This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities.
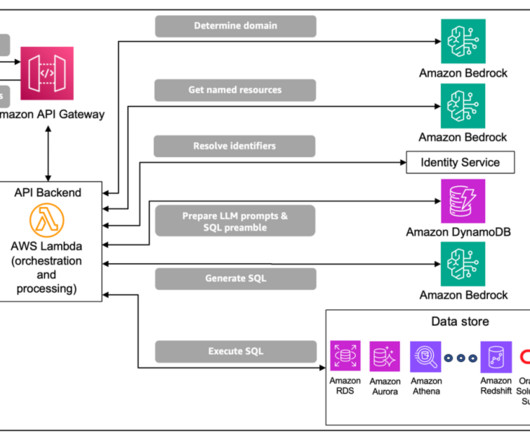
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
and other large language models (LLMs) have transformed naturallanguageprocessing (NLP). Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more.
To address this, the company decides to build a GraphRAG application using Amazon Bedrock Knowledge Bases , usign the graph databases to represent complex relationships within the data. Data exploration : With the graph database populated, users can quickly explore the data using Graph Explorer. Select Data source as Amazon S3.
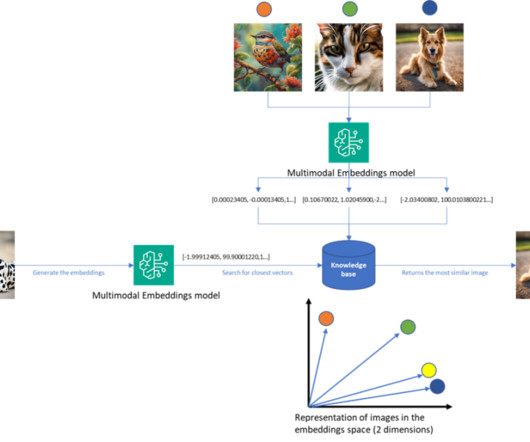
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. The example matches a user’s query to the closest entries in an in-memory vector database.
It is also called the second brain as it can store data that is not arranged according to a present data model or schema and, therefore, cannot be stored in a traditional relational database or RDBMS. It has an official website from which you can access the premium version of Quivr by clicking on the button ‘Try demo.’
Instead of relying solely on their pre-trained knowledge, RAG allows models to pull data from documents, databases, and more. This means that as new data becomes available, it can be added to the retrieval database without needing to retrain the entire model. Memory efficiency – LLMs require significant memory to store parameters.
Retrieval Augmented Generation (RAG) is a process in which a language model retrieves contextual documents from an external data source and uses this information to generate more accurate and informative text. This technique is particularly useful for knowledge-intensive naturallanguageprocessing (NLP) tasks.
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. It is the latest in the research lab’s lineage of large language models using Generative Pre-trained Transformer (GPT) technology. Like its predecessors, ChatGPT generates text in a variety of styles, for a variety of purposes.
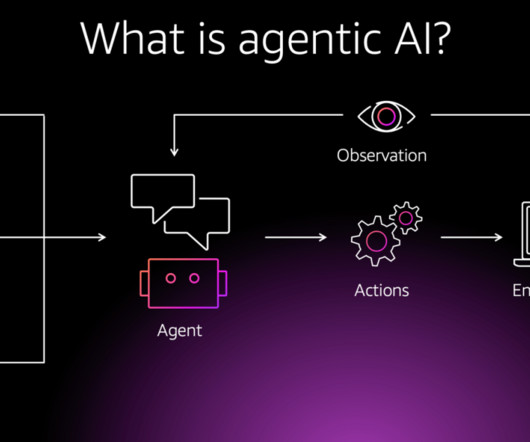
An agent uses a function call to invoke an external tool (like an API or database) to perform specific actions or retrieve information it doesnt possess internally. FastMCP is used for rapid prototyping, educational demos, and scenarios where development speed is a priority. Lets understand the difference between both.
Solution overview The AI-powered asset inventory labeling solution aims to streamline the process of updating inventory databases by automatically extracting relevant information from asset labels through computer vision and generative AI capabilities. It invokes the API to process the data.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing.
Linking to demos so that you can also review them yourself Have you been finding the leaps of AI in the last past years impressive? Language generation ? Biology We provide links to all currently available demos: many of this year’s inventions come with a demo that allows you to personally interact with a model.
Generative language models have proven remarkably skillful at solving logical and analytical naturallanguageprocessing (NLP) tasks. We use Cohere Command and AI21 Labs Jurassic-2 Mid for this demo. DynamoDB table An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database.
