This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI computers can be programmed to perform a wide range of tasks, from naturallanguageprocessing and image recognition to predictive analytics and decision-making. They can also switch between different tasks and learn from new data. According to Nvidia, the lifecycle of AI computing is explained below.
Helping government agencies adopt AI and ML technologies Precise works closely with AWS to offer end-to-end cloud services such as enterprise cloud strategy, infrastructure design, cloud-native application development, modern datawarehouses and data lakes, AI and ML, cloud migration, and operational support.
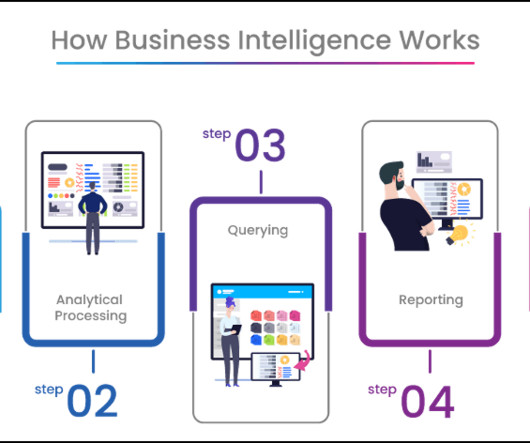
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Während das nun Anwendungsfälle auf der Prozessanalyse-Seite sind, kann Machine Learning jedoch auf der anderen Seite zur Anwendung kommen: Mit NER-Verfahren (Named Entity Recognition) aus dem NLP-Baukasten (NaturalLanguageProcessing) können Event Logs aus unstrukturierten Daten gewonnen werden, z.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses naturallanguageprocessing (NLP) techniques to extract valuable insights from textual data. Ensure that data is clean, consistent, and up-to-date.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. The raw data is processed by an LLM using a preconfigured user prompt. The processed output is stored in a database or datawarehouse, such as Amazon Relational Database Service (Amazon RDS).
Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
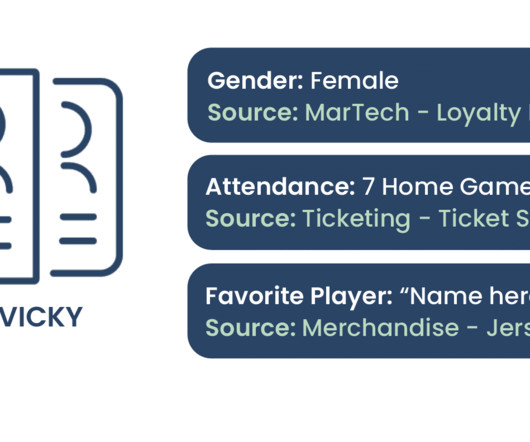
We are going to break down what we know about Victory Vicky based on all the data sources we have moved into our datawarehouse. The loyalty program is located in the MarTech Stack and moves data effortlessly into the datawarehouse. This information is also funneled into the datawarehouse.
In this post, Reveal experts showcase how they used Amazon Comprehend in their document processing pipeline to detect and redact individual pieces of PII. Amazon Comprehend is a fully managed and continuously trained naturallanguageprocessing (NLP) service that can extract insight about the content of a document or text.
A foundation model is built on a neural network model architecture to process information much like the human brain does. Fortunately, data stores serve as secure data repositories and enable foundation models to scale in both terms of their size and their training data.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. What is Text Splitting, and Why is it Important for Vector Embeddings?
Create an Amazon Redshift connection Amazon Redshift is a fully managed, petabyte-scale datawarehouse service that simplifies and reduces the cost of analyzing all your data using standard SQL. However, it is essential to acknowledge the inherent differences between human language and SQL.
Dashboarding was limited initially because they have been waiting on more progress with our complimentary initiative of migrating the underlying datawarehouse to Snowflake.
to_pandas() df Lastly, we can convert the table data into a CSV file. CSV files are often used to ingest data into relational databases or datawarehouses. He specializes in NaturalLanguageProcessing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
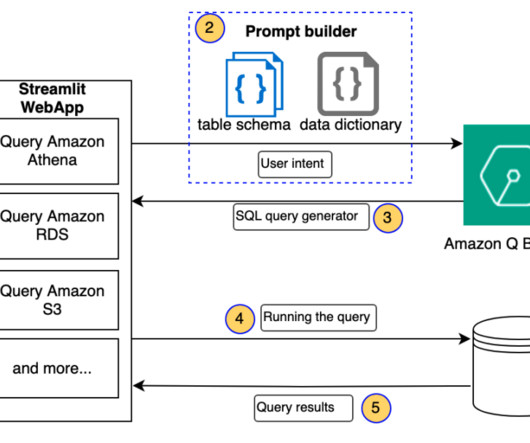
We provide the enterprise users with a medium of asking fact-based questions without having an underlying knowledge of data channels, thereby abstracting the complexities of writing simple to complex SQL queries.
This technological shift placed computing power into the hands of the individual consumer — yet access to corporate data still resided with the “techies”. The Rise of the DataWarehouse. The birth of the enterprise datawarehouse was heralded as the solution to limited access.
Data from various sources, collected in different forms, require data entry and compilation. That can be made easier today with virtual datawarehouses that have a centralized platform where data from different sources can be stored. One challenge in applying data science is to identify pertinent business issues.
