This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
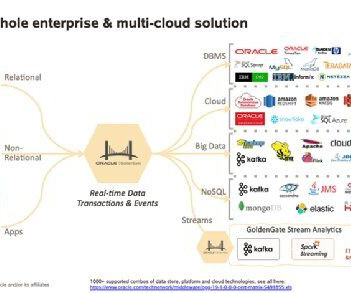
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
What is the current data infrastructure? Do you have a datawarehouse? Do you use any external data? How long is data stored? What data tools are available? This list is available as a free One-Page Checklist , go download it at Questions to Ask before Building a Data Strategy.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse.
Summary: Online Analytical Processing (OLAP) systems in DataWarehouse enable complex Data Analysis by organizing information into multidimensional structures. Key characteristics include fast query performance, interactive analysis, hierarchical data organization, and support for multiple users.
These insights can be ad-hoc or can inform additions to your data processing pipeline. You may just need to quickly ask a question of a csv file stored in your data lake without worrying about moving the file to an enterprise datawarehouse.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. Enter a stack name, such as Demo-Redshift.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. The generated images can also be downloaded as PNG or JPEG files.
Take advantage of the open source and open data formats of Delta Lake to make data accessible to everyone . Work with any datawarehouse or data platform that supports Parquet. Delta Sharing enables secure data sharing with open, secure access and seamless sharing between data consumers, providers, and sharers. .
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. If it’s not done right away, then later.
Create an Amazon Redshift connection Amazon Redshift is a fully managed, petabyte-scale datawarehouse service that simplifies and reduces the cost of analyzing all your data using standard SQL. If you specify model_id=defog/sqlcoder-7b-2 , DJL Serving will attempt to directly download this model from the Hugging Face Hub.
Data curation is important in today’s world of data sharing and self-service analytics, but I think it is a frequently misused term. When speaking and consulting, I often hear people refer to data in their data lakes and datawarehouses as curated data, believing that it is curated because it is stored as shareable data.
Using Amazon Redshift ML for anomaly detection Amazon Redshift ML makes it easy to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift datawarehouses. How can I export anomalies data before deleting the resources?
From this stage, GoldenGate runs a merge statement to replicate data into Snowflake. Once an extract and distribution path is configured, follow these steps to ingest data into Snowflake. Download the Snowflake-JDBC Driver JAR File That can be done here. TODO:Set the classpath to include Snowflake JDBC driver. gg.classpath=./snowflake-jdbc-3.13.7.jar
These insights can be ad-hoc or can inform additions to your data processing pipeline. You may just need to quickly ask a question of a csv file stored in your data lake without worrying about moving the file to an enterprise datawarehouse.
On the other hand, OLAP systems use a multidimensional database, which is created from multiple relational databases and enables complex queries involving multiple data facts from current and historical data. An OLAP database may also be organized as a datawarehouse.
Many ML systems benefit from having the feature store as their data platform, including: Interactive ML systems receive a user request and respond with a prediction. An interactive ML system either downloads a model and calls it directly or calls a model hosted in a model-serving infrastructure.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift.
Focus Area ETL helps to transform the raw data into a structured format that can be easily available for data scientists to create models and interpret for any data-driven decision. A data pipeline is created with the focus of transferring data from a variety of sources into a datawarehouse.
Typically, this data is scattered across Excel files on business users’ desktops. Multi-person collaboration is difficult because users have to download and then upload the file every time changes are made. Upload via the Snowflake UI Snowflake allows users to load data directly from the web UI.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud datawarehouse or data lake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Download Best Practice 1.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Token Based Splitting We will use BERT Tokenizer from Hugging Face as an open-source tokenizer for token-based splitting.
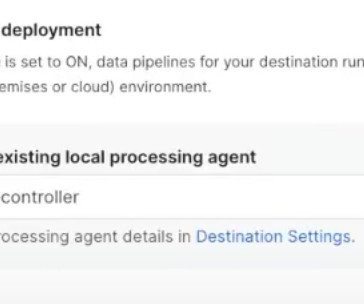
As data and AI continue to dominate today’s marketplace, the ability to securely and accurately process and centralize that data is crucial to an organization’s long-term success. With the hybrid deployment architecture, a containerized agent is downloaded onto the network resources where the pipeline will run.
