This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval.
Get a Demo DATA + AI SUMMIT JUNE 9–12 | SAN FRANCISCO Data + AI Summit is almost here — don’t miss the chance to join us in San Francisco! Modern development workflow : Branching a database should be as easy as branching a code repository, and it should be near instantaneous. REGISTER Ready to get started?
Get a Demo DATA + AI SUMMIT JUNE 9–12 | SAN FRANCISCO Data + AI Summit is almost here — don’t miss the chance to join us in San Francisco! REGISTER Ready to get started? This approach democratizes agent development, allowing domain experts to contribute directly to system improvement without deep technical expertise in AI infrastructure.
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL. But why is SQL, or Structured Query Language , so important to learn? Let’s start with the first clause often learned by new SQL users, the WHERE clause.
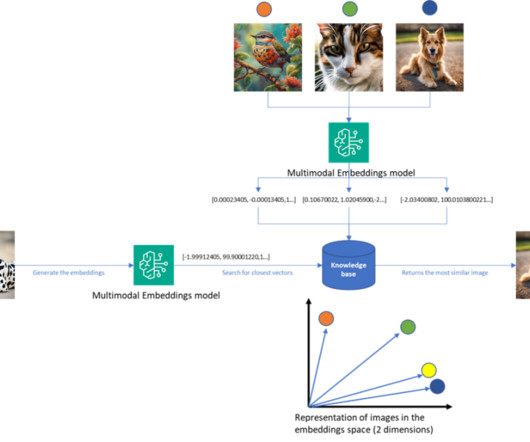
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
We also offer hosted and on-premise versions with OCR, extra metadata, all embedding providers, and managed vector databases for teams that want a fully managed pipeline. or book a demo: https://cal.com/shreyashn/chonkie-demo. 200k+ tokens) with many SQL snippets, query results and database metadata (e.g.
Data processing and SQL analytics Analyze, prepare, and integrate data for analytics and AI using Amazon Athena, Amazon EMR, AWS Glue, and Amazon Redshift. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. For Project name , enter a name (for example, demo).
For example, with MCP an AI model could fetch information from a database, edit a design in Figma, or control a music app all by sending natural-language instructions through a standardized interface. Heres a demo of me creating a low-poly dragon guarding treasure scene in just a few sentences Video: Siddharth Ahuja 2.
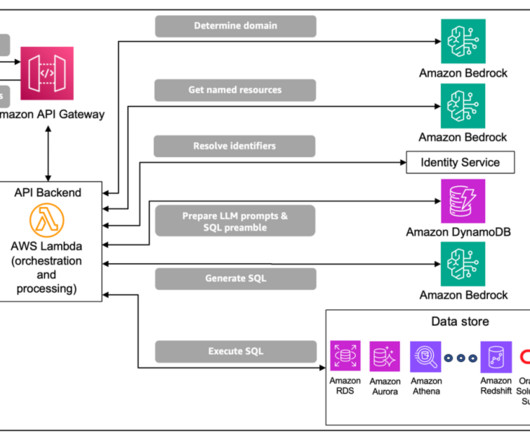
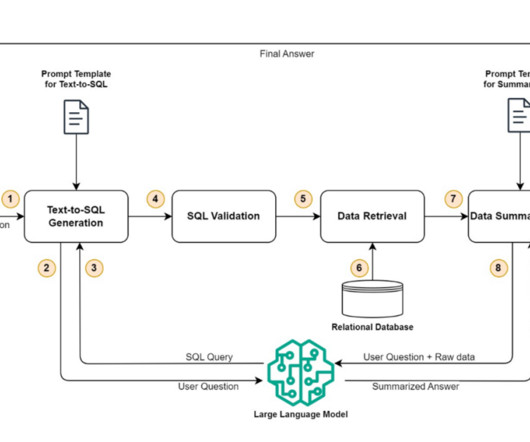
From a broad perspective, the complete solution can be divided into four distinct steps: text-to-SQL generation, SQL validation, data retrieval, and data summarization. A pre-configured prompt template is used to call the LLM and generate a valid SQL query. The following diagram illustrates this workflow.
You should have at least Contributor access to the workspace Download SQL Server Management Studio Step-by-Step Guide for Refreshing a Single Table in Power BI Semantic Model Using a demo data model, let’s walk through how to refresh a single table in a Power BI semantic model. Now, open SQL Server Management Studio (SSMS).
Essentially, the protocol ensures that whether an AI is talking to a design tool or a database, the handshake and query format are consistent. Services (applications/data sources) These are the actual apps, databases, or systems that the MCP servers interface with. The barrier to multistep, multisystem automation drops dramatically.
Basic knowledge of a SQL query editor. Database name : Enter dev. Database user : Enter awsuser. A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain. A QuickSight account (optional). Deploy the Cloudformation template to your account.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQLdatabases, Amazon CloudWatch logs, and third-party tools to check the live system health status. This removed a considerable amount of data in the ETL process even before ingesting into the knowledge base.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
Visualizing graph data doesn’t necessarily depend on a graph database… Working on a graph visualization project? You might assume that graph databases are the way to go – they have the word “graph” in them, after all. Do I need a graph database? It depends on your project. Unstructured? Under construction?
