This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s a guide to choosing the right vector embedding model Importance of Vector Databases in Vector Search Vector databases are the backbone of efficient and scalable vector search. Scalability As datasets grow larger, traditional databases struggle to handle the complexity of vector searches.
⚡️Open-source LangChain-like AI knowledge database with web UI and Enterprise SSO⚡️, supports OpenAI, Azure, HuggingFace, OpenRouter, ChatGLM and local models, chat demo: [link] admin portal demo: [link] - GitHub - casibase/casibase: ⚡️Open-source LangChain-like AI knowledge database with web UI and Enterprise SSO⚡️, supports OpenAI, Azure, HuggingFace, (..)
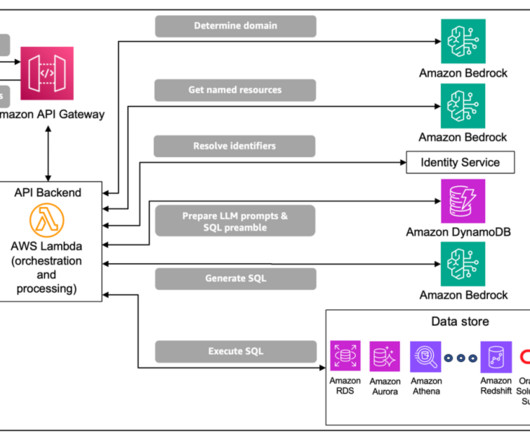
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
Recapping the Cloud Amplifier and Snowflake Demo The combined power of Snowflake and Domo’s Cloud Amplifier is the best-kept secret in data management right now — and we’re reaching new heights every day. If you missed our demo, we dive into the technical intricacies of architecting it below. Instagram) used in the demo Why Snowflake?
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities.
Each of these demos can be adapted to a number of industries and customized to specific needs. You can also watch the complete library of demos here. Output structured data is stored in a database, accessible for reporting or downstream applications. Watch the smart call center analysis app demo.
Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. This talk will introduce you to the fundamentals of large language models and its emerging architectures.
On Tuesday, cybersecurity expert Alexander Hagenah unveiled a demo tool that illustrates how malware can effortlessly exploit the saved data within the Recall function. “The database is unencrypted. Beaumont noted that Recall saves information in a readily accessible database within the user’s AppData folder.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The following demo shows Agent Creator in action. Chunker Snap – Segments large texts into manageable pieces.
TL;DR Vector databases play a key role in Retrieval-Augmented Generation (RAG) systems. After reading this article, you’ll know different ways to use vector databases to enhance the task performance of LLM-based systems. Vector Database: A database purpose-built for handling storage and retrieval of vectors.
Visualizing graph data doesn’t necessarily depend on a graph database… Working on a graph visualization project? You might assume that graph databases are the way to go – they have the word “graph” in them, after all. Do I need a graph database? It depends on your project. Unstructured? Under construction?
It works beautifully when you demo it to your friends. The typical rookie setup goes something like this: The user types something straight into OpenAIs API The response comes back straight to the user Every single message dumped into your database Seems logical enough, right? Your database will thank you.
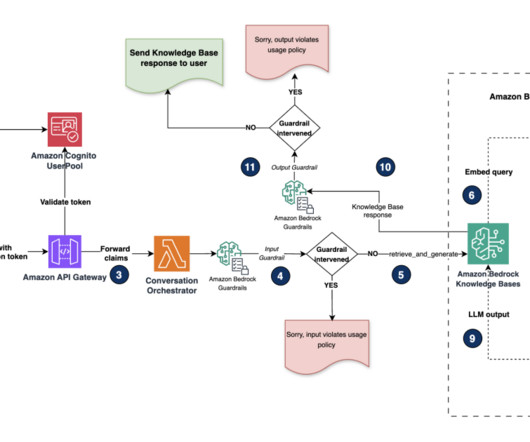
The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information. Use database functions for searches and compatibility checks. The following diagram illustrates the workflow of the agent. Assist with partial information.
