This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
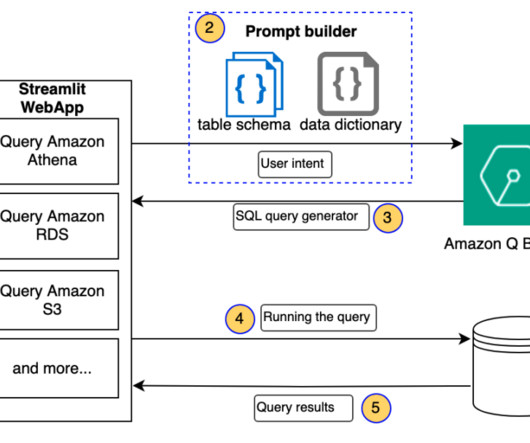
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Naturallanguage is ambiguous and imprecise, whereas data adheres to rigid schemas. For example, SQL queries can be complex and unintuitive for non-technical users. Domain-specific terminology further complicates the mapping process. The following diagram illustrates this workflow.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
The naturallanguage capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using naturallanguage, without the need to write SQL queries or learn a BI tool.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. This process is repeated until the entire text is divided into coherent segments.
Data from various sources, collected in different forms, require data entry and compilation. That can be made easier today with virtual datawarehouses that have a centralized platform where data from different sources can be stored. One challenge in applying data science is to identify pertinent business issues.
Lookers strength lies in its ability to connect to a wide variety of data sources. Examples include SQl, DWH, and Cloud based systems (Google Bigquery). With Looker, you can share dashboards and visualizations seamlessly across teams, providing stakeholders with access to real-time data.
This technological shift placed computing power into the hands of the individual consumer — yet access to corporate data still resided with the “techies”. The Rise of the DataWarehouse. The birth of the enterprise datawarehouse was heralded as the solution to limited access.
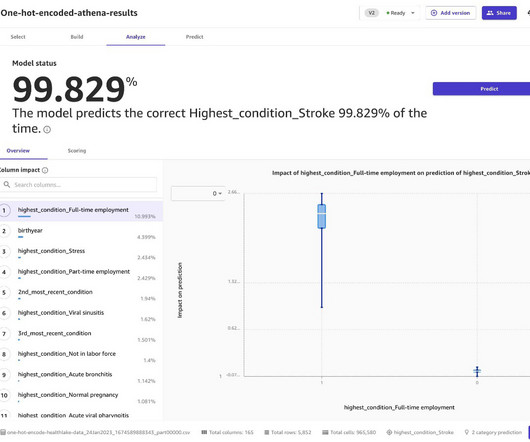
The high-level steps involved in the solution are as follows: Use AWS Step Functions to orchestrate the health data anonymization pipeline. Use Amazon Athena queries for the following: Extract non-sensitive structured data from Amazon HealthLake. Perform one-hot encoding with Amazon SageMaker Data Wrangler.
However, a master’s degree or specialised Data Science or Machine Learning courses can give you a competitive edge, offering advanced knowledge and practical experience. Essential Technical Skills Technical proficiency is at the heart of an Azure Data Scientist’s role.
Celonis unterscheidet sich von den meisten anderen Tools noch dahingehend, dass es versucht, die ganze Kette des Process Minings in einer einzigen und ausschließlichen Cloud-Anwendung in einer Suite bereitzustellen. Vielleicht haben wir auch das ein Stück weit Celonis zu verdanken. Aber auch andere Prozesse für andere Geschäftsprozesse z.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content