This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A SageMaker domain. A QuickSight account (optional).
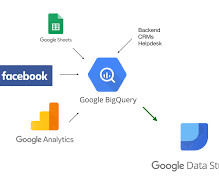
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a MachineLearning Model in BigQuery appeared first on Analytics Vidhya.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-cloud datawarehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
Data lakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and Data Lakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources. Key Differences.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Thats where data normalization comes in. Its a structured process that organizes data to reduce redundancy and improve efficiency. Whether you’re working with relational databases, datawarehouses , or machinelearning pipelines, normalization helps maintain clean, accurate, and optimized datasets.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, MachineLearning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
This article was published as a part of the Data Science Blogathon. Introduction Apache Hive is a datawarehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
Nely Mihaylova Connecting SQL to Python or R A developer who is fluent in a statistical language, like Python or R, may quickly and easily use the packages of language to construct machinelearning models on a massive dataset stored in a relational database management system.
However, an expert in the field says that scaling AI solutions to handle the massive volume of data and real-time demands of large platforms presents a complex set of architectural, data management, and ethical challenges. One of the main challenges when scaling up is the inference of models in real-time, Krotkikh said.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Data vault is not just a method; its an innovative approach to data modeling and integration tailored for modern datawarehouses. As businesses continue to evolve, the complexity of managing data efficiently has grown. As businesses continue to evolve, the complexity of managing data efficiently has grown.
This article was published as a part of the Data Science Blogathon. Machinelearning and artificial intelligence, which are at the top of the list of data science capabilities, aren’t just buzzwords; many companies are keen to implement them.
In this contributed article, Adrian Kunzle, Chief Technology Officer at Own Company, discusses strategies around using historical data to understand their businesses better and fill gaps are often overlooked.
Artificial intelligence (AI) technologies like machinelearning (ML) have changed how we handle and process data. Most companies utilize AI only for the tiniest fraction of their data because scaling AI is challenging. However, AI adoption isn’t simple.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. Cloud based solutions are the future of the data warehousing market.
Introduction The demand for data to feed machinelearning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Organisations must store data in a safe and secure place for which Databases and Datawarehouses are essential. You must be familiar with the terms, but Database and DataWarehouse have some significant differences while being equally crucial for businesses. What is DataWarehouse?
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
While data science and machinelearning are related, they are very different fields. In a nutshell, data science brings structure to big data while machinelearning focuses on learning from the data itself. What is data science? What is machinelearning?
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
Google introduces Cloud AI Platform Pipelines Google Cloud now provides a way to deploy repeatable machinelearning pipelines. Announcing Tensorflow Quantum Google Announces an open source library for prototyping quantum machinelearning models. This allows for monitoring, auditing, version tracking, and security.
After completion of the program, Precise achieved Advanced tier partner status and was selected by a federal government agency to create a machinelearning as a service (MLaaS) platform on AWS. This customer wanted to use machinelearning as a tool to digitize images and recognize handwriting.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. When needed, the system can access an ODAP datawarehouse to retrieve additional information.
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
Data is the foundation for machinelearning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. To learn more, refer to Import data from over 40 data sources for no-code machinelearning with Amazon SageMaker Canvas.
Snowflake got its start by bringing datawarehouse technology to the cloud, but now in 2023, like every other vendor, it finds artificial intelligence (AI) permeating nearly every discussion. In an exclusive interview with VentureBeat, Sunny Bedi, CIO and CDO at Snowflake, detailed the latest …
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
The decentralized datawarehouse startup Space and Time Labs Inc. said today it has integrated with OpenAI LP’s chatbot technology to enable developers, analysts and data engineers to query their
Azure Synapse provides a unified platform to ingest, explore, prepare, transform, manage, and serve data for BI (Business Intelligence) and machinelearning needs. DWUs (DataWarehouse Units) can customize resources and optimize performance and costs.
Enterprises often rely on datawarehouses and data lakes to handle big data for various purposes, from business intelligence to data science. A new approach, called a data lakehouse, aims to … But these architectures have limitations and tradeoffs that make them less than ideal for modern teams.
Machinelearning (ML) is only possible because of all the data we collect. However, with data coming from so many different sources, it doesn’t always come in a format that’s easy for ML models to understand. Why Prepare Data for MachineLearning Models? As the saying goes: “Garbage in, garbage out.”
The second challenge was that changes to the in-house developed system were time-consuming, because a high degree of machinelearning and ecommerce domain specialization was required to make modifications. Transform the data to create Amazon Personalize training data.
Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure Data Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. R Support for Azure MachineLearning. Azure Synapse. It’s true, I saw it happen this week.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machinelearning (ML) and analytics solutions in R at scale. Now let’s prepare a dataset that could be used for machinelearning. arrange(card_brand). Conclusion.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content