This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
To further explore this topic, I am surveying real-world serverless, multi-tenant data architectures to understand how different types of systems, such as OLTP databases, real-time OLAP, cloud datawarehouses, event streaming systems, and more, implement serverless MT.
M aintaining the security and governance of data within a datawarehouse is of utmost importance. Data Security: A Multi-layered Approach In data warehousing, data security is not a single barrier but a well-constructed series of layers, each contributing to protecting valuable information.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
Hosted at one of Mindspace’s coworking locations, the event was a convergence of insightful talks and professional networking. Mindspace , a global coworking and flexible office provider with over 45 locations worldwide, including 13 in Germany, offered a conducive environment for this knowledge-sharing event.
The new VistaPrint personalized product recommendation system Figure 1 As seen in Figure 1, the steps in how VistaPrint provides personalized product recommendations with their new cloud-native architecture are: Aggregate historical data in a datawarehouse. Transform the data to create Amazon Personalize training data.
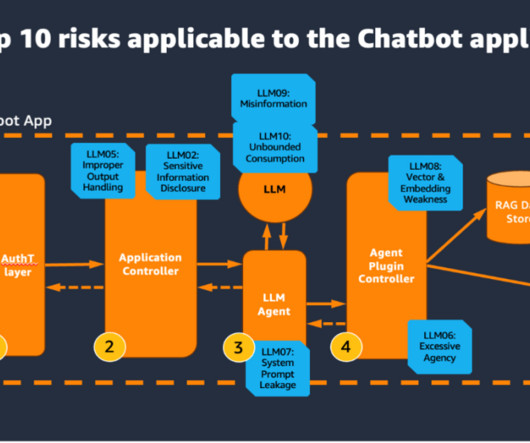
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
The goal of digital transformation remains the same as ever – to become more data-driven. We have learned how to gain a competitive advantage by capturing business events in data. Events are data snap-shots of complex activity sourced from the web, customer systems, ERP transactions, social media, […].
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
TR has a wealth of data that could be used for personalization that has been collected from customer interactions and stored within a centralized datawarehouse. The user interactions data from various sources is persisted in their datawarehouse. The following diagram illustrates the ML training pipeline.
And, for the tenth anniversary of ODSC East , we are pulling out all of the stops with new tracks, new events, and even a new location. New Networking Events At ODSC West this past November, we had the privilege of hosting a highly successful Hackathon with NVIDIA. So what can you expect from ODSC East 2025, May 1315 in Boston?
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
Connect and learn at the developer event of year, TrailblazerDX on March 7-8, 2023. Members of the community can connect with DataDev ambassadors through the DataDev Slack instance and User Groups, but also at any of our DataDev events. She is also one of the organizers of the Data + Women Netherlands community. "I
In this episode, James Serra, author of “Deciphering Data Architectures: Choosing Between a Modern DataWarehouse, Data Fabric, Data Lakehouse, and Data Mesh” joins us to discuss his book and dive into the current state and possible future of data architectures. Interested in attending an ODSC event?
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
Some solutions provide read and write access to any type of source and information, advanced integration, security capabilities and metadata management that help achieve virtual and high-performance Data Services in real-time, cache or batch mode. How does Data Virtualization complement Data Warehousing and SOA Architectures?
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
A Composable CDP is a new technical architecture for how businesses manage and activate their customer data for marketing programs. The Composable CDP transforms an existing cloud datawarehouse, like the Snowflake Data Cloud , into the central repository of customer data in a company. How was phData Selected?
We are also building models trained on different types of business data, including code, time-series data, tabular data, geospatial data and IT eventsdata. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs.
Every modern enterprise has a unique set of business data collected as part of their sales, operations, and management processes. Registration is free for both events. 16 th and on-demand Visit datarobot.com/partners/technology-partners/sap DataRobot Launch Event From Vision to Value. Tune in to learn more.
Lambda enables serverless, event-driven data processing tasks, allowing for real-time transformations and calculations as data arrives. Step Functions complements this by orchestrating complex workflows, coordinating multiple Lambda functions, and managing error handling for sophisticated data processing pipelines.
Connect and learn at the developer event of year, TrailblazerDX on March 7-8, 2023. Members of the community can connect with DataDev ambassadors through the DataDev Slack instance and User Groups, but also at any of our DataDev events. She is also one of the organizers of the Data + Women Netherlands community. "I
Complex mathematical algorithms are used to segment data and estimate the likelihood of subsequent events. Every Data Scientist needs to know Data Mining as well, but about this moment we will talk a bit later. Where to Use Data Science? Data Mining is an important research process. Practical experience.
Upcoming Community Events The Learn […] The steps involved include obtaining a list of texts to search, embedding the archive of questions, converting the embeddings into indexes, and others. Enjoy these papers and news summaries? Get a daily recap in your inbox! The Learn AI Together Community section!