The dataset Our structured dataset can reside in a SQL database, data lake, or datawarehouse as long as we have support for SQL. She leads machine learning (ML) projects in various domains such as computer vision, naturallanguageprocessing and generative AI.
It uses metadata and data management tools to organize all data assets within your organization. It synthesizes the information across your data ecosystem—from data lakes, datawarehouses, and other data repositories—to empower authorized users to search for and access business-ready data for their projects and initiatives.
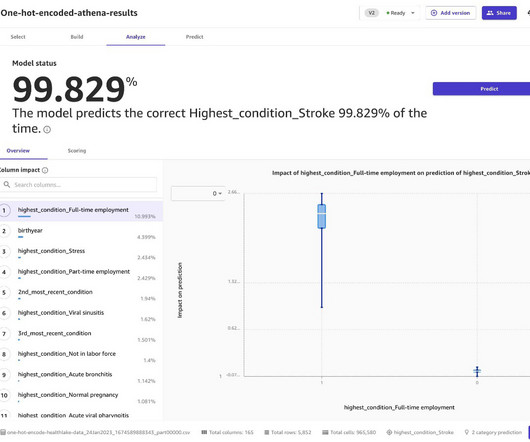
The high-level steps involved in the solution are as follows: Use AWS Step Functions to orchestrate the health data anonymization pipeline. Use Amazon Athena queries for the following: Extract non-sensitive structured data from Amazon HealthLake. Perform one-hot encoding with Amazon SageMaker Data Wrangler.
Voice-based queries use NaturalLanguageProcessing (NLP) and sentiment analysis for speech recognition. Customer service use cases Not only can ML understand what customers are saying, but it also understands their tone and can direct them to appropriate customer service agents for customer support.
Proper data collection practices are critical to ensure accuracy and reliability. Data Storage After collection, the data needs a secure and accessible storage system. Organizations may use databases, datawarehouses, or cloud-based storage solutions depending on the type and volume of data.
It’d be difficult to exaggerate the importance of data in today’s global marketplace, especially for firms which are going through digital transformation (DT). Using bad data, or the incorrect data can generate devastating results. This is where a reverse ETL process is needed. between 2022 and 2029.
Even as we grow in our ability to extract vital information from big data, the scientific community still faces roadblocks that pose major data mining challenges. In this article, we will discuss 10 key issues that we face in modern data mining and their possible solutions.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like NaturalLanguageProcessing (NLP) and machine learning. Tools like Unstructured.io
The platform’s integration with Azure services ensures a scalable and secure environment for Data Science projects. Azure Synapse Analytics Previously known as Azure SQL DataWarehouse , Azure Synapse Analytics offers a limitless analytics service that combines big data and data warehousing.
A more formal definition of text labeling, also known as text annotation, would be the process of adding meaningful tags or labels to raw text to make it usable for machine learning and naturallanguageprocessing tasks. It involves human annotators who manually assign labels to text data.
A more formal definition of text labeling, also known as text annotation, would be the process of adding meaningful tags or labels to raw text to make it usable for machine learning and naturallanguageprocessing tasks. It involves human annotators who manually assign labels to text data.
It’d be difficult to exaggerate the importance of data in today’s global marketplace, especially for firms which are going through digital transformation (DT). Using bad data, or the incorrect data can generate devastating results. This is where a reverse ETL process is needed. between 2022 and 2029.
The inherent ambiguity of naturallanguage can also result in multiple interpretations of a single query, making it difficult to accurately understand the user’s precise intent. To bridge this gap, you need advanced naturallanguageprocessing (NLP) to map user queries to database schema, tables, and operations.
Its drag-and-drop functionality simplifies the process of creating reports and dashboards. Its naturallanguageprocessing (NLP) feature allows users to generate insights through conversational queries. Qlik Sense – Qlik is an industry leader in data integration and analytics solutions that support AI strategies.
IBM Security® Discover and Classify (ISDC) is a data discovery and classification platform that delivers automated, near real-time discovery, network mapping and tracking of sensitive data at the enterprise level, across multi-platform environments.
That software typically includes features like: Business glossaries and data dictionaries (to store definitions). Data lineage features. Data cataloging functions, like naturallanguageprocessing. As data collection and volume surges, enterprises are inundated in both data and its metadata.
Many organizations store their data in structured formats within datawarehouses and data lakes. Amazon Bedrock Knowledge Bases offers a feature that lets you connect your RAG workflow to structured data stores. In her free time, she likes to go for long runs along the beach.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























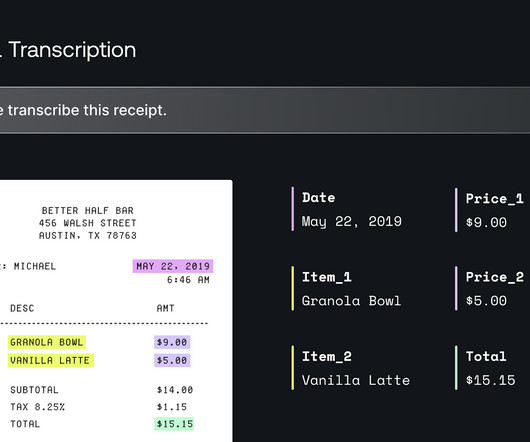









Let's personalize your content