Take advantage of the open source and open data formats of Delta Lake to make data accessible to everyone . Work with any datawarehouse or data platform that supports Parquet. Delta Sharing enables secure data sharing with open, secure access and seamless sharing between data consumers, providers, and sharers. .
KNIME and Power BI: The Power of Integration The data analytics process invariably involves a crucial phase: data preparation. This phase demands meticulous customization to optimize data for analysis. Consider a scenario: a data repository residing within a cloud-based datawarehouse.
The ability to quickly drill down to relevant data and make bulk changes saves stewards the time and headache of doing it manually, one by one. For example, a data steward can filter all data by ‘“endorsed data’” in a Snowflake datawarehouse, tagged with ‘bank account’. Download the solution brief.
The Snowflake Data Cloud offers a scalable, cloud-native datawarehouse that provides the flexibility, performance, and ease of use needed to meet the demands of modern businesses. While Snowflake offers unparalleled capabilities for data processing and analytics, it’s essential to keep a watchful eye on your costs.
The 21st Century equivalent should be called the “query and download book.” When an open source notebook is deployed on a local machine, and the data required are located across a network, it can take (literally) hours for a complex query with large datasets to resolve and be available on the local machine. Data Security.
This process introduces considerable time and effort into the overall data ingestion workflow, delaying the availability of data to end consumers. Fortunately, the client has opted for Snowflake Data Cloud as their target datawarehouse. The Snowflake account is set up with a demo database and schema to load data.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. Curious to learn how the data catalog can power your data strategy?
Dataset Evaluation—Choosing the right datasets depends on ability to evaluate their suitability for an analysis use case without needing to download or acquire data first. Ranking of search results by relevance and by frequency of use are particularly useful and beneficial features.
If you’re interested in exploring further best practices for Snowflake and CI/CD, we recommend downloading our comprehensive Getting Started with Snowflake Guide. This guide offers actionable steps that will assist you in maximizing the benefits of the Snowflake Data Cloud for your organization.
Download and extract the Apache Hadoop distribution on all nodes. Cost-effectiveness Hadoop clusters use commodity hardware, making them more cost-effective compared to traditional data processing systems. The open-source software is also free to download and use.
Just click this button and fill out the form to download it. One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). Want to Save This Guide for Later? No problem! Table of Contents Why Discuss Snowflake & Power BI?
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a datawarehouse or a data lake. Credits can be purchased for 14 cents per minute.
By then I had converted that small Heights data dictionary to the Snowflake sources. We did have an existing datawarehouse solution, but it was so rarely used by outside teams, and I can’t even remember the name. But everything CURO was still on SQL. Will: CURO was primarily a Microsoft SQL house and still is in some ways.
It is a small text file with md5 hash that points to the actual data file in remote storage. When we download a Git repository, we also get the.dvc files which we use to download the data associated with them. Also, this file is meant to be stored with code in GitHub.
Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Data storage : Store the data in a Snowflake datawarehouse by creating a data pipe between AWS and Snowflake.
ETL usually stands for “Extract, Transform and Load,” and it refers to a process in data warehousing. Sourcing the data In our case, the data was provided by our client, which was a product-based organization. So coming to how we addressed these, it was a combination of the above approaches and a few more.
Currently, organizations often create custom solutions to connect these systems, but they want a more unified approach that them to choose the best tools while providing a streamlined experience for their data teams. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both datawarehouses and data lakes.
Understanding Matillion and Snowflake, the Python Component, and Why it is Used Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP and supports multiple cloud datawarehouses. The procedure loads a file into the database from S3, a copy of the processed data in the Snowflake.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Many are turning to Snowflake for its modern cloud datawarehouse, which offers flexibility, cost savings, and governance capabilities across an entire data ecosystem. Realize the Benefits of Snowflake Faster by Identifying & Moving Important Data. Get the latest data cataloging news and trends in your inbox.
Column Store Index This index used when there is a column-store data storage system. Basically, it is used for retrieving and querying large datawarehouse tables. This index uses column-store data storage rather than row-oriented data storage. I have used a table with 5,00,000 rows data of people.
To democratize data, organizations can identify data sources and create a centralized data repository This might involve creating user-friendly data visualization tools, offering training on data analysis and visualization, or creating data portals that allow users to easily access and downloaddata.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content