
NoSQL Databases and Their Use Cases
KDnuggets
MARCH 16, 2023
Learn about NoSQL Databases and their types like key-value, document, graph and column family with their use cases.

KDnuggets
MARCH 16, 2023
Learn about NoSQL Databases and their types like key-value, document, graph and column family with their use cases.

Analytics Vidhya
SEPTEMBER 14, 2023
Introduction Large Language Models like langchain and deep lake have come a long way in Document Q&A and information retrieval. However, a […] The post Ask your Documents with Langchain and Deep Lake! These models know a lot about the world, but sometimes, they struggle to know when they don’t know something.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Analytics Vidhya
SEPTEMBER 5, 2024
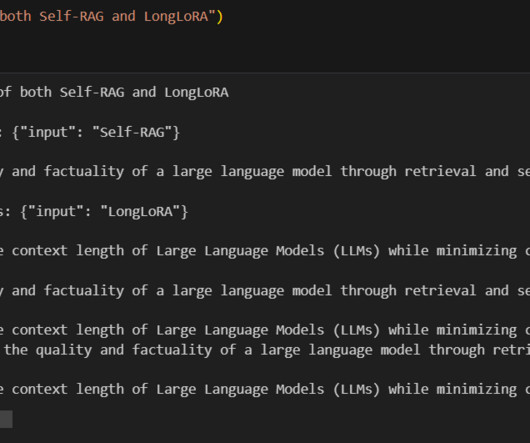
Enter Multi-Document Agentic RAG – a powerful approach that combines Retrieval-Augmented Generation (RAG) with agent-based systems to create AI that can reason across multiple documents.

Analytics Vidhya
NOVEMBER 5, 2023
One such groundbreaking approach is Retrieval Augmented Generation (RAG), which combines the power of generative models like GPT (Generative Pretrained Transformer) with the efficiency of vector databases and langchain.

Analytics Vidhya
NOVEMBER 21, 2023
Introduction Vector Databases have become the go-to place for storing and indexing the representations of unstructured and structured data. In the ever-evolving landscape of […] The post A Deep Dive into Qdrant, the Rust-Based Vector Database appeared first on Analytics Vidhya.

Analytics Vidhya
JULY 18, 2023
Among such tools, today we will learn about the workings and functions of ChromaDB, an open-source vector database to store embeddings from […] The post Build Semantic Search Applications Using Open Source Vector Database ChromaDB appeared first on Analytics Vidhya.

Analytics Vidhya
DECEMBER 13, 2022
Introduction MongoDB is a type of NoSQL Database, that stores data in document format(bson or binary json format). Its advantage over traditional SQL Databases includes the flexibility of schema-design, relaxation of its ACID properties and its distributed data storage capability thus performing better for […].

Expert insights. Personalized for you.



































Let's personalize your content