Using NLP (NaturalLanguageProcessing), OpenAI was also able to create personalized learning content for different students, helping everyone to learn in their own way and at their own pace. Early tests of OpenAI in these environments were conducted at Stanford and Harvard, and boasted very positive impacts.
These tools allow agents to interact with APIs, access databases, execute scripts, analyze data, and even communicate with other external systems. With CrewAI Agents, you can streamline the entire process, automatically mapping your resources, analyzing configurations, and generating clear, prioritized remediation steps.
Interact with several demos that feature new applications, including a competition that involves using generative AI tech to pilot a drone around an obstacle course. Embeddings can be stored in a database and are used to enable streamlined and more accurate searches. Generative AI is at the heart of the AWS Village this year.
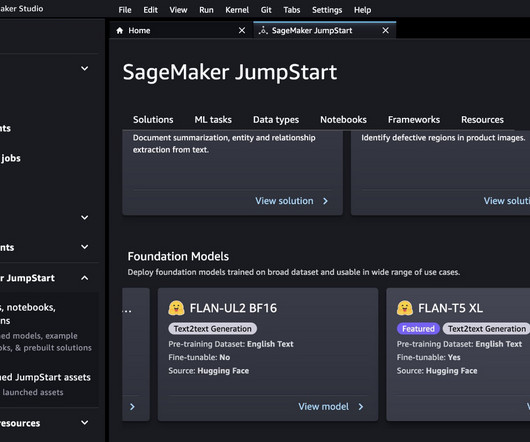
job name: jumpstart-demo-xl-3-2023-04-06-08-16-42-738 INFO:sagemaker:Creating training-job with name: jumpstart-demo-xl-3-2023-04-06-08-16-42-738 When the training is complete, you have a fine-tuned model at model_uri. Let’s use it! We recommend Amazon EBS for data that must be quickly accessible and requires long-term persistence.
To ensure security and JSON/pickle benefits, you can save your model to a dedicated database. Next, you will see how you can save an ML model in a database. Storing ML models in a database There is also scope for you to save your ML models in relational databases PostgreSQL , MySQL , Oracle SQL , etc.
Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g. He also boasts several years of experience with NaturalLanguageProcessing (NLP). I posit these would signal key ideas in each paper.
Knowledge Bases is completely serverless, so you don’t need to manage any infrastructure, and when using Knowledge Bases, you’re only charged for the models, vector databases and storage you use. RAG is a popular technique that combines the use of private data with large language models (LLMs). md) HyperText Markup Language (.html)
In this series, we will set up AWS OpenSearch , which will serve as a vector database for a semantic search application that well develop step by step. Figure 2 : Amazon OpenSearch Service for Vector Search: Demo Key Features of AWS OpenSearch Scalability: Easily scale clusters up or down based on workload demands.
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and naturallanguageprocessing (NLP) tasks since 2010. Choose the link with the following format to open the demo: [link].
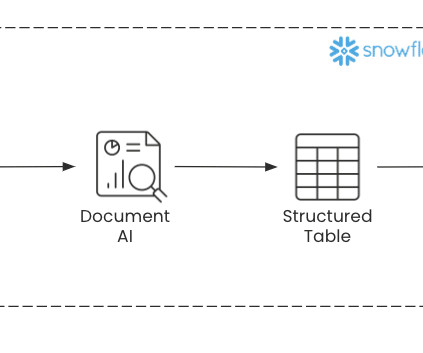
Snowflake Solution In the past, companies would hire employees whose focus was scanning, entering, and correcting data from documents into an organized table or database. Even with advancements offered by document scanning technology or expensive custom software to process an organization’s unique form, these solutions still aren’t ideal.
For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules. In this demo, we use a Jumpstart Flan T5 XXL model endpoint.
This is a guest post by Wah Loon Keng , the author of spacy-nlp , a client that exposes spaCy ’s NLP text parsing to Node.js (and other languages) via Socket.IO. NaturalLanguageProcessing and other AI technologies promise to let us build applications that offer smarter, more context-aware user experiences. CLI: 2.4.0,
We benchmark the results with a metric used for evaluating summarization tasks in the field of naturallanguageprocessing (NLP) called Recall-Oriented Understudy for Gisting Evaluation (ROUGE). Dataset The MIMIC Chest X-ray (MIMIC-CXR) Database v2.0.0 It is time-consuming but, at the same time, critical.
Using techniques that include artificial intelligence (AI) , machine learning (ML) , naturallanguageprocessing (NLP) and network analytics, it generates a master inventory of sensitive data down to the PII or data-element level.
