This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
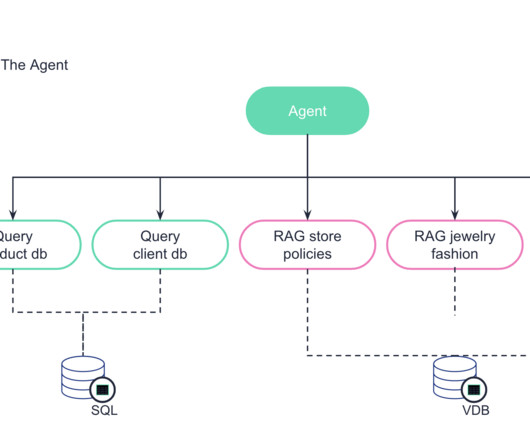
The health care industry has more data than it can utilize in meaningful decision-support capabilities. Whether it is the volume, the velocity, or the variety of the data, wrangling insights from this incessant stream is a never-ending and complex task. Enter the age of AI, where an agent can synthesize [.]
Use Open Data from Closed Prize Competitions ¶ As part of a problem set, in-class demonstration, exam, or other project assignment that requires model development, you can use the open data from a closed prize competition. There are open datasets covering a variety of modalities and topics. Difficulty: All skill levels.
Here are some simplified usage patterns where we feel Dataiku can help: Data Preparation Dataiku offers robust data preparation capabilities that streamline the entire process of transforming raw data into actionable insights.
Enables Seamless Data Standardization. Ideally, datadocumentation and formats should be standard throughout an organization. Thankfully, current ePCR solutions enable ambulance crews, back-office workers, and other stakeholders to easily draw data from one system.
As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. But here is a problem: While pySpark syntax is straightforward and very easy to follow, it can be readily confused with other common libraries for datawrangling.
As a reminder, I highly recommend that you refer to more than one resource (other than documentation) when learning ML, preferably a textbook geared toward your learning level (beginner/intermediate / advanced). McKinney, Python for Data Analysis: DataWrangling with Pandas, NumPy, and IPython, 2nd ed., 3, IEEE, 2014.
Transformers for Document Understanding Vaishali Balaji | Lead Data Scientist | Indium Software This session will introduce you to transformer models, their working mechanisms, and their applications. Free and paid passes are available now–register here.
This new paradigm comes with new rules: Self-service is critical for an insight-driven organization, and in this more fluid data environment, understanding the lineage and context of that data is key to data exploration. Davis will discuss how datawrangling makes the self-service analytics process more productive.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
This traditional focus on data control weakens community collaboration. In fact, such traditional governance models enact rigid policies that often alienate, or even scare, data workers. People must reference documentation before working with any specific dataset. Improve data quality by formalizing accountability for metadata.
You can create a new environment for your Data Science projects, ensuring that dependencies do not conflict. Jupyter Notebook is another vital tool for Data Science. It allows you to create and share live code, equations, visualisations, and narrative text documents.
The library is built on top of the popular numerical computing library NumPy and provides high-performance data structures and functions for working with structured and unstructured data.
These packages allow for text preprocessing, sentiment analysis, topic modeling, and document classification. It allows data scientists to combine code, documentation, and visualizations in a single document, making it easier to share and reproduce analyses.
Humans and machines Data scientists and analysts need to be aware of how this technology will affect their role, their processes, and their relationships with other stakeholders. There are clearly aspects of datawrangling that AI is going to be good at.
That’s why it’s critical that important terms be defined, documented, and made visible to everyone. This is where a data dictionary and business glossary become useful for getting both your business and IT teams on the same page. For these tasks, they may look to the data dictionary to ensure use of the right assets.
Extensive Documentation : Many of these tools have robust documentation and active communities, making it easier for users to troubleshoot and learn. Python offers rich libraries like Pandas and TensorFlow for DataWrangling , Machine Learning , and Web-Based Applications.
Accordingly, it is possible for the Python users to ask for help from Stack Overflow, mailing lists and user-contributed code and documentation. As learning Python programming opens doors for multiple opportunities in Data Science roles, availing the course will only enhance your programming skills.
Data Analyst to Data Scientist: Level-up Your Data Science Career The ever-evolving field of Data Science is witnessing an explosion of data volume and complexity. Invest in Version Control and Documentation Use version control systems like Git to track changes in code, models, and data pipelines.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. Data to explore: Outline the tables or datasets you’re exploring/analyzing and reference their sources or link their data catalog entries. documentation.
Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run data pipelines. More For You To Read: 10 Data Modeling Tools You Should Know.
D Data Mining : The process of discovering patterns, insights, and knowledge from large datasets using various techniques such as classification, clustering, and association rule learning. DataWrangling: The cleaning, transforming, and structuring of raw data into a format suitable for analysis.
Some LLMs also offer methods to produce embeddings for entire sentences or documents, capturing their overall meaning and semantic relationships. Python boasts a vast ecosystem of libraries like TensorFlow, PyTorch, Pandas, NumPy, and Scikit-learn, empowering prompt engineers to handle datawrangling and analysis seamlessly.
For more information on incorporating Docker with your application, the Docker documentation is a valuable resource you can reference. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners.
For example, it can surface information from the company's guidelines, documentation, company processes, etc. This starts from datawrangling and constructing data pipelines all the way to monitoring models and conducting risk reviews using "policy as code". These can help the agent have better conversations.
Qt has had its commercial ups and downs in the last 20 years, but it has grown with me and is now very robust, comprehensive and well documented. The website and user documentation are also substantial pieces of work. The PDF version of the documentation is nearly 500 pages. But I later added a Mac version as well.
Amazon SageMaker Canvas is a low-code no-code (LCNC) ML platform that guides users through every stage of the ML journey, from initial data preparation to final model deployment. Without writing a single line of code, users can explore datasets, transform data, build models, and generate predictions.
Mastering tools like LLMs, prompt engineering, and datawrangling is now essential for every modern developer. Building AI Skills in Your Engineering Team: A 2025 Guide to Upskilling withImpact AI is redefining engineeringpowering code generation, autonomous agents, and multimodal systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content