This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
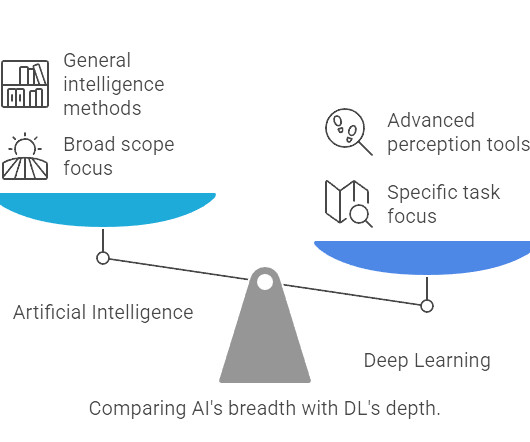
Summary: Artificial Intelligence (AI) and DeepLearning (DL) are often confused. AI vs DeepLearning is a common topic of discussion, as AI encompasses broader intelligent systems, while DL is a subset focused on neural networks. Is DeepLearning just another name for AI? Is all AI DeepLearning?
Summary: MachineLearning and DeepLearning are AI subsets with distinct applications. Introduction In todays world of AI, both MachineLearning (ML) and DeepLearning (DL) are transforming industries, yet many confuse the two. What is DeepLearning? billion by 2034.
A World of Computer Vision Outside of DeepLearning Photo by Museums Victoria on Unsplash IBM defines computer vision as “a field of artificial intelligence (AI) that enables computers and systems to derive meaningful information from digital images, videos and other visual inputs [1].”
Machinelearning models: Machinelearning models, such as supportvectormachines, recurrent neural networks, and convolutional neural networks, are used to predict emotional states from the acoustic and prosodic features extracted from the voice.
These videos are a part of the ODSC/Microsoft AI learning journe y which includes videos, blogs, webinars, and more. How Deep Neural Networks Work and How We Put Them to Work at Facebook Deeplearning is the technology driving today’s artificial intelligence boom.
This blog will cover the benefits, applications, challenges, and tradeoffs of using deeplearning in healthcare. Computer Vision and DeepLearning for Healthcare Benefits Unlocking Data for Health Research The volume of healthcare-related data is increasing at an exponential rate.
Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. They’re also part of a family of generative learning algorithms that model the input distribution of a given class or/category.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deeplearning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
Classification algorithms like supportvectormachines (SVMs) are especially well-suited to use this implicit geometry of the data. This approach consists of the following parameters: Model definition We define a sequential deeplearning model using the Keras library from TensorFlow.
With advances in machinelearning, deeplearning, and natural language processing, the possibilities of what we can create with AI are limitless. Develop AI models using machinelearning or deeplearning algorithms. How to create an artificial intelligence?
Unlike structured data, which resides in databases and spreadsheets, unstructured data poses challenges due to its complexity and lack of standardization. MachineLearning algorithms, including Naive Bayes, SupportVectorMachines (SVM), and deeplearning models, are commonly used for text classification.
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Students should learn about Spark’s core concepts, including RDDs (Resilient Distributed Datasets) and DataFrames.
websites, social media platforms, customer surveys, online reviews, emails and/or internal databases). Machinelearning algorithms like Naïve Bayes and supportvectormachines (SVM), and deeplearning models like convolutional neural networks (CNN) are frequently used for text classification.
By analyzing historical data and utilizing predictive machinelearning algorithms like BERT, ARIMA, Markov Chain Analysis, Principal Component Analysis, and SupportVectorMachine, they can assess the likelihood of adverse events, such as hospital readmissions, and stratify patients based on risk profiles.
Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane. Neural networks are the foundation of DeepLearning techniques.
By combining data from mass spectrometry experiments and sequence databases, researchers can identify and characterize proteins, understand their functions, and explore their interactions with other molecules. Deeplearning, a subset of machinelearning, has revolutionized image analysis in bioinformatics.
Several constraints were placed on selecting these instances from a larger database. Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machinelearning, and deeplearning practitioners.
Be aware that pip is probably what you should use if you’re installing packages directly into a Colab notebook or another environment that makes use of virtual machines. !pip We’re committed to supporting and inspiring developers and engineers from all walks of life. pip install comet_ml — or — !conda You can get the dataset here.
Another example can be the algorithm of a supportvectormachine. Hence, we have various classification algorithms in machinelearning like logistic regression, supportvectormachine, decision trees, Naive Bayes classifier, etc. What is deeplearning?
Structured data refers to neatly organised data that fits into tables, such as spreadsheets or databases, where each column represents a feature and each row represents an instance. This data can come from databases, APIs, or public datasets. For unSupervised Learning tasks (e.g., For instance: For a classification problem (e.g.,
Overview Vector Embedding 101: The Key to Semantic Search Vector indexing: when you have millions or more vectors, searching through them would be very tedious without indexing. OpenAI’s Embedding Model With VectorDatabase OpenAI updated in December 2022 the Embedding model to text-embedding-ada-002. lower price.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
Moving the machinelearning models to production is tough, especially the larger deeplearning models as it involves a lot of processes starting from data ingestion to deployment and monitoring. It provides different features for building as well as deploying various deeplearning-based solutions.
The e1071 package provides a suite of statistical classification functions, including supportvectormachines (SVMs), which are commonly used for spam detection. Naive Bayes, according to Nagesh Singh Chauhan in KDnuggets, is a straightforward machinelearning technique that uses Bayes’ theorem to create predictions.
For example, SupportVectorMachines are not probabilistic, but they are still used for Discriminative AI by finding a decision boundary in the space. On the other hand, with Generative AI it is generally safe to say that we are modeling a joint distribution because the distribution itself is the object of interest.
Object detection works by using machinelearning or deeplearning models that learn from many examples of images with objects and their labels. In the early days of machinelearning, this was often done manually, with researchers defining features (e.g., So, what does the MNIST database look like?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content