This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Datawarehouse generalizes and mingles data in multidimensional space. The post How to Build a DataWarehouse Using PostgreSQL in Python? appeared first on Analytics Vidhya.
Wouldn’t the process be much easier if the raw data were more organized and clean? Here’s when Data […]. The post What are Schemas in DataWarehouse Modeling? It’s possible, of course, but it can be tiresome and not be as accurate as it should be. appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A DataWarehouse is Built by combining data from multiple. The post A Brief Introduction to the Concept of DataWarehouse appeared first on Analytics Vidhya.
Introduction on DataWarehouses During one of the technical webinars, it was highlighted where the transactional database was rendered no-operational bringing day to day operations to a standstill. The post Understanding Key Concepts on DataWarehouses appeared first on Analytics Vidhya.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating data pipelines, and efficiently managing datawarehouses. appeared first on Analytics Vidhya.
Introduction Amazon Elastic MapReduce (EMR) is a fully managed service that makes it easy to process large amounts of data using the popular open-source framework Apache Hadoop. EMR enables you to run petabyte-scale datawarehouses and analytics workloads using the Apache Spark, Presto, and Hadoop ecosystems.
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the DataWarehouse system. ETL stands for Extract, Transform, and Load.
Nely Mihaylova Connecting SQL to Python or R A developer who is fluent in a statistical language, like Python or R, may quickly and easily use the packages of language to construct machine learning models on a massive dataset stored in a relational database management system.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Azure Functions now support Python 3.8 Amazon Redshift now has Pause and Resume Redshift, the datawarehouse, now has the ability to pause compute during unused times. Announcing Tensorflow Quantum Google Announces an open source library for prototyping quantum machine learning models. This saves on costs.
This better reflects the common Python practice of having your top level module be the project name. The goal is to have more comprehensive documentation: A new more modern theme + look An example of how to use the template Links and documentation for the tools you can choose from that solve particular tasks in the data science stack.
Familiarize yourself with essential data technologies: Data engineers often work with large, complex data sets, and it’s important to be familiar with technologies like Hadoop, Spark, and Hive that can help you process and analyze this data.
Python is the top programming language used by data engineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose the plus sign and for Notebook , choose Python 3.
Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure Data Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Python support has been available for a while. Azure Synapse. It’s true, I saw it happen this week.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. This process is repeated until the entire text is divided into coherent segments. Return the chunks as an ARRAY.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
Consider Python when choosing a language. Secondly, Python is multifunctional and in demand in the labor market. Data Mining is an important research process. You can make it a little easier for yourself. It is best to learn one language first, so you can fully leverage its capabilities. Machine learning. Practical experience.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Output is a fully self-contained HTML application.
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
EL stands for extract and load, and its primary goal is to just move the data from one place to another where the destination is usually a DataWarehouse or a Data Lake. The most fundamental difference between ELT and ETL is that the former first loads the data into the target storage and, then, processes them.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select.
Why: Data Makes It Different. If you peek under the hood of an ML-powered application, these days you will often find a repository of Python code. Data is at the core of any ML project, so data infrastructure is a foundational concern. However, not all Python code is equal. Data Science Layers.
This article was published as a part of the Data Science Blogathon. Machine learning and artificial intelligence, which are at the top of the list of data science capabilities, aren’t just buzzwords; many companies are keen to implement them.
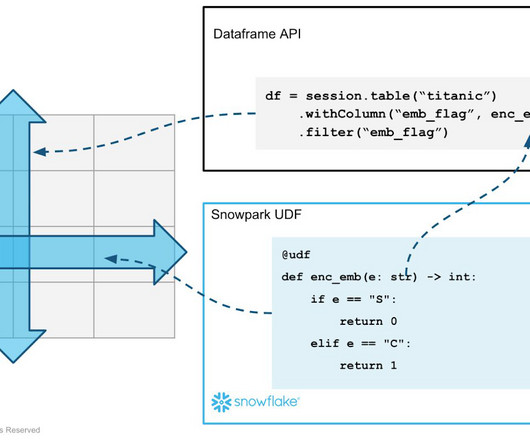
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Azure Functions now support Python 3.8 Amazon Redshift now has Pause and Resume Redshift, the datawarehouse, now has the ability to pause compute during unused times. Announcing Tensorflow Quantum Google Announces an open source library for prototyping quantum machine learning models. This saves on costs.
Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. It offers a cloud-agnostic data productivity hub called Matillion Data Productivity Cloud. Below is a sample scenario for 3 business units within an organization for the data mart layer of the datawarehouse.
While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […]. The post Step-by-Step Roadmap to Become a Data Engineer in 2023 appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction The volume of data collected worldwide has drastically increased over the past decade. Nowadays, data is continuously generated if we open an app, perform a Google search, or simply move from place to place with our mobile devices.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Introduction Containerization is becoming more popular and widely used by developers in the software industry in recent years. Docker is still considered one of the top tools for creating containers by building Images between containerization platforms or cloud platforms.
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems.
This article was published as a part of the Data Science Blogathon. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century.
Related article How to Build ETL Data Pipelines for ML See also MLOps and FTI pipelines testing Once you have built an ML system, you have to operate, maintain, and update it. All of them are written in Python. They store their feature data in Hopsworks’ free serverless platform, app.hopsworks.ai.
With Hex , it has never been easier to unlock insights from your data. In this blog, we will dive deeper into the capabilities of Snowpark for Python and how combining with Hex supports data science by providing faster and more efficient data processing and analytics capabilities on top of Hex’s easy notebook collaboration and sharing.
Batch-processing systems that process data rows in batch (mainly via SQL ). Examples include real-time and datawarehouse systems that power Meta’s AI and analytics workloads. Data annotation can be done at various levels of granularity, including table, column, row, or potentially even cell.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
This allows data that exists in cloud object storage to be easily combined with existing datawarehousedata without data movement. The advantage to NPS clients is that they can store infrequently used data in a cost-effective manner without having to move that data into a physical datawarehouse table.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content