This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Apache Hive is a datawarehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Hadoop systems and data lakes are frequently mentioned together.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. By harnessing the power of Big Data tools, organisations can transform raw data into actionable insights that foster innovation and competitive advantage.
While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […]. The post Step-by-Step Roadmap to Become a Data Engineer in 2023 appeared first on Analytics Vidhya.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
The challenges of a monolithic data lake architecture Data lakes are, at a high level, single repositories of data at scale. Data may be stored in its raw original form or optimized into a different format suitable for consumption by specialized engines.
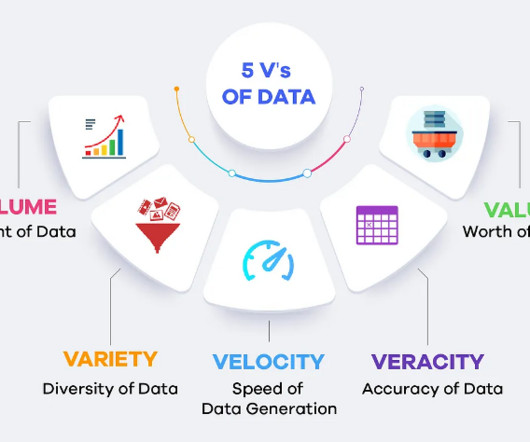
First, lets understand the basics of Big Data. Key Takeaways Understand the 5Vs of Big Data: Volume, Velocity, Variety, Veracity, Value. Familiarise yourself with essential tools like Hadoop and Spark. Practice coding skills in languages relevant to Big Data roles. What are the Main Components of Hadoop?
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
Consequently, here is an overview of the essential requirements that you need to have to get a job as an Azure Data Engineer. In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Having experience using at least one end-to-end Azure data lake project.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
The real advantage of big data lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Replicate can interact with a wide variety of databases, datawarehouses, and data lakes (on-premise or based in the cloud). It is also a helpful tool for learning a new SQL dialect.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Views Views in GCP BigQuery are virtual tables defined by SQL query that can display the results of a query or be used as the base for other queries.
Data from various sources, collected in different forms, require data entry and compilation. That can be made easier today with virtual datawarehouses that have a centralized platform where data from different sources can be stored. One challenge in applying data science is to identify pertinent business issues.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a datawarehouse or data lake. Data Lakes: These store raw, unprocessed data in its original format.
Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services. Database Extraction: Retrieval from structured databases using query languages like SQL. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data.
For instance, technical power users can explore the actual data through Compose , the intelligent SQL editor. Compose lets people explore the data forming their queries as they query. Those less familiar with SQL can search for technical terms using natural language. But what does integration look like in action?
In summary, Neptune is a simple and fast option for data versioning but it may not provide all data versioning features like DVC. Dolt also provides tools for querying and analyzing data, as well as for importing and exporting data from other sources. Then, using a separate branch, we can import files into the repository.
Other Apache Griffin is an open-source data quality solution for big data environments, particularly within the Hadoop and Spark ecosystems. It allows users to define, measure, monitor, and validate data quality. It is SQL-based and integrates well with modern datawarehouses.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content