Now, with a letter circulating that asks AI researchers to pause development and with YC demo day next week, we decided to see if that checks out. Ninety-one startups, or 34%, of the current YC class list that they are an AI company or use AI in some kind of way, according to the accelerator’s handy online database.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. Under Quick setup settings , for Name , enter a name (for example, demo). For Project name , enter a name (for example, demo). Expand your database starting from glue_db_. Choose Continue. option("multiLine", "true").option("header",
Instead of relying solely on their pre-trained knowledge, RAG allows models to pull data from documents, databases, and more. This means that as new data becomes available, it can be added to the retrieval database without needing to retrain the entire model. Memory efficiency – LLMs require significant memory to store parameters.
This setup happens once per toolset and is stored in a database. Each Nuclio function loads the appropriate model from Iguazio, performs inference, and sends results to a database or stream, or back to RabbitMQ for factory control actions. In the end, inference results are consolidated and written to a database.
Database name : Enter dev. Database user : Enter awsuser. Enter the following details to establish your Amazon Redshift connection : Cluster Identifier : Copy the ProducerClusterName from the CloudFormation nested stack outputs. Unload IAM Role ARN : Copy the RedshiftDataSharingRoleName from the nested stack outputs.
A major bottleneck to getting value from a Snowflake Data Cloud environment is creating the databases, schemas, roles, and access grants that make up an ‘information architecture’. The Provision tool is available for everyone to try and demo at a small scale and is available to all phData customers for free without limitations.
In my experience, there are two types of B2C new customers: A True new customer: A customer with no existing account in the company database. This led to crafting a solution that can be summarized in two steps: Using LLM to find semantic similarity between customer details in the database as soon as a customer registers.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps? And if you want to see demos of some of this functionality, be sure to join us for the livestream of the Citus 12.0 Updates page. Let’s dive in!
Each month, our Developer Platform team pulls back the curtain on recent work to support our developer community during the monthly Tableau Developer Program Sprint Demos. To benefit from this new file format, which handles database files more efficiently after rows are deleted, opt-in with the January Hyper API release.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Run the Streamlit demo Now that you have the components in place and the invoices processed using Amazon Bedrock, it’s time to deploy the Streamlit application. or python -m streamlit run review-invoice-data.py
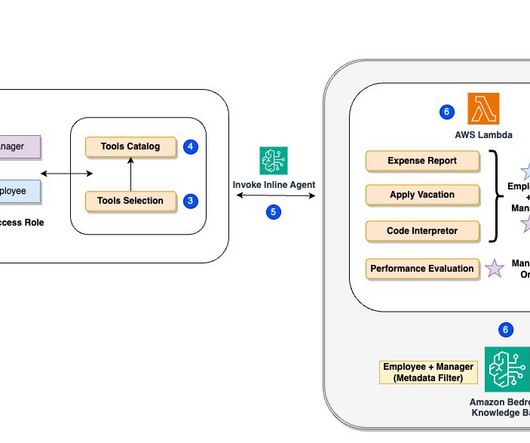
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. To get started, explore our GitHub repo and HR assistant demo application , which demonstrate key implementation patterns and best practices.
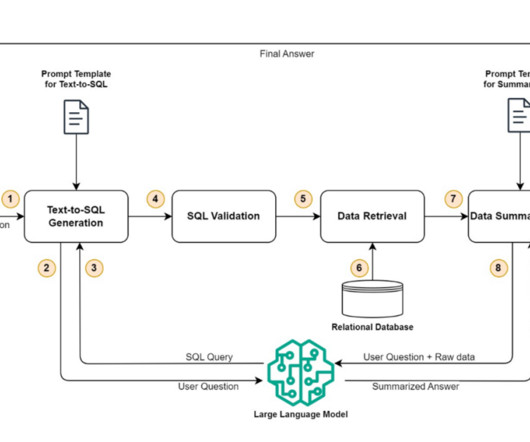
Text-to-SQL generation This step takes the user’s questions as input and converts that into a SQL query that can be used to retrieve the claim- or benefit-related information from a relational database. Data retrieval After the query has been validated, it is used to retrieve the claims or benefits data from a relational database.
