This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Jupyter Notebook is a web-based interactive computing platform that many data scientists use for datawrangling, data visualization, and prototyping of their Machine Learning models. The post How to Convert Jupyter Notebook into ML Web App? appeared first on Analytics Vidhya.
The goal of data cleaning, the data cleaning process, selecting the best programming language and libraries, and the overall methodology and findings will all be covered in this post. Datawrangling requires that you first clean the data.
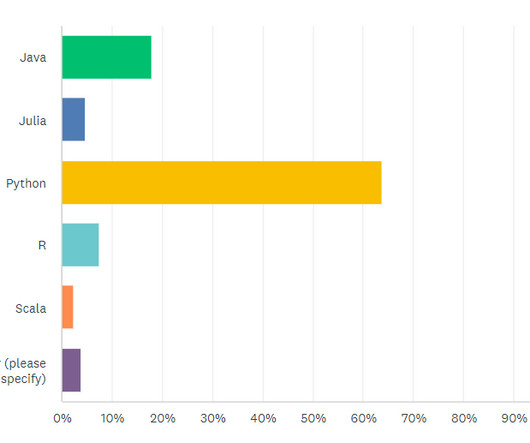
Programming skills: Data scientists should be proficient in programming languages such as Python, R, or SQL to manipulate and analyze data, automate processes, and develop statistical models. Combining their complementary skills and expertise leads to comprehensive and impactful data-driven solutions.
Additionally, it may be found on Amazon SageMaker JumpStart, an ML hub with access to ML solutions, models, and algorithms. fine-tuning the model to custom data is easier than ever. Custom LoRAs or checkpoints can be generated with less need for datawrangling. The research-only SDXL 0.9 should function well.
As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. But here is a problem: While pySpark syntax is straightforward and very easy to follow, it can be readily confused with other common libraries for datawrangling.
Machine Learning for Data Science by Carlos Guestrin This is an intermediate-level course that teaches you how to use machine learning for data science tasks. The course covers topics such as datawrangling, feature engineering, and model selection. Step up your game and make accurate predictions based on vast datasets.
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate data preparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. He is dedicated to making ML and generative AI more accessible and applying them to solve challenging problems.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, datawrangling, and data preparation. What percentage of machine learning models developed in your organization get deployed to a production environment?
As a reminder, I highly recommend that you refer to more than one resource (other than documentation) when learning ML, preferably a textbook geared toward your learning level (beginner/intermediate / advanced). In ML, there are a variety of algorithms that can help solve problems. 3, IEEE, 2014. Packt, ISBN: 978–1787125933, 2017.
ML Pros Deep-Dive into Machine Learning Techniques and MLOps Seth Juarez | Principal Program Manager, AI Platform | Microsoft Learn how new, innovative features in Azure machine learning can help you collaborate and streamline the management of thousands of models across teams. Check out a few of the highlights from each group below.
Big data analytics is evergreen, and as more companies use big data it only makes sense that practitioners are interested in analyzing data in-house. Deep learning is a fairly common sibling of machine learning, just going a bit more in-depth, so ML practitioners most often still work with deep learning.
Mini-Bootcamp and VIP Pass holders will have access to four live virtual sessions on data science fundamentals. Confirmed sessions include: An Introduction to DataWrangling with SQL with Sheamus McGovern, Software Architect, Data Engineer, and AI expert Programming with Data: Python and Pandas with Daniel Gerlanc, Sr.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. As MLOps become more relevant to ML demand for strong software architecture skills will increase as well.
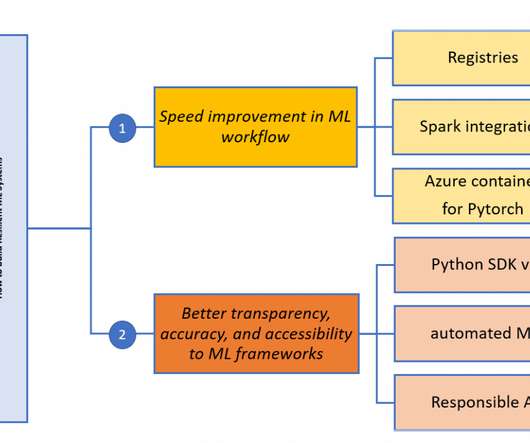
The Azure ML team has long focused on bringing you a resilient product, and its latest features take one giant leap in that direction, as illustrated in the graph below (Figure 1). Continue reading to learn more about Azure ML’s latest announcements. This is the motivation behind several of Azure ML’s latest features.
More confirmed sessions include Introduction to Large Lange Models (LLMs) | ODSC Instructor Introduction to Data Course | Sheamus McGovern | CEO and Software Architect, Data Engineer, and AI expert | ODSC Advanced NLP: Deep Learning and Transfer Learning for Natural Language Processing | Dipanjan (DJ) Sarkar | Lead Data Scientist | Google Developer (..)
ML Pros Deep-Dive into Machine Learning Techniques and MLOps with Microsoft LLMs in Data Analytics: Can They Match Human Precision? Primer courses include Data Primer SQL Primer Programming Primer with Python AI Primer DataWrangling with Python LLMs, Gen AI, and Prompt Engineering Register for free here!
