This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a datawarehouse.
Introduction on Snowflake Architecture This article helps to focus on an in-depth understanding of Snowflake architecture, how it stores and manages data, as well as its conceptual fragmentation concepts. The post Snowflake Architecture & Key Concepts for DataWarehouse appeared first on Analytics Vidhya.
Introduction Organizations with a separate transactional database and datawarehouse typically have many data engineering activities. For example, they extract, transform and load data from various sources into their datawarehouse.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the DataWarehouse system. ETL stands for Extract, Transform, and Load.
ELT helps to streamline the process of modern data warehousing and managing a business’ data. In this post, we’ll discuss some of the best ELT tools to help you clean and transfer important data to your datawarehouse.
Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems.
This article was published as a part of the Data Science Blogathon. Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. Many companies, organizations, and industries store the data and use it as per the requirement.
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
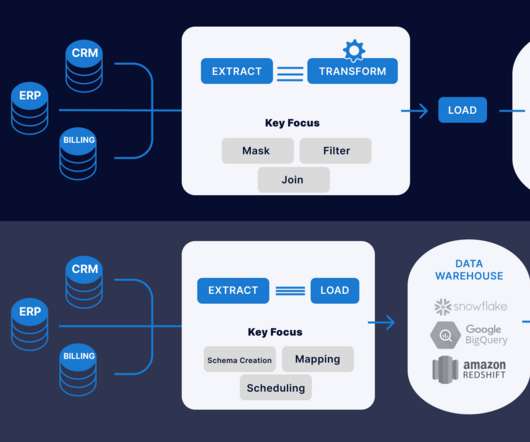
Extract-Transform-Load vs Extract-Load-Transform: Data integration methods used to transfer data from one source to a datawarehouse. Their aims are similar, but see how they differ.
This article was published as a part of the Data Science Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […].
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
Data lakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and Data Lakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources. Key Differences.
In this contributed article, Adrian Kunzle, Chief Technology Officer at Own Company, discusses strategies around using historical data to understand their businesses better and fill gaps are often overlooked.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Enter AnalyticsCreator AnalyticsCreator, a powerful tool for data management, brings a new level of efficiency and reliability to the CI/CD process. It offers full BI-Stack Automation, from source to datawarehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models.
Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Want to create a robust datawarehouse architecture for your business? The sheer volume of data that companies are now gathering is incredible, and understanding how best to store and use this information to extract top performance can be incredibly overwhelming.
This article was published as a part of the Data Science Blogathon. Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. Many companies, organizations, and industries store the data and use it as per the requirement.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
ETL (Extract, Transform, Load) is a crucial process in the world of data analytics and business intelligence. In this article, we will explore the significance of ETL and how it plays a vital role in enabling effective decision making within businesses. What is ETL? Let’s break down each step: 1.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
M aintaining the security and governance of data within a datawarehouse is of utmost importance. Data Security: A Multi-layered Approach In data warehousing, data security is not a single barrier but a well-constructed series of layers, each contributing to protecting valuable information.
Data activation is a new and exciting way that businesses can think of their data. It’s more than just data that provides the information necessary to make wise, data-driven decisions. It’s more than just allowing access to datawarehouses that were becoming dangerously close to data silos.
Data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations who seek to empower more and better data-driven decisions and actions throughout their enterprises. These groups want to expand their user base for data discovery, BI, and analytics so that their business […].
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
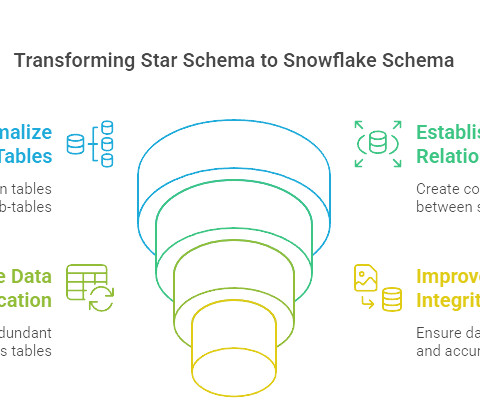
Summary: The snowflake schema in datawarehouse organizes data into normalized, hierarchical dimension tables to reduce redundancy and enhance integrity. This approach is particularly valuable for organizations aiming to manage highly structured, multi-level data with minimal redundancy and greater consistency.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
A metadata-driven datawarehouse (MDW) offers a modern approach that is designed to make EDW development much more simplified and faster. It makes use of metadata (data about your data) as its foundation and combines data modeling and ETL functionalities to build datawarehouses.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content