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. AWS ran a live demo to show how to get started in just a few clicks. Where can I provide feedback?
Grab one for access to Keynote Talks, Demo Talks, the AI Expo and Demo Hall, and Extra Events. Find Your AI Solutions at the ODSC West AI Expo Learn about the best AI solutions for your organization at the ODSC West AI Expo & Demo Hall during these Demo Theater sessions! Attend in-person or virtually! Learn more here!
Using large language models akin to ChatGPT, he built a free-form question-answering bot on top of a CrunchBase database of investors, companies and fundraising rounds. For another demo, Van Haren fine-tuned OpenAI’s GPT-3 language model on a dataset of over 6.5 Van Haren gave examples from his own experimentation.
A demo app showcasing the functionality of the component is also deployed in Streamlit community cloud! The token handling service, simulated through a set of functions, allows for creating, deleting, and renaming tokens within a database (represented as a list of dictionaries in this case).
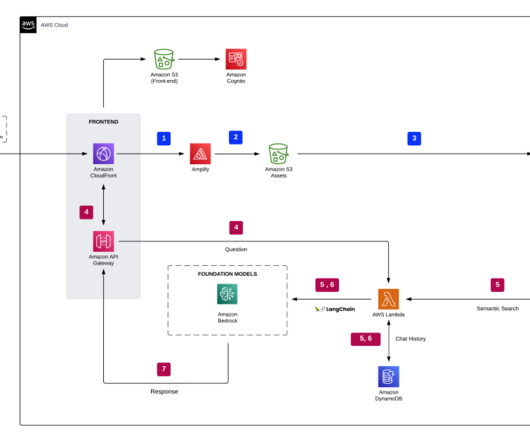
The high-level steps are as follows: For our demo , we use a web application UI built using Streamlit. The following diagram illustrates how RBAC works with metadata filtering in the vector database. The web application launches with a login form with user name and password fields. The user enters the credentials and logs in.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Finally, select your read preference.
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. These models are the technology behind Open AI’s DALL-E and GPT-3 , and are powerful enough to understand natural language commands and generate high-quality code to instantly query databases.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
It is also called the second brain as it can store data that is not arranged according to a present data model or schema and, therefore, cannot be stored in a traditional relational database or RDBMS. It has an official website from which you can access the premium version of Quivr by clicking on the button ‘Try demo.’
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. Another boon for efficient work that SQL provides is its simple and consistent syntax that allows for collaboration across multiple databases.
Pinecone is one of the most popular vector database frameworks. A vector database is a type of database that is specifically designed to store and retrieve vector data efficiently. It does this by providing a framework for connecting LLMs to other sources of data, such as the internet or your personal files.
The general perception is that you can simply feed data into an embedding model to generate vector embeddings and then transfer these vectors into your vector database to retrieve the desired results. how to perform a vector search Many vector database providers promote their capabilities with descriptors like easy, user-friendly, and simple.
Linking to demos so that you can also review them yourself Have you been finding the leaps of AI in the last past years impressive? Biology We provide links to all currently available demos: many of this year’s inventions come with a demo that allows you to personally interact with a model. Text-to-Image generation ?
It is geared toward experimentation and quick deployments, making it a popular choice for demos and non-technical users exploring AI agent behavior in a visual environment. CrewAI Use case: Multi-agent collaboration Key Features: Role-based agent assignments (e.g.,
Garman expressed to TechCrunch that while generative AI will be a major focus, re:Invent will showcase innovations across the entire AWS stack, including compute, storage, and databases. The AWS Builders Fair will highlight projects developed by AWS experts, partners, and customers.
The appropriate databases are also decided upon in this stage. Each feature is called a User Story and each story has three features – Importance, Estimate, and Demo. Testing and Demo: Here the developers test the software, release the demo, and fix the bugs to ensure a satisfactory product for the client.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content