Note: Recommended to only edit the configuration marked as TODO gg.target=snowflake #The Snowflake Event Handler #TODO: Edit JDBC ConnectionUrl gg.eventhandler.snowflake.connectionURL=jdbc:snowflake://.snowflakecomputing.com/?warehouse= The S3 Event Handler #TODO: Edit the AWS region #gg.eventhandler.s3.region= snowflakecomputing.com/?warehouse=
Thus, DB2 PureScale on AWS equips this insurance company to innovate and make data-driven decisions rapidly, maintaining a competitive edge in a saturated market. The platform provides an intelligent, self-service data ecosystem that enhances data governance, quality and usability.
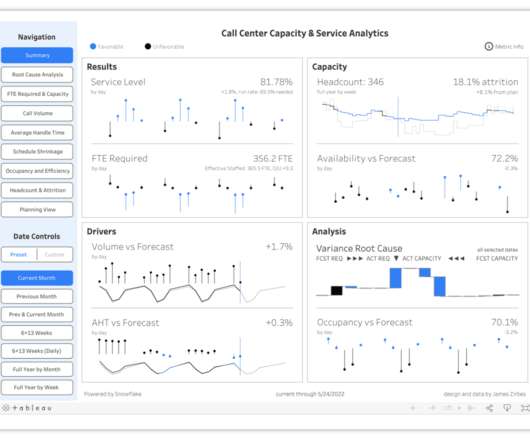
More and more businesses are looking to better leverage their outsourced call center data to make more data-driven decisions. To do this on your own, you would need to create a datawarehouse, optimize the reporting performance, and very clearly visualize the data. How Does Snowflake Help with Call Centers?
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a datawarehouse or a database. In the extraction phase, the data is collected from various sources and brought into a staging area.
Watsonx.data on AWS: Imagine having the power of data at your fingertips. watsonx.data is a software-as-a-service (SaaS) offering that revolutionizes data management. Join IBM and AWS experts at IBM TechXchange Conference 2023 , the premier learning event for developers, engineers, and IT practitioners.
We all missed meeting in-person this year—that real-life connection is hard to replace for relationship-building, fast decision making, and having a little social time together—but heard great feedback across all three Theaters about this year’s digital event. Despite all the headwinds, we are persisting and growing together.
This SDK allows you to directly connect to your Snowflake DataWarehouse and create a mapping of values and rows that need to be inserted. Once this step is complete, you can then insert the data. First, the best use case for Snowflake’s Streaming API is any piece of streaming or messaging data.
10 Panoply: In the world of CRM technology, Panoply is a datawarehouse build that automates data collection, query optimization and storage management. This tool will help you to sync and store data from multiple sources quickly. With this tool, data transfer is faster and dynamic.
On the one hand, the use of agents allows you to actively monitor and respond to events. A promising trend is the refinement of these systems’ UBA functionality through machine learning methods that help analyze chains of events, establish baseline activity patterns, and find deviations from normal user behavior.
They are working through organizational design challenges while also establishing foundational data management capabilities like metadata management and data governance that will allow them to offer trusted data to the business in a timely and efficient manner for analytics and AI.”
What is an online transaction processing database: Indexed data sets are used for rapid querying in OLTP systems Regular & incremental backups for data safety Frequent backups are necessary to ensure that data is protected in the event of a system failure or other issue.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Batch-processing systems that process data rows in batch (mainly via SQL ). Examples include real-time and datawarehouse systems that power Meta’s AI and analytics workloads. Data annotation can be done at various levels of granularity, including table, column, row, or potentially even cell.
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data. Event Tracking : Capturing behavioral events such as page views, add-to-cart, signup, purchase, subscription, etc.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
For our joint solution with Snowflake, this means that code-first users can use DataRobot’s hosted Notebooks as the interface and Snowpark processes the data directly in the datawarehouse. launch event on March 16th. Register here to be part of this virtual event.
In this blog, we’ll explain the best ways to utilize pharmaceutical supply chain data, what insights can be derived from it, and why Snowflake AI Data Cloud is the best cloud-based datawarehouse to land all your data.
Must Read Blogs: Exploring the Power of DataWarehouse Functionality. Data Lakes Vs. DataWarehouse: Its significance and relevance in the data world. Exploring Differences: Database vs DataWarehouse. It is commonly used in datawarehouses for business analytics and reporting.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































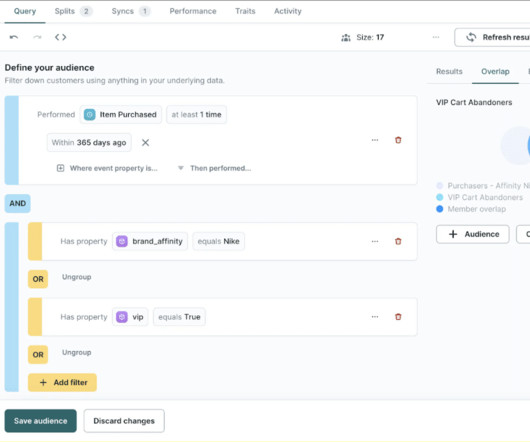










Let's personalize your content