This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift datawarehouse.
Thats where data normalization comes in. Its a structured process that organizes data to reduce redundancy and improve efficiency. Whether you’re working with relational databases, datawarehouses , or machine learning pipelines, normalization helps maintain clean, accurate, and optimized datasets. Simple, right?
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
With our cleaned data from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science. This capability can reveal hidden patterns and optimize data for improved model performance. Dataiku and Snowflake: A Good Combo?
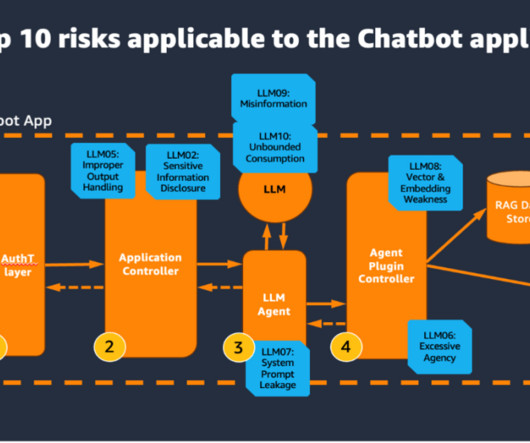
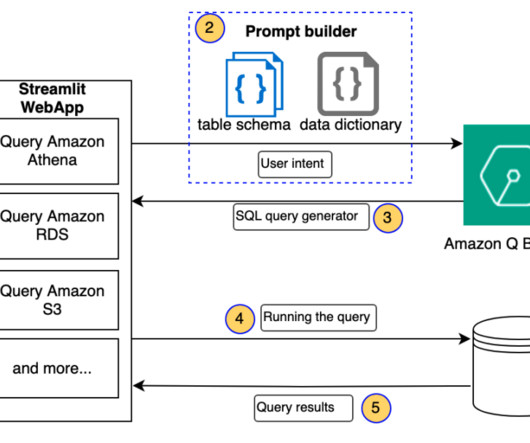
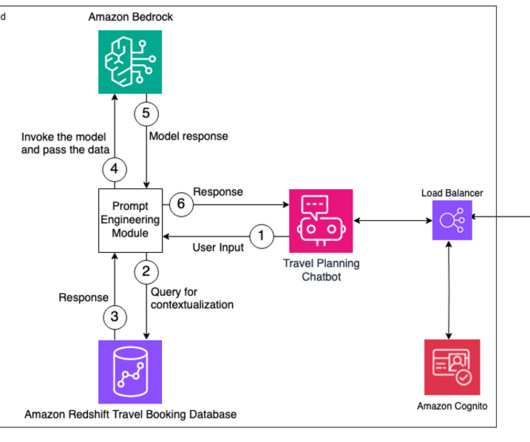
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
Natural language is ambiguous and imprecise, whereas data adheres to rigid schemas. For example, SQL queries can be complex and unintuitive for non-technical users. Handling complex queries involving multiple tables, joins, and aggregations makes it difficult to interpret user intent and translate it into correct SQL operations.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Loading data in Amazon Redshift Serverless. Create a SQL editor tab and be sure the sagemaker database is selected.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses.
How you now anonymize Data more easily Photo by Dušan veverkolog on Unsplash Google has just announced the public preview of BigQuery differential privacy with SQL building blocks. You can use these functions to anonymize their data. Hence, with this feature you can also ensure that data is shared there securely.
With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 data lake.
Policy Zones has been built into different Meta systems, including: Function-based systems that load, process, and propagate data through stacks of function calls in different programming languages. Batch-processing systems that process data rows in batch (mainly via SQL ). When data flows across different systems (e.g.,
In today’s highly competitive market, performing data analytics using machine learning (ML) models has become a necessity for organizations. It enables them to unlock the value of their data, identify trends, patterns, and predictions, and differentiate themselves from their competitors.
The Microsoft Certified Solutions Associate and Microsoft Certified Solutions Expert certifications cover a wide range of topics related to Microsoft’s technology suite, including Windows operating systems, Azure cloud computing, Office productivity software, Visual Studio programming tools, and SQL Server databases.
Machine learning (ML) is only possible because of all the data we collect. However, with data coming from so many different sources, it doesn’t always come in a format that’s easy for ML models to understand. Before you can take advantage of everything ML offers, much prep work is involved.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Data pipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. IBM watsonx.ai
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training.
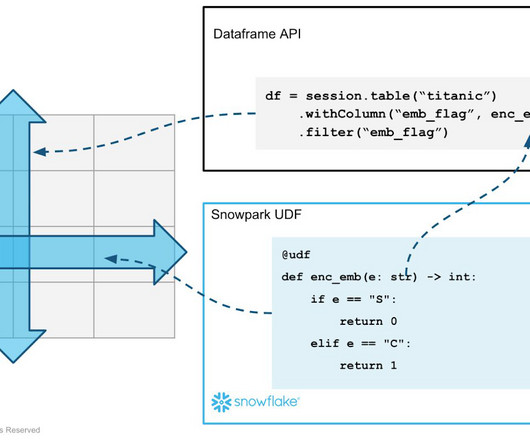
Snowpark brings the full power of SnowSQL running in the Snowflake Data Cloud as well as the flexibility to bring your favorite transformation and machine learning packages to the data. Since the most popular language for data science and ML is Python, the full Snowpark API is available in Python. Can’t wait?
Answer : Along with standard RDS features, Amazon RDS for Db2 supports key Db2 features, such as row and column organized tables for mixed and analytic workloads, the Adaptive Workload Optimizer to for better resource management, and rules-based access controls for advanced data protection. Scalability 5.
Why Migrate to a Modern Data Stack? With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. Data teams can focus on delivering higher-value data tasks with better organizational visibility.
Nevertheless, many data scientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. in a pandas DataFrame) but in the company’s datawarehouse (e.g.,
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content