This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. Imagine a database with billions of samples ( ) (e.g., product specifications, movie metadata, documents, etc.)
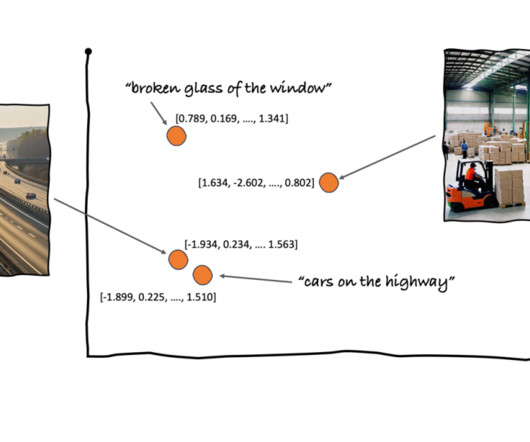
You can then run searches for the top Kdocuments in an index that are most similar to a given query vector, which could be a question, keyword, or content (such as an image, audio clip, or text) that has been encoded by the same ML model. To learn more, refer to the documentation.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
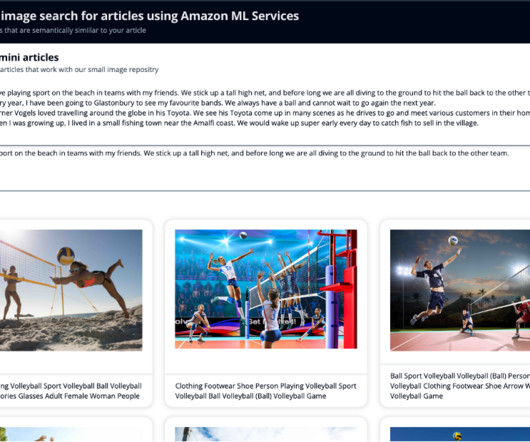
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. Display results : Display the top K similar results to the user. b64encode(resized_image).decode('utf-8')
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Set up the database access and network access.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. You will create a connector to SageMaker with Amazon Titan Text Embeddings V2 to create embeddings for a set of documents with population statistics. Examine the code in run_rag.py.
OpenSearch Service allows you to store vectors and other data types in an index, and offers rich functionality that allows you to search for documents using vectors and measuring the semantical relatedness, which we use in this post. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. The OSI pipeline ingests the data as documents into an OpenSearch Serverless index.
Home Table of Contents Approximate NearestNeighbor with Locality Sensitive Hashing (LSH) What Is Locality Sensitive Hashing (LSH)? Another example is in the field of text document similarity. Imagine you have a vast library of documents and want to identify near-duplicate documents or find documents similar to a query document.
We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. In the user interaction phase, a question from the user is converted into embeddings and a similarity search is run on the vector database to find a slide that could potentially contain answers to user question.
Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others. Association algorithms allow data scientists to identify associations between data objects inside large databases, facilitating data visualization and dimensionality reduction.
You can integrate existing data from AWS data lakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. The Asynchronous Request Handler function stores results in a DynamoDB database along with the generated requestId.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). You split the video files into frames and save them in a S3 bucket (Step 1).
OpenSearch Service offers kNN search, which can enhance search in use cases such as product recommendations, fraud detection, and image, video, and some specific semantic scenarios like document and query similarity. Solution overview.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. SlideVQA: A Dataset for Document Visual Question Answering on Multiple Images. 13636-13645.
Databases to be migrated can have a wide range of data representations and contents. For the sake of argument, let’s ignore the fact that the use of such data types in databases is justified only in a few specific cases, as this problem often arises when migrating complex systems. in XML, CLOB, BLOB etc.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content