This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine Learning for Data Science by Carlos Guestrin This is an intermediate-level course that teaches you how to use machine learning for data science tasks. The course covers topics such as datawrangling, feature engineering, and model selection.
They offer the ability to challenge one’s knowledge and get hands-on practice to boost their skills in areas, including, but not limited to, exploratory data analysis, data visualization, datawrangling, machine learning, and everything essential to learning data science.
They offer the ability to challenge one’s knowledge and get hands-on practice to boost their skills in areas, including, but not limited to, exploratory data analysis, data visualization, datawrangling, machine learning, and everything essential to learning data science.
McKinney, Python for Data Analysis: DataWrangling with Pandas, NumPy, and IPython, 2nd ed., NaturalLanguageProcessing with Python — Analyzing Text with the NaturalLanguage Toolkit. Mirjalili, Python Machine Learning, 2nd ed. Packt, ISBN: 978–1787125933, 2017. Klein, and E. Jurafsky and J.
More confirmed sessions include Introduction to Large Lange Models (LLMs) | ODSC Instructor Introduction to Data Course | Sheamus McGovern | CEO and Software Architect, Data Engineer, and AI expert | ODSC Advanced NLP: Deep Learning and Transfer Learning for NaturalLanguageProcessing | Dipanjan (DJ) Sarkar | Lead Data Scientist | Google Developer (..)
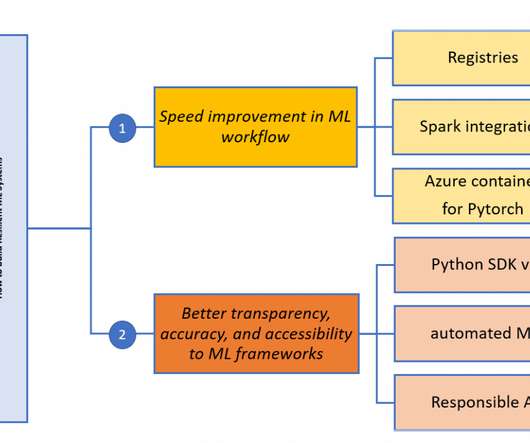
This new feature enables you to run large datawrangling operations efficiently, within Azure ML, by leveraging Azure Synapse Analytics to get access to an Apache Spark pool. Another recent announcement, also still in public preview, is the integration of Spark with Azure ML.
5. Text Analytics and NaturalLanguageProcessing (NLP) Projects: These projects involve analyzing unstructured text data, such as customer reviews, social media posts, emails, and news articles. NLP techniques help extract insights, sentiment analysis, and topic modeling from text data.
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wranglingprocesses with a fast and seamless user experience to manage and access data products.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, NaturalLanguageProcessing , Statistics and Mathematics. It can be easily ported to multiple platforms.
Learn data manipulation and analysis: Familiarize yourself with tools and techniques for data manipulation, exploration, and analysis. Common libraries in Python, such as pandas and NumPy, are essential for data cleaning, preprocessing, and transformation.
R’s machine learning capabilities allow for model training, evaluation, and deployment. · Text Mining and NaturalLanguageProcessing (NLP): R offers packages such as tm, quanteda, and text2vec that facilitate text mining and NLP tasks.
Leaving aside the more established skills here’s a visual look at the newer skills NaturalLanguageProcessing (NLP), Tokenization, Transformers, Representation Learning and Knowledge Graphs NLP (NaturalLanguageProcessing) The NLP engineer can be considered a precursor to the Promt Engineer.
Explore topics such as regression, classification, clustering, neural networks, and naturallanguageprocessing. Data Manipulation and Preprocessing Proficiency in data preprocessing techniques, feature engineering, and datawrangling to ensure the quality and reliability of input data.
D Data Mining : The process of discovering patterns, insights, and knowledge from large datasets using various techniques such as classification, clustering, and association rule learning. DataWrangling: The cleaning, transforming, and structuring of raw data into a format suitable for analysis.
The Early Years: Laying the Foundations (20152017) In the early years, data science conferences predominantly focused on foundational topics like data analytics , visualization , and the rise of big data. The Deep Learning Boom (20182019) Between 2018 and 2019, deep learning dominated the conference landscape.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content