This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning is the way of the future. Discover the importance of data collection, finding the right skill sets, performance evaluation, and security measures to optimize your next machinelearning project. Five tips for machinelearning projects – Data Science Dojo Let’s dive in.
Among such tools, today we will learn about the workings and functions of ChromaDB, an open-source vector database to store embeddings from […] The post Build Semantic Search Applications Using Open Source Vector Database ChromaDB appeared first on Analytics Vidhya.
10 Python packages for data science and machinelearning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machinelearning in Python.
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machinelearning applications.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
As a global leader in agriculture, Syngenta has led the charge in using data science and machinelearning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
Heres how embeddings power these advanced systems: Semantic Understanding LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Welcome to this comprehensive guide on Azure MachineLearning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machinelearning models. This is where Azure MachineLearning shines by democratizing access to advanced AI capabilities.
While Python and R are popular for analysis and machinelearning, SQL and database management are often overlooked. However, data is typically stored in databases and requires SQL or business intelligence tools for access. Through this guide, we give you a larger picture to get started with your database journey.
Artificial intelligence is no longer fiction and the role of AI databases has emerged as a cornerstone in driving innovation and progress. An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
RAG workflow: Converting data to actionable knowledge RAG consists of two major steps: Ingestion Preprocessing unstructured data, which includes converting the data into text documents and splitting the documents into chunks. Document chunks are then encoded with an embedding model to convert them to document embeddings.
What are Vector Databases? A new and unique type of database that is gaining immense popularity in the fields of AI and MachineLearning is the vector database. This is because vector embeddings are the only sort of data that a vector database is intended to store and retrieve.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
The documents uploaded to the knowledge base on the rack might be private and sensitive documents, so they wont be transferred to the AWS Region and will remain completely local on the Outpost rack. This vector database will store the vector representations of your documents, serving as a key component of your local Knowledge Base.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
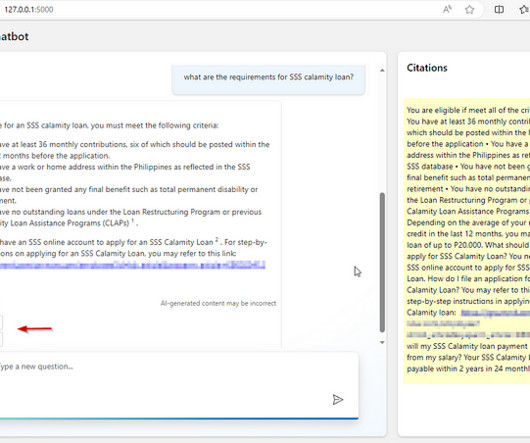
It works by storing text-based documents (that the LLM has no knowledge of) on an external database. When a user asks the LLM a question, the system retrieves relevant documents from this database and provides them to the LLM to use as a reference to answer the user's question. for this chatbot.
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. What is Retrieval-Augmented Generation (RAG) and when to use it Retrieval-Augmented Generation (RAG) is a method that integrates the capabilities of a language model with a specific library or database.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Models like Sentence Transformers map words, sentences, or documents into high-dimensional vectors. To find relevant text, you compare vectors using metrics like cosine similarity, retrieving documents whose embeddings are closest to the query embedding. It scores documents based on: 1. from rank_bm25 import BM25Okapi# 1.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
One of the key considerations while designing the chat assistant was to avoid responses from the default large language model (LLM) trained on generic data and only use the insurance policy documents. The ingestion workflow involves three key components: policy documents, embedding model, and OpenSearch Service as a vector database.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
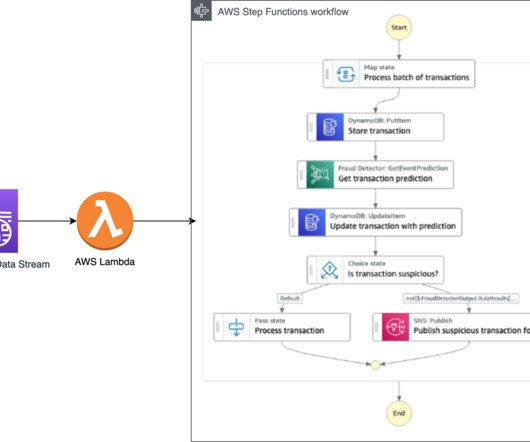
This approach allows you to react to the potentially fraudulent transactions in real time as you store each transaction in a database and inspect it before processing further. During claims processing, you collect all the claims documents and then run them through a fraud detection system. An example use case is claims processing.
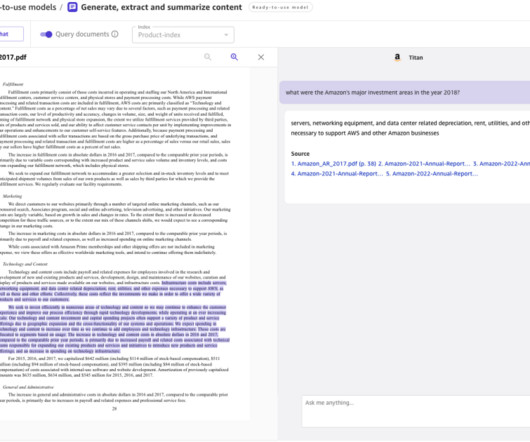
It works by analyzing the visual content to find similar images in its database. Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. For more information on managing credentials securely, see the AWS Boto3 documentation.
