This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
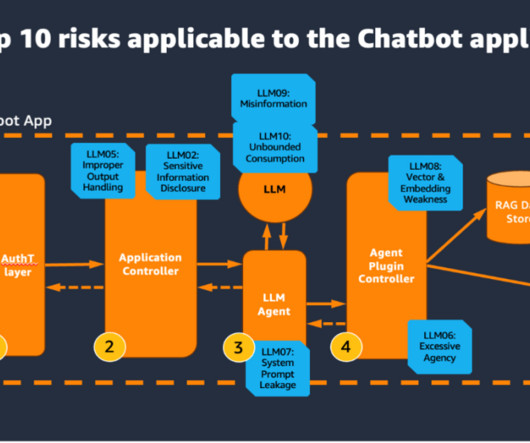
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Dabei darf gerne in Erinnerung gerufen werden, dass Process Mining im Kern eine Graphenanalyse ist, die ein Event Log in Graphen umwandelt, Aktivitäten (Events) stellen dabei die Knoten und die Prozesszeiten die Kanten dar, zumindest ist das grundsätzlich so. Es handelt sich dabei also um eine Analysemethodik und nicht um ein Tool.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. Flexible compute capacity One of the key advantages of Microsoft Fabric is its ability to optimize compute capacity across different workloads.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
We all missed meeting in-person this year—that real-life connection is hard to replace for relationship-building, fast decision making, and having a little social time together—but heard great feedback across all three Theaters about this year’s digital event. Despite all the headwinds, we are persisting and growing together.
. #10 Panoply: In the world of CRM technology, Panoply is a datawarehouse build that automates data collection, query optimization and storage management. This tool will help you to sync and store data from multiple sources quickly. With this tool, data transfer is faster and dynamic.
Policy Zones has been built into different Meta systems, including: Function-based systems that load, process, and propagate data through stacks of function calls in different programming languages. Batch-processing systems that process data rows in batch (mainly via SQL ). When data flows across different systems (e.g.,
On the one hand, the use of agents allows you to actively monitor and respond to events. A promising trend is the refinement of these systems’ UBA functionality through machine learning methods that help analyze chains of events, establish baseline activity patterns, and find deviations from normal user behavior.
They are also designed to handle concurrent access by multiple users and applications, while ensuring data integrity and transactional consistency. Examples of OLTP databases include Oracle Database, Microsoft SQL Server, and MySQL. An OLAP database may also be organized as a datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
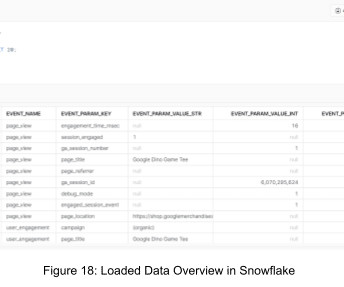
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw eventdata from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. This should return the records successfully for further data processing and analysis.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
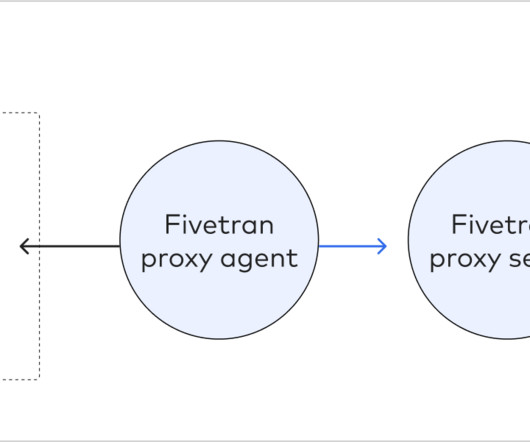
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. The most common example of such databases is where events are tracked.
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Replicate can interact with a wide variety of databases, datawarehouses, and data lakes (on-premise or based in the cloud). It is also a helpful tool for learning a new SQL dialect.
We all missed meeting in-person this year—that real-life connection is hard to replace for relationship-building, fast decision making, and having a little social time together—but heard great feedback across all three Theaters about this year’s digital event. Despite all the headwinds, we are persisting and growing together.
The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation.
These tables are called “factless fact tables” or “junction tables” They are used for modelling many-to-many relationships or for capturing timestamps of events. Dealing with Sparse Data In some cases, fact tables may contain a large number of null values due to missing data.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
Understanding the differences between SQL and NoSQL databases is crucial for students. Data Warehousing Solutions Tools like Amazon Redshift, Google BigQuery, and Snowflake enable organisations to store and analyse large volumes of data efficiently. Once data is collected, it needs to be stored efficiently.
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
This evolved into the phData Toolkit , a collection of high-quality data applications to help you migrate, validate, optimize, and secure your data. Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster.
They may also be involved in data modeling and database design. BI developer: A BI developer is responsible for designing and implementing BI solutions, including datawarehouses, ETL processes, and reports. They may also be involved in data integration and data quality assurance.
They may also be involved in data modeling and database design. BI developer: A BI developer is responsible for designing and implementing BI solutions, including datawarehouses, ETL processes, and reports. They may also be involved in data integration and data quality assurance.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. But what does this mean from a practitioner perspective?
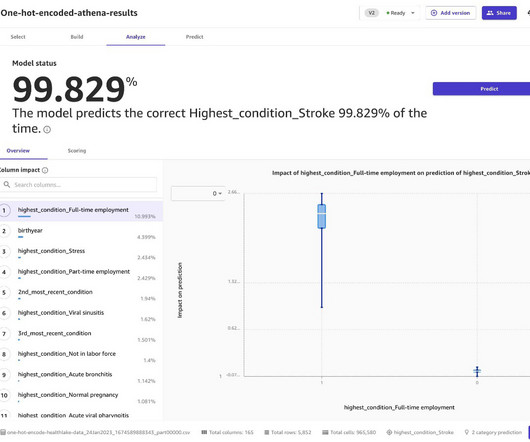
Query the data using Athena By running Athena SQL queries directly on Amazon HealthLake, we are able to select only those fields that are not personally identifying; for example, not selecting name and patient ID, and reducing birthdate to birth year. In this post, we used Amazon S3 as the input data source for SageMaker Canvas.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data.
Fail Safe doesn’t allow you to query the data within it; it is simply there to protect your data from catastrophic failure. The Snowflake team can use Fail Safe to restore your data in the event of an extreme operational failure, giving you even more peace of mind. Snowflake has you covered with Cortex.
However, a master’s degree or specialised Data Science or Machine Learning courses can give you a competitive edge, offering advanced knowledge and practical experience. Essential Technical Skills Technical proficiency is at the heart of an Azure Data Scientist’s role.
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content