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. The wrapper function runs the SQL query using psycopg2.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Run the Streamlit demo Now that you have the components in place and the invoices processed using Amazon Bedrock, it’s time to deploy the Streamlit application.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps? And if you want to see demos of some of this functionality, be sure to join us for the livestream of the Citus 12.0 Updates page. Let’s dive in!
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
Solution overview The AI-powered asset inventory labeling solution aims to streamline the process of updating inventory databases by automatically extracting relevant information from asset labels through computer vision and generative AI capabilities. The function updates the asset inventory database with the new extracted data.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Topics include python fundamentals, SQL for data science, statistics for machine learning, and more. Deep Learning with Tensorflow 2 and Pytorch Originally recorded as a live training, this session serves as a primer on deep learning theory that will bring the revolutionary machine learning approach to life with hands-on demos.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Enter a stack name, such as Demo-Redshift. yaml locally. For Prepare template , select Template is ready.
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. AWS ran a live demo to show how to get started in just a few clicks. Where can I provide feedback?
It even met the stringent requirement I put on it: I asked it if it could avoid saving a token per user, and instead use the global private credentials of the app to drive everything to keep the database simple. I learned an odd way of using SQL at Tailscale (from Brad and Maisem): make every table a JSON object.
Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired. Release v1.0
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. These models are the technology behind Open AI’s DALL-E and GPT-3 , and are powerful enough to understand natural language commands and generate high-quality code to instantly query databases.
This hands-on workshop walks you through constructing adaptive retrieval pipelines, implementing feedback loops, and retraining models using open-source graph databases. Whether youre here for hands-on Jupyter demos or just to drop some buzzwords at your next meeting, youll walk away ready to rethink what RAG canbe.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. This allowed them to focus on SQL-based query optimization to the nth degree. They stood up a file-based data lake alongside their analytical database.
It exposes new interfaces for development in Python , Scala, or Java to supplement Snowflake’s original SQL interface. SQL is, of course, the lingua franca for data, but there are many applications and development teams that rely heavily on other languages. What’s New with Snowpark? ” Of course! conda create -n snowpark python=3.8
It exposes new interfaces for development in Python , Scala, or Java to supplement Snowflake’s original SQL interface. SQL is, of course, the lingua franca for data, but there are many applications and development teams that rely heavily on other languages. What’s New with Snowpark? ” Of course! conda create -n snowpark python=3.8
A business event is represented by a change in state of the data flowing between your applications, systems and databases and, most importantly, the time it occurred. A business event can describe anything that happens which is significant to an enterprise’s operation.
From there, ChatGPT generates a SQL query which is then executed in the Snowflake Data Cloud , and the results are brought back into the application in a table format. In this case, after the SQL query is executed on Snowflake, it is converted into a Python dataframe, and basic graphic code is executed to generate the image.
We’ve been focusing on two key areas: Microsoft SQL Server to Snowflake Data Cloud SQL translations and our new Advisor tool within the phData Toolkit. SQL Translation Updates When customers are looking to migrate between platforms, there’s always a challenge in migrating existing code. Let’s dive in.
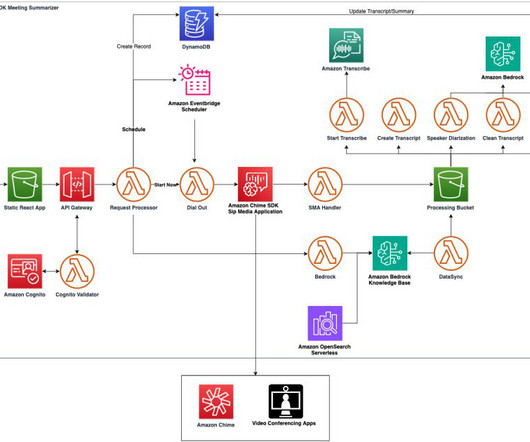
In this demo, an outbound call is made using the CreateSipMediaApplicationCall API. And what are you using for your database ? spk_1: Oh , yeah , for a database , we currently have a 200 gigabyte database running my as to will and I can’t remember the version. But um the thing about our database is sometimes it lags.
SQLDatabases might sound scary, but honestly, they’re not all that bad. And much of that is thanks to SQL (Structured Query Language). Believe it or not, SQL is about to celebrate its fiftieth birthday next year as it was first developed in 1974 as part of IBM’s System R Project. Learning is learning.
Over the last month, we’ve been heavily focused on adding additional support for SQL translations to our SQL Translations tool. Specifically, we’ve been introducing fixes and features for our Microsoft SQL Server to Snowflake translation. This is where the SQL Translation tool can be a massive accelerator for your migration.
With the help of SQL and R, this tool analyzes your data and turns it into pretty interactive dashboards within minutes. You can add time-based and custom filters, write SQL, get charts, and share dashboards with the team. Its analytics can integrate with different SQLdatabases and different data warehouses.
To ensure security and JSON/pickle benefits, you can save your model to a dedicated database. Next, you will see how you can save an ML model in a database. Storing ML models in a database There is also scope for you to save your ML models in relational databases PostgreSQL , MySQL , Oracle SQL , etc.
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. SQL excels with big data and statistics, making it important in order to query databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content