This is where the content for the demo solution will be stored. For the demo solution, choose the default ( Claude V3 Sonnet ). For the hotel-bot demo, try the default of 4. In the Choose your table window, choose your database, select your lex_conversation_logs table, and choose Edit/Preview data.
Usually, when a new entry for an inbound client is formed, an email is sent to greet them and to introduce the suggestion of booking a product demo. Automate and customize interactions: Take advantage of the information you’ve gathered in your customer database to nurture leads and increase revenue. Handle RFP generation.
They designed new approaches and technologies for large-scale data analysis of communications records, open-source intelligence (OSINT), and police databases. This chart uses the time bar to offer a dynamic view of what happened when: Exploring the VERIS database with a graph and timeline visualization.
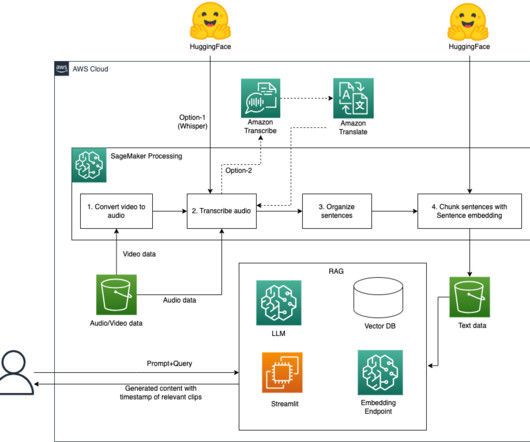
Generative AI, particularly in the realm of naturallanguageprocessing and understanding (NLP and NLU), has revolutionized the way we comprehend and analyze text, enabling us to gain deeper insights efficiently and at scale. Load the processed video transcripts using the LangChain document loader and create an index.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Dolt Dolt is an open-source relational database system built on Git.
DL is particularly effective in processing large amounts of unstructured data, such as images, audio, and text. NaturalLanguageProcessing (NLP) : NLP is a branch of AI that deals with the interaction between computers and human languages.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. In this post, we present a new version of the library, new vectors, new evaluation recipes, and a demo NER project that we trained to usable accuracy in just a few hours.
Bard Google’s code name for its chat-oriented search engine, based on their LaMDA model, and only demoed once in public. 2 However, you don’t need to know how Transformers work to use large language models effectively, any more than you need to know how a database works to use a database. O’Reilly, 2022).
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Streamlining Government Regulatory Responses with NaturalLanguageProcessing, GenAI, and Text Analytics Through text analytics, linguistic rules are used to identify and refine how each unique statement aligns with a different aspect of the regulation.
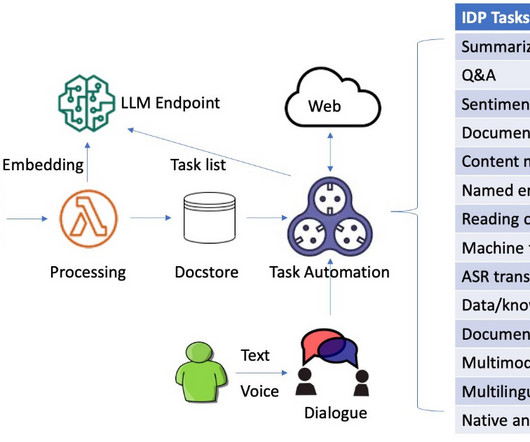
Naturallanguageprocessing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience. Finally, we store these vectors in a vector database for similarity search. However, despite these advances, there are still challenges to overcome.
I have added a quick demo of the frontend interface I made for myself. I calculated the similarity matrix with the following function and then stored the events data along with the similarity and distance from the event into a MySQL database. """ # Convert coordinates to radians lon1, lat1 = radians(loc1.x),
AlphaFold , a protein folding prediction model for which a Nobel prize was recently awarded , can do work in hours that previously took years, and the AlphaFold Protein Structure Database makes all known protein structures freely available to all scientists. Simply being open source does not guarantee this kind of growth.
I don’t think we would have been able to write a paper about just “vector-database-plus-language-model.” Where we are right now in the field is that there’s been this kind of “demo disease,” as we call it at Contextual AI. Everybody wants to build a cool demo. Everybody wants to build a cool demo.
I don’t think we would have been able to write a paper about just “vector-database-plus-language-model.” Where we are right now in the field is that there’s been this kind of “demo disease,” as we call it at Contextual AI. Everybody wants to build a cool demo. Everybody wants to build a cool demo.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content