The webinar hosts Eli Stein, Partner and Modern Marketing Capabilities Leader from McKinsey, Ze’ev Rispler, ML Engineer, from Iguazio (acquired by McKinsey), and myself. The gen AI application included Next-Best-Action ML models, an interactive application to manage the process and for feedback loops, and guardrails and governance protocols.
They introduce two primary data structures, Series and Data Frames, which facilitate handling structured data seamlessly. With Pandas, you can easily clean, transform, and analyse data. Matplotlib Matplotlib is a powerful plotting library for creating static, animated, and interactive visualisations in Python.
March 14, 2023: ODSC East Bootcamp Warmup: SQL Primer Course April 6, 2023: ODSC East Bootcamp Warmup: Programming Primer Course with Python April 26, 2023: ODSC East Bootcamp Warmup: AI Primer Course And during ODSC East this May 9th-11th, you can check out these bootcamp-exclusive sessions: An Introduction to DataWrangling with SQL Programming with (..)
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. DataWrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Steps to Become a Data Scientist If you want to pursue a Data Science course after 10th, you need to ensure that you are aware the steps that can help you become a Data Scientist. For instance, calculus can help with optimising ML algorithms. Using Python libraries like pandas can help you better in the process.
There is a position called Data Analyst whose work is to analyze the historical data, and from that, they will derive some KPI s (Key Performance Indicators) for making any further calls. For Data Analysis you can focus on such topics as Feature Engineering , DataWrangling , and EDA which is also known as Exploratory Data Analysis.
ML Open Source Engineer at WMware’s session “ Do You Know About the People Behind The Tools? Learn how both co-exist and what it means to be part of the ML open-source community. Finally, there is Anna Jung, Sr. The secret is the fully immersive experience that you’ll get.
In manufacturing, data engineering aids in optimizing operations and enhancing productivity while ensuring curated data that is both compliant and high in integrity. The increased efficiency in data “wrangling” means that more accurate modeling and planning may be done, enabling manufacturers to make stronger data-driven decisions.
The natural language interface enables a wide audience of both ML and non-ML experts to engage with the models. A next huge challenge is data preparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. But again, there are challenges.
The natural language interface enables a wide audience of both ML and non-ML experts to engage with the models. A next huge challenge is data preparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. But again, there are challenges.
This article is part of the AWS SageMaker series for exploration of ’31 Questions that Shape Fortune 500 ML Strategy’. We were able to identify feature correlations, data imbalance, and datatype requirements. To prepare the data for models, a data scientist often needs to transform, clean, and enrich the dataset.
To keep up with the rapidly growing Insurance industry and its increasing data and compute needs, it’s important to centralize data from multiple sources while maintaining high performance and concurrency. Also today’s volume, variety, and velocity of data, only intensify the data-sharing issues.
Here are a few sessions that you can check out soon: March 2, 2023: ODSC East Bootcamp Warmup: Data Primer Course March 14, 2023: ODSC East Bootcamp Warmup: SQL Primer Course April 6, 2023: ODSC East Bootcamp Warmup: Programming Primer Course with Python April 26, 2023: ODSC East Bootcamp Warmup: AI Primer Course And during ODSC East this May 9th-11th, (..)
Goal The objective of this post is to demonstrate how Polars performance is much better than other open-source libraries in a variety of data analysis tasks, such as data cleaning, datawrangling, and data visualization. ? BECOME a WRITER at MLearning.ai // invisible ML // 800+ AI tools Mlearning.ai
Machine Learning: Data Science aspirants need to have a good and concise understanding on Machine Learning algorithms including both supervised and unsupervised learning. Proficiency in ML is understood when these are not just present in the aspirant in conceptual ways but also in terms of its applications in solving business problems.
McGovern outlined foundational competencies and emerging areas of expertise that professionals must master to stay competitive: Core Skills: Programming (primarily Python), statistics, probability, and datawrangling remain the bedrock of AI roles. Machine learning and LLM modeling have joined this list as foundational skills.
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wrangling processes with a fast and seamless user experience to manage and access data products.
Nevertheless, many data scientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. documentation. Aside neptune.ai
The machine learning (ML) lifecycle defines steps to derive values to meet business objectives using ML and artificial intelligence (AI). Here are some details about these packages: jupyterlab is for model building and data exploration. matplotlib is for data visualization. Why Use Docker for Machine Learning? Flask==2.1.2
Open Source ML/DL Platforms: Pytorch, Tensorflow, and scikit-learn Hiring managers continue to favor the most popular open-source machine/deep learning platforms including Pytorch, Tensorflow, and scikit-learn. It’s a pre-trained model capable of various tasks like text classification, question answering, and sentiment analysis.
Took me a couple of tries to get the data and result-matrices set up in such a way that it made sense for the model to do calculations on. The datawrangling, however, is quite heavy.
Here are some simplified usage patterns where we feel Dataiku can help: Data Preparation Dataiku offers robust data preparation capabilities that streamline the entire process of transforming raw data into actionable insights. This capability can reveal hidden patterns and optimize data for improved model performance.
Data Analyst to Data Scientist: Level-up Your Data Science Career The ever-evolving field of Data Science is witnessing an explosion of data volume and complexity. This can significantly reduce development time and democratize Machine Learning for Data Analysts looking to transition into architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content