This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s a guide to choosing the right vector embedding model Importance of Vector Databases in Vector Search Vector databases are the backbone of efficient and scalable vector search. Scalability As datasets grow larger, traditional databases struggle to handle the complexity of vector searches.
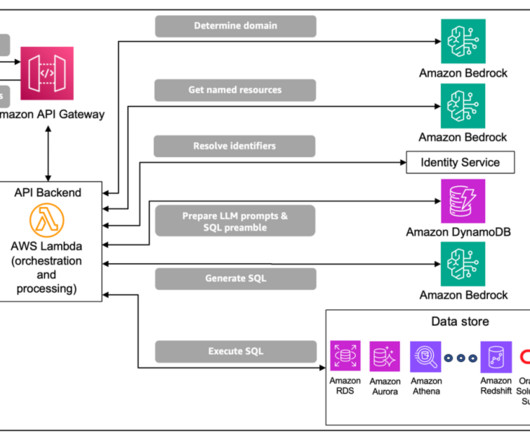
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Database name : Enter dev. Choose Add connection.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
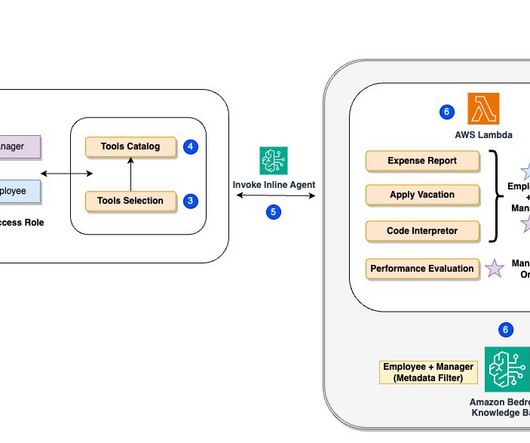
The high-level steps are as follows: For our demo , we use a web application UI built using Streamlit. The following diagram illustrates how RBAC works with metadata filtering in the vector database. When hes not advancing ML workloads, Praveen can be found immersed in books or enjoying science fiction films. Brandon Rooks Sr.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. To get started, explore our GitHub repo and HR assistant demo application , which demonstrate key implementation patterns and best practices.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The following demo shows Agent Creator in action. Chunker Snap – Segments large texts into manageable pieces.
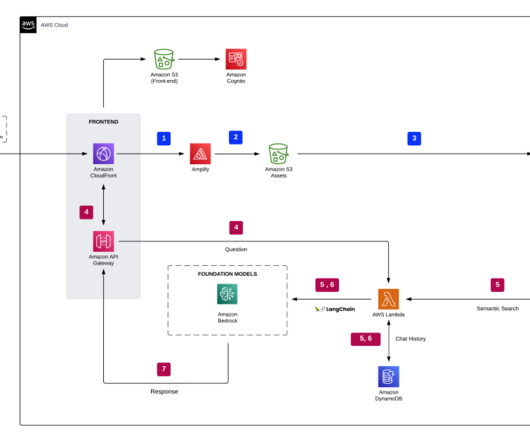
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
You can hear more details in the webinar this article is based on, straight from Kaegan Casey, AI/ML Solutions Architect at Seagate. Iguazio allows sharing projects between diverse teams, provides detailed logging of parameters, metrics, and ML artifacts and allows for artifact versioning including labels, tags, associated data etc.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
TL;DR Vector databases play a key role in Retrieval-Augmented Generation (RAG) systems. Further, talking to data scientists and ML engineers, I noticed quite a bit of confusion around RAG systems and terminology. Vector Database: A database purpose-built for handling storage and retrieval of vectors.
Instead of relying solely on their pre-trained knowledge, RAG allows models to pull data from documents, databases, and more. This means that as new data becomes available, it can be added to the retrieval database without needing to retrain the entire model. Memory efficiency – LLMs require significant memory to store parameters.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
The brand-new Forecasting tool created on Snowflake Data Cloud Cortex ML allows you to do just that. What is Cortex ML, and Why Does it Matter? Cortex ML is Snowflake’s newest feature, added to enhance the ease of use and low-code functionality of your business’s machine learning needs.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired. Release v1.0
Embeddings play a key role in natural language processing (NLP) and machine learning (ML). This technique is achieved through the use of ML algorithms that enable the understanding of the meaning and context of data (semantic relationships) and the learning of complex relationships and patterns within the data (syntactic relationships).
Generative AI is by no means a replacement for the previous wave of AI/ML (now sometimes referred to as ‘traditional AI/ML’), which continues to deliver significant value, and represents a distinct approach with its own advantages. In the end, we explain how MLOps can help accelerate the process and bring these models to production.
Grab one for access to Keynote Talks, Demo Talks, the AI Expo and Demo Hall, and Extra Events. Find Your AI Solutions at the ODSC West AI Expo Learn about the best AI solutions for your organization at the ODSC West AI Expo & Demo Hall during these Demo Theater sessions! Attend in-person or virtually!
