This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They require strong programming skills, expertise in data processing, and knowledge of database management. Salary Trends – Data engineers can earn salaries ranging from $90,000 to $130,000 per year, depending on their experience and the location of the job.
The goal of data cleaning, the data cleaning process, selecting the best programming language and libraries, and the overall methodology and findings will all be covered in this post. Datawrangling requires that you first clean the data. In this example, we'll load a CSV file using the read_csv() method.
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. So by learning to use SQL, you’ll write efficient and effective queries, as well as understand how the data is structured and stored.
Here are some simplified usage patterns where we feel Dataiku can help: Data Preparation Dataiku offers robust data preparation capabilities that streamline the entire process of transforming raw data into actionable insights.
ODSC Bootcamp Primer: DataWrangling with SQL Course January 25th @ 2PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in AI.
SQL Primer Thursday, September 7th, 2023, 2 PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in learning AI. You will learn how to design and write SQL code to solve real-world problems.
Introduction In the realm of databases, where information reigns supreme, attributes are the fundamental building blocks. They act as the defining characteristics of entities, providing the details that breathe life into our data. Check Out: Top DBMS Interview Questions and Answers Unveiling the Essence of Attributes Imagine a library.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables. For instructions to catalog the data, refer to Populating the AWS Glue Data Catalog. Familiarity with SageMaker and its components, such as Amazon SageMaker Studio , SageMaker Canvas, and SageMaker notebooks.
Cross-Column Analysis: Explore relationships between columns to uncover potential data dependencies or correlations. Identify potential foreign key relationships between tables in a relational database. Data Distribution Analysis: Create histograms, box plots, or scatter plots to visualize data distributions and relationships.
With numerous job opportunities, Data Science skills have become essential in the market. The easiest skill that a Data Science aspirant might develop is SQL. Management and storage of Data in businesses require the use of a Database Management System. SQL is the standard language that relational databases uses.
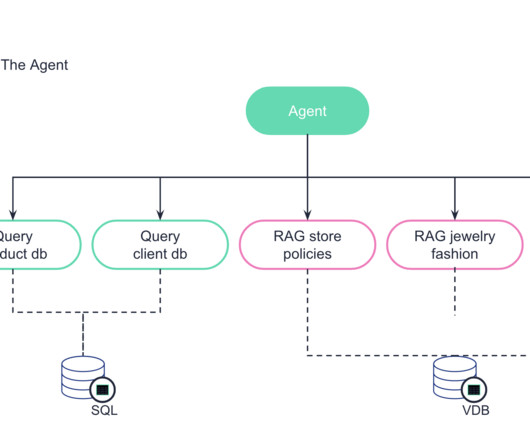
Capabilities include session loading, query refinement, history saving, guardrails like subject classification and a toxicity filter, connection to monitoring, the ability to iterate and retrain the model, external database connections, and more. They also had access to a database with client data and a database with product data.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. DataWrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
The starting range for a SQL Data Analyst is $61,128 per annum. How SQL Important in Data Analytics? Sincerely, SQL is used by Data Analysts for storing data in a particular type of Database and ensures flexibility in accessing or updating data. An SQL Data Analyst is vital for an organisation.
They introduce two primary data structures, Series and Data Frames, which facilitate handling structured data seamlessly. With Pandas, you can easily clean, transform, and analyse data. These tools allow you to process and analyse vast amounts of data efficiently.
SQL Databases might sound scary, but honestly, they’re not all that bad. Though there have been some refits and improvements, the simplicity and direct-to-the-point nature of this coding language are why it’s still the standard for relational databases. Learning is learning.
The library is built on top of the popular numerical computing library NumPy and provides high-performance data structures and functions for working with structured and unstructured data.
Steps to Become a Data Scientist If you want to pursue a Data Science course after 10th, you need to ensure that you are aware the steps that can help you become a Data Scientist. Accordingly, make sure that you have Python and R as part of your high-school course or online course in Data Science.
This is where a data dictionary and business glossary become useful for getting both your business and IT teams on the same page. What is a data dictionary? As the name suggests, a data dictionary defines and describes technical data terms. Data terms could be database schemas, tables, or columns.
Agentic Systems for Competitive Intelligence: Enhancing Business Decision-Making Lets explore how Agentic systems can autonomously collect and filter relevant data while conducting sophisticated pattern analysis to draw preliminary conclusions and generate actionable insights.
Conclusion Jinja offers a dynamic toolkit that enhances your dbt models and elevates our data-wrangling skills. We can unlock valuable insights and drive data-driven decisions efficiently by wielding Jinja’s power. The variables defined with the --vars command line argument have the highest order of precedence.
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions.
Humans and machines Data scientists and analysts need to be aware of how this technology will affect their role, their processes, and their relationships with other stakeholders. There are clearly aspects of datawrangling that AI is going to be good at. Chat interfaces can be viewed as another step up the ladder of abstraction.
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wrangling processes with a fast and seamless user experience to manage and access data products.
Gain knowledge in data manipulation and analysis: Familiarize yourself with data manipulation techniques using tools like SQL for database querying and data extraction. Also, learn how to analyze and visualize data using libraries such as Pandas, NumPy, and Matplotlib.
This is the data at the source step (the first step in the right hand side) before any datawrangling. This is to improve the data loading performance. And, this is not only for SQL queries but also works for MongoDB queries and other datawrangling steps such as Filter, Create Calculation, etc. ?
A next huge challenge is data preparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. These tasks can take up to 80% of a data analyst’s time, a well-cited statistic. But again, there are challenges.
A next huge challenge is data preparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. These tasks can take up to 80% of a data analyst’s time, a well-cited statistic. But again, there are challenges.
Example template for an exploratory notebook | Source: Author How to organize code in Jupyter notebook For exploratory tasks, the code to produce SQL queries, pandas datawrangling, or create plots is not important for readers. You can check the different Markdown syntax options in Markdown Cells — Jupyter Notebook 6.5.2 documentation.
Ensure headers are clear and data types are formatted correctly (currency for “Sales Amount”). Identify the specific information you need based on the report’s purpose.
It involves retrieving data from various sources, such as databases, spreadsheets, or even cloud storage. The goal is to collect relevant data without affecting the source system’s performance. Compatibility with Existing Systems and Data Sources Compatibility is critical. How to drop a database in SQL server?
Step 4: DataWrangling and Visualization Data isn’t always in pristine formats. Learning techniques to clean, preprocess, and visualize data allows you to transform raw information into actionable insights. Strong problem-solving and communication skills are also important. Both approaches have merits.
Data scientists typically have strong skills in areas such as Python, R, statistics, machine learning, and data analysis. Believe it or not, these skills are valuable in data engineering for datawrangling, model deployment, and understanding data pipelines. Learn more about the cloud.
It’s everywhere such as Excel, database, etc. If then do A else do B — ifelse function in R & Exploratory Most likely you have used or heard about ‘ifelse’ function before. And of course, it is in R, which means you can use it in Exploratory as well. I’m going to talk about how you can use the ifelse function in Exploratory.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
Covers a wide range of topics, including software engineering, databases, operating systems, artificial intelligence, networking, and computer graphics. Common libraries in Python, such as pandas and NumPy, are essential for data cleaning, preprocessing, and transformation.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. Some LLMs also offer methods to produce embeddings for entire sentences or documents, capturing their overall meaning and semantic relationships.
Data often arrives from multiple sources in inconsistent forms, including duplicate entries from CRM systems, incomplete spreadsheet records, and mismatched naming conventions across databases. These issues slow analysis pipelines and demand time-consuming cleanup.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content