This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift datawarehouse.
Historically, datawarehouses have. Introduction Today, manufacturers’ field maintenance is often more reactive than proactive, which can lead to costly downtime and repairs.
He suggested that a Feature Store can help manage preprocessed data and facilitate cross-team usage, while a centralized DataWarehouse (DWH) domain can unify data preparation and migration. From the data side, this is resolved through centralized data preparation using a DWH (DataWarehouse) domain, Krotkikh said.
Thats where data normalization comes in. Its a structured process that organizes data to reduce redundancy and improve efficiency. Whether you’re working with relational databases, datawarehouses , or machine learning pipelines, normalization helps maintain clean, accurate, and optimized datasets. Simple, right?
The agency wanted to use AI [artificial intelligence] and ML to automate document digitization, and it also needed help understanding each document it digitizes, says Duan. The demand for modernization is growing, and Precise can help government agencies adopt AI/ML technologies.
Tom Hamilton Stubber The emergence of Quantum ML With the use of quantum computing, more advanced artificial intelligence and machine learning models might be created. Combining ML and quantum computing has the potential to greatly benefit enterprises by enabling them to take on problems that are currently insurmountable.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
Artificial intelligence (AI) technologies like machine learning (ML) have changed how we handle and process data. Most companies utilize AI only for the tiniest fraction of their data because scaling AI is challenging. However, AI adoption isn’t simple.
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
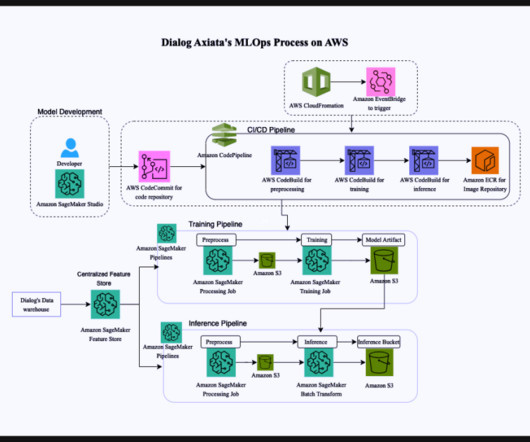
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. Amazon SageMaker Pipelines – Amazon SageMaker Pipelines is a CI/CD service for ML.
With our cleaned data from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science. This capability can reveal hidden patterns and optimize data for improved model performance. Dataiku and Snowflake: A Good Combo?
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose Continue. Review the input, and choose Create project.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
What is a Feature in ML? Machine learning (ML) models learn to make predictions based on past examples. For the vast majority of use cases, the data used by ML models can be visualized as a table where rows are examples and columns are attributes describing those examples. Data platform abstraction. Idempotency.
The Spectrum AI platform combines customer attitudes with customers’ operational data and uses machine learning (ML) to generate continuous insight on CX. OCX built Spectrum AI on AWS because AWS offered a wide range of tools, elastic computing, and an ML environment that would keep pace with evolving needs.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. When needed, the system can access an ODAP datawarehouse to retrieve additional information.
Leveraging DataRobot’s JDBC connectors, enterprise teams can work together to train ML models on their data residing in SAP HANA Cloud and SAP DataWarehouse Cloud, as well as have an option to enrich it with data from external data sources.
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures. Now, let’s chat about why datawarehouse optimization is a key value of a data lakehouse strategy. To effectively use raw data, it often needs to be curated within a datawarehouse.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs. But why now?
In fact, according in an IDC DataSphere study, IDC estimated that 10,628 exabytes (EB) of data was determined to be useful if analyzed, while only 5,063 exabytes (EB) of data (47.6%) was analyzed in 2022.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst.
Modern DataWarehouses like Snowflake are changing how we load and transform data in our warehouse with no extra tooling or external… Continue reading on MLearning.ai »
AI-enabled executives: how ChatGPT will sharpen strategic thinking The article discusses how ChatGPT can enhance strategic thinking and decision-making capabilities, such as anticipating and planning for the future, thinking critically and creatively about complex problems, and making effective decisions in uncertain situations.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). The development and use of these models explain the enormous amount of recent AI breakthroughs.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Leverage the Power of MongoDB and Snowflake to Create a DataWarehouse built for Data Science and Analytics Workflows. Continue reading on MLearning.ai »
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
In this post, we describe how Nielsen Sports modernized a system running thousands of different machine learning (ML) models in production by using Amazon SageMaker multi-model endpoints (MMEs) and reduced operational and financial cost by 75%. The analyst is given direct access to the raw data or through our datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content