This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They require strong programming skills, expertise in data processing, and knowledge of database management. Salary Trends – Data engineers can earn salaries ranging from $90,000 to $130,000 per year, depending on their experience and the location of the job.
Because it can swiftly and effectively handle data structures, carry out calculations, and apply algorithms, Python is the perfect language for handling data. Datawrangling requires that you first clean the data. It entails searching the data for missing values and assigning or imputed values to them.
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. in 2022, according to the PYPL Index.
Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
SQL Primer Thursday, September 7th, 2023, 2 PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in learning AI. You will learn how to design and write SQL code to solve real-world problems.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
ODSC Bootcamp Primer: DataWrangling with SQL Course January 25th @ 2PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in AI.
In this article we will provide a brief introduction to Pandas, one of the most famous Python libraries for Data Science and Machine learning. Introduction to Pandas – The fundamentals Pandas is a popular and powerful open-source data analysis and manipulation library for the Python programming language.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala. And you should have experience working with big data platforms such as Hadoop or Apache Spark.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. DataWrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
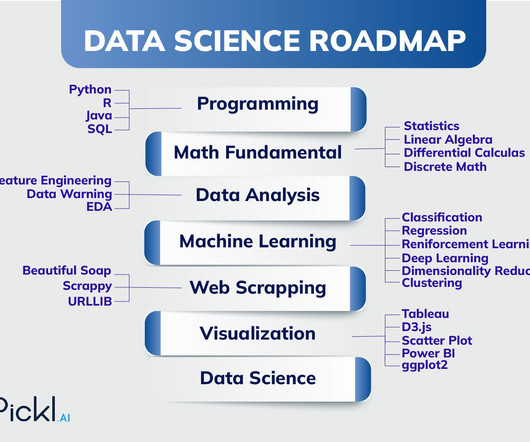
Following is the Data Science Roadmap that you need to know: Learn DataWrangling, Data Visualisation and Reporting: For dealing with complex datasets you need to learn the skill of DataWrangling which will help you clean, organise and transform data into an understandable format.
With numerous job opportunities, Data Science skills have become essential in the market. The easiest skill that a Data Science aspirant might develop is SQL. Management and storage of Data in businesses require the use of a Database Management System. SQL is the standard language that relational databases uses.
Without the ability to utilize data, create models, visualizations, algorithms, or anything else, you’re left without a story. But it’s not only the ability to work with data, it’s also about scaling your own abilities. SQL Databases might sound scary, but honestly, they’re not all that bad. Learning is learning.
The starting range for a SQL Data Analyst is $61,128 per annum. How SQL Important in Data Analytics? Sincerely, SQL is used by Data Analysts for storing data in a particular type of Database and ensures flexibility in accessing or updating data. An SQL Data Analyst is vital for an organisation.
dbt’s SQL-based approach democratizes data transformation. However, python and other programming languages edge out SQL with its metaprogramming capabilities. dbt’s Jinja integration bridges the gap between the expressiveness of Python and the familiarity of SQL. Round 11.123 | round(1) 11.1
Agentic Systems for Competitive Intelligence: Enhancing Business Decision-Making Lets explore how Agentic systems can autonomously collect and filter relevant data while conducting sophisticated pattern analysis to draw preliminary conclusions and generate actionable insights.
Learn programming languages and tools: While you may not have a technical background, acquiring programming skills is essential in data science. Start by learning Python or R, which are widely used in the field. Also, learn how to analyze and visualize data using libraries such as Pandas, NumPy, and Matplotlib.
Example template for an exploratory notebook | Source: Author How to organize code in Jupyter notebook For exploratory tasks, the code to produce SQL queries, pandas datawrangling, or create plots is not important for readers. If a reviewer wants more detail, they can always look at the Python module directly.
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions. What Skills Are Necessary for A Career in Big Data?
Data Scientists play a crucial role in collecting, cleaning, and analyzing data, ultimately guiding organizations to make informed decisions. Software engineering concepts facilitate efficient data manipulation, enabling you to design algorithms, create visualizations, and build machine learning models.
Data scientists typically have strong skills in areas such as Python, R, statistics, machine learning, and data analysis. Believe it or not, these skills are valuable in data engineering for datawrangling, model deployment, and understanding data pipelines. Learn more about the cloud.
It involves retrieving data from various sources, such as databases, spreadsheets, or even cloud storage. The goal is to collect relevant data without affecting the source system’s performance. Compatibility with Existing Systems and Data Sources Compatibility is critical. How to drop a database in SQL server?
Covers a wide range of topics, including software engineering, databases, operating systems, artificial intelligence, networking, and computer graphics. These may include programming languages (such as Python , R, or SQL), data structures, algorithms, and problem-solving abilities.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. PythonPython’s prominence is expected. This enhances the context awareness and factual accuracy of LLM outputs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content