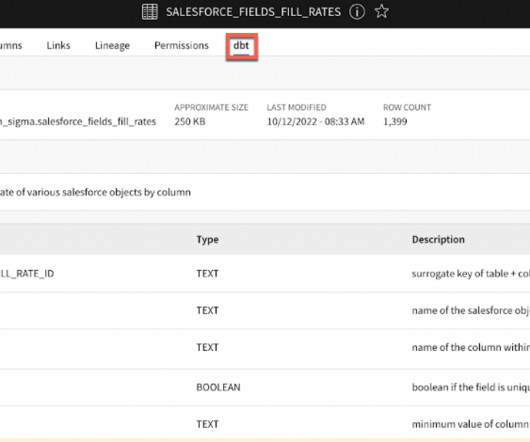
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the cloud datawarehouse. This graph is an example of one analysis, documented in our internal catalog.
Data Training and Awareness Invest in training for your staff. Ensure that everyone handling data understands its importance and the role it plays in maintaining data quality. DataDocumentation Comprehensive datadocumentation is essential. Identify anomalies, inconsistencies, and missing values.
Documentation: Keep detailed documentation of the deployed model, including its architecture, training data, and performance metrics, so that it can be understood and managed effectively. If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS.
With the “Data Productivity Cloud” launch, Matillion has achieved a balance of simplifying source control, collaboration, and dataops by elevating Git integration to a “first-class citizen” within the framework. In Matillion ETL, the Git integration enables an organization to connect to any Git offering (e.g.,
Consider factors such as data volume, query patterns, and hardware constraints. Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. Use indexing and partitioning strategies to improve query performance.
A common problem solved by phData is the migration from an existing data platform to the Snowflake Data Cloud , in the best possible manner. Data flows from the current data platform to the destination. Either way, it’s important to understand what data is transformed, and how so. Ready to Get Started?
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation.
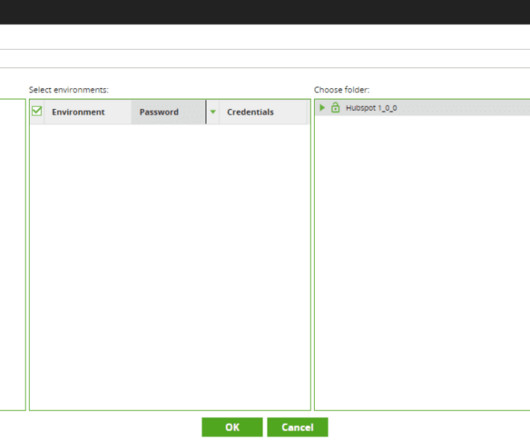
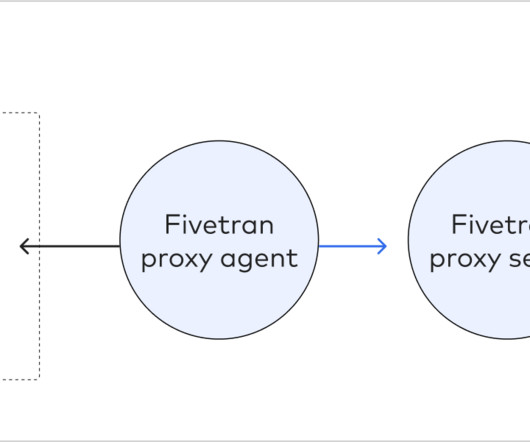
The on-premise agent is responsible for sending data to Fivetran, which is then processed and loaded into the destination. You can find more information about them in their official documentation. Extra Points DataWarehouses as Source Currently, it is in Beta, but you can use BigQuery and Snowflake as data sources in Fivetran.
As data types and applications evolve, you might need specialized NoSQL databases to handle diverse data structures and specific application requirements. With an open data lakehouse, you can access a single copy of data wherever your data resides.
Data Vault - Data Lifecycle Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement. Data Acquisition: Extracting data from source systems and making it accessible.
Gain hands-on experience with data integration: Learn about data integration techniques to combine data from various sources, such as databases, spreadsheets, and APIs. BI Developer Skills Required To excel in this role, BI Developers need to possess a range of technical and soft skills.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. Data to explore: Outline the tables or datasets you’re exploring/analyzing and reference their sources or link their data catalog entries. documentation.
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
Using SQL-centric transformations to model data to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. Data Ingestion with Fivetran Fivetran is used to move your source(s) into a centralized space for storage.
KNIME and Power BI: The Power of Integration The data analytics process invariably involves a crucial phase: data preparation. This phase demands meticulous customization to optimize data for analysis. Consider a scenario: a data repository residing within a cloud-based datawarehouse. Execute the workflow.
Check the API documentation to discover what parameters must be passed into the API call and configured in this wizard. Check out the API documentation for our sample. Aside from that, you will choose where the data will be stored in your datawarehouse and the staging location.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content