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. In this article, we will explore the various aspects of Deepchecks and how it can revolutionize the way we validate and maintain ML models.
As AI systems grow more complex, combining ML models, LLMs, and open-source tools into Composite AI, ensuring reliability is mission-critical. Perfect for ML/AI engineers aiming to build robust, production-grade LLM systems across chatbots, RAG, and enterprise apps.
It is also called the second brain as it can store data that is not arranged according to a present data model or schema and, therefore, cannot be stored in a traditional relational database or RDBMS. It has an official website from which you can access the premium version of Quivr by clicking on the button ‘Try demo.’
Amazon SageMaker Studio offers a comprehensive set of capabilities for machine learning (ML) practitioners and data scientists. These include a fully managed AI development environment with an integrated development environment (IDE), simplifying the end-to-end ML workflow.
This solution employs machine learning (ML) for anomaly detection, and doesn’t require users to have prior AI expertise. The application, once deployed, constructs an ML model using the Random Cut Forest (RCF) algorithm. He is dedicated to making ML and generative AI more accessible and applying them to solve challenging problems.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody. Everybody can train a model.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody. Everybody can train a model.
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications. Additionally, compliance requirements and evolving regulations (e.g.
In November 2022, we announced that AWS customers can generate images from text with Stable Diffusion models in Amazon SageMaker JumpStart , a machine learning (ML) hub offering models, algorithms, and solutions. When it comes to building the essential vector database, AWS provides a multitude of options through their native services.
Amazon SageMaker Studio Lab provides no-cost access to a machine learning (ML) development environment to everyone with an email address. Therefore, you can scale your ML experiments beyond the free compute limitations of Studio Lab and use more powerful compute instances with much bigger datasets on your AWS accounts.
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. AWS ran a live demo to show how to get started in just a few clicks. Where can I provide feedback? 4. . Amazon RDS
Some of these solutions use common machine learning (ML) models built on historical interaction patterns, user demographic attributes, product similarities, and group behavior. Amazon Personalize enables developers to build applications powered by the same type of ML technology used by Amazon.com for real-time personalized recommendations.
TL;DR Using CI/CD workflows to run ML experiments ensures their reproducibility, as all the required information has to be contained under version control. The compute resources offered by GitHub Actions directly are not suitable for larger-scale ML workloads. ML experiments are, by nature, full of uncertainty and surprises.
These controllers allow Kubernetes users to provision AWS resources like buckets, databases, or message queues simply by using the Kubernetes API. About the Authors Rajesh Ramchander is a Principal ML Engineer in Professional Services at AWS. Release v1.2.9 They are also supported by AWS CloudFormation.
Evaluating LLMs is an undervalued part of the machine learning (ML) pipeline. Dataset The MIMIC Chest X-ray (MIMIC-CXR) Database v2.0.0 Context is providing relevant background to ensure the model understands the task or query, such as the schema of a database in the example of natural language querying.
Create two users in your Box account For this example, you need two demo users in your Box account in addition to the admin user. Complete the following steps to create these two demo users, using the same email addresses you used when setting up these users in IAM Identity Center: Log in to your Box Enterprise Admin Console as an admin user.
The Essential Tools for ML Evaluation and Responsible AI There are lots of checkmarks to hit when developing responsible AI, but thankfully, there are many tools for ML evaluation and frameworks designed to support responsible AI development and evaluation.
In the application pipeline, teams can swap: Logging inputs + responses to various data sources (database, stream, file, etc.) Classical ML models and LLMs If using QLORA to fine-tune, teams can swap out domain specific fine tuned adapters while using the same base model (e.g. Additional data sources (RAG, web search, etc.)
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
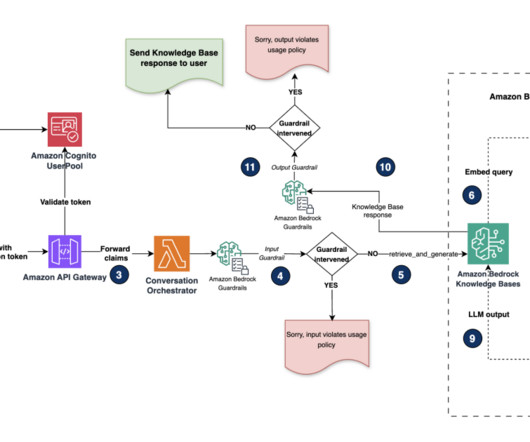
Knowledge Bases is completely serverless, so you don’t need to manage any infrastructure, and when using Knowledge Bases, you’re only charged for the models, vector databases and storage you use. Build a knowledge base for Amazon Bedrock In this section, we demo the process of creating a knowledge base for Amazon Bedrock via the console.
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. Another boon for efficient work that SQL provides is its simple and consistent syntax that allows for collaboration across multiple databases.
This international gathering of practitioners brought together an impressive array of minds striving to advance the science of deploying Machine Learning (ML) and AI models into production. The session included a demo on running a vLLM server for your own large language model (LLM) inference service using Modal.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content