This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Jupyter Notebook is a web-based interactive computing platform that many data scientists use for datawrangling, data visualization, and prototyping of their Machine Learning models. It is easy to use the platform, and we can do programming in many languages like Python, Julia, R, etc. […].
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. in 2022, according to the PYPL Index.
Because it can swiftly and effectively handle data structures, carry out calculations, and apply algorithms, Python is the perfect language for handling data. Datawrangling requires that you first clean the data. It entails searching the data for missing values and assigning or imputed values to them.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building data pipelines.
Machine Learning for Absolute Beginners by Kirill Eremenko and Hadelin de Ponteves This is another beginner-level course that teaches you the basics of machine learning using Python. Machine Learning with Python by Andrew Ng This is an intermediate-level course that teaches you more advanced machine-learning concepts using Python.
As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. But here is a problem: While pySpark syntax is straightforward and very easy to follow, it can be readily confused with other common libraries for datawrangling.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, datawrangling, and data preparation. What percentage of machine learning models developed in your organization get deployed to a production environment?
As a reminder, I highly recommend that you refer to more than one resource (other than documentation) when learning ML, preferably a textbook geared toward your learning level (beginner/intermediate / advanced). In ML, there are a variety of algorithms that can help solve problems. Mirjalili, Python Machine Learning, 2nd ed.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
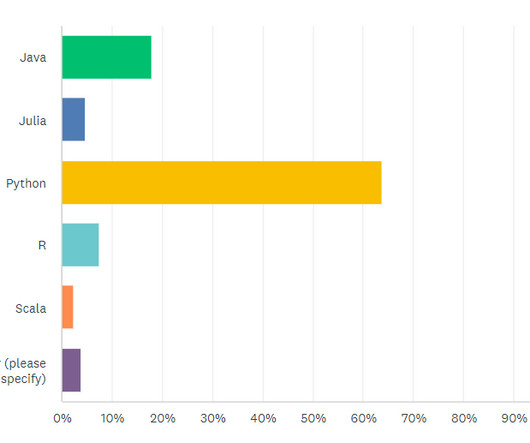
Primary Coding Language for Machine Learning Likely to the surprise of no one, python by far is the leading programming language for machine learning practitioners. Big data analytics is evergreen, and as more companies use big data it only makes sense that practitioners are interested in analyzing data in-house.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. While knowing Python, R, and SQL are expected, you’ll need to go beyond that.
ML Pros Deep-Dive into Machine Learning Techniques and MLOps Seth Juarez | Principal Program Manager, AI Platform | Microsoft Learn how new, innovative features in Azure machine learning can help you collaborate and streamline the management of thousands of models across teams. Check out a few of the highlights from each group below.
Here are a few other training sessions you can check out during the event: An Introduction to DataWrangling with SQL: Sheamus McGovern | CEO and ML Engineer | ODSC Advanced Fraud Modeling & Anomaly Detection with Python & R: Aric LaBarr, PhD | Associate Professor of Analytics | Institute for Advanced Analytics at NC State University Machine (..)
Python is one of the widely used programming languages in the world having its own significance and benefits. Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science. Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you.
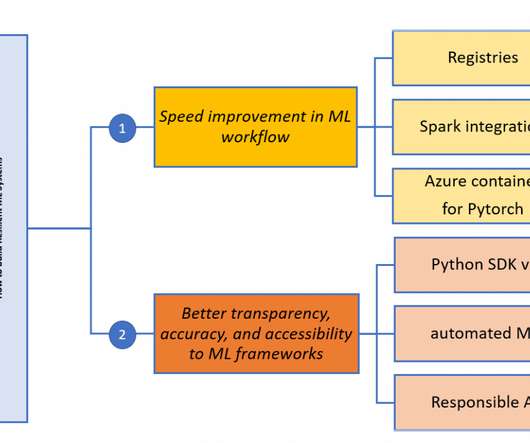
The Azure ML team has long focused on bringing you a resilient product, and its latest features take one giant leap in that direction, as illustrated in the graph below (Figure 1). Continue reading to learn more about Azure ML’s latest announcements. This is the motivation behind several of Azure ML’s latest features.
Mini-Bootcamp and VIP Pass holders will have access to four live virtual sessions on data science fundamentals. Confirmed sessions include: An Introduction to DataWrangling with SQL with Sheamus McGovern, Software Architect, Data Engineer, and AI expert Programming with Data: Python and Pandas with Daniel Gerlanc, Sr.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
More confirmed sessions include Introduction to Large Lange Models (LLMs) | ODSC Instructor Introduction to Data Course | Sheamus McGovern | CEO and Software Architect, Data Engineer, and AI expert | ODSC Advanced NLP: Deep Learning and Transfer Learning for Natural Language Processing | Dipanjan (DJ) Sarkar | Lead Data Scientist | Google Developer (..)
ML Pros Deep-Dive into Machine Learning Techniques and MLOps with Microsoft LLMs in Data Analytics: Can They Match Human Precision? Primer courses include Data Primer SQL Primer Programming Primer with Python AI Primer DataWrangling with Python LLMs, Gen AI, and Prompt Engineering Register for free here!
Following is the Data Science Roadmap that you need to know: Learn DataWrangling, Data Visualisation and Reporting: For dealing with complex datasets you need to learn the skill of DataWrangling which will help you clean, organise and transform data into an understandable format.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. DataWrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Without the ability to utilize data, create models, visualizations, algorithms, or anything else, you’re left without a story. But it’s not only the ability to work with data, it’s also about scaling your own abilities.
Goal The objective of this post is to demonstrate how Polars performance is much better than other open-source libraries in a variety of data analysis tasks, such as data cleaning, datawrangling, and data visualization. ? It is available in multiple languages: Python, Rust, and NodeJS.
The machine learning (ML) lifecycle defines steps to derive values to meet business objectives using ML and artificial intelligence (AI). These Python virtual environments encapsulate and manage Python dependencies, while Docker encapsulates the project’s dependency stack down to the host OS. Prerequisite Python 3.8
Nevertheless, many data scientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. If a reviewer wants more detail, they can always look at the Python module directly.
McGovern outlined foundational competencies and emerging areas of expertise that professionals must master to stay competitive: Core Skills: Programming (primarily Python), statistics, probability, and datawrangling remain the bedrock of AI roles. Machine learning and LLM modeling have joined this list as foundational skills.
Data Analyst to Data Scientist: Level-up Your Data Science Career The ever-evolving field of Data Science is witnessing an explosion of data volume and complexity. This can significantly reduce development time and democratize Machine Learning for Data Analysts looking to transition into architecture.
Open Source ML/DL Platforms: Pytorch, Tensorflow, and scikit-learn Hiring managers continue to favor the most popular open-source machine/deep learning platforms including Pytorch, Tensorflow, and scikit-learn. PythonPython’s prominence is expected.
When implementing machine learning (ML) workflows in Amazon SageMaker Canvas , organizations might need to consider external dependencies required for their specific use cases. Without writing a single line of code, users can explore datasets, transform data, build models, and generate predictions. that relies on the mpmath library.
That starts with programmingespecially in languages like Python and SQL, where most machine learning tools and AI libraries are built. Engineers who can visualize data, explain outputs, and align their work with business objectives are consistently more valuable to theirteams. Lets not forget datawrangling.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. in Ecology, he brings a unique perspective to statistics, spatial analysis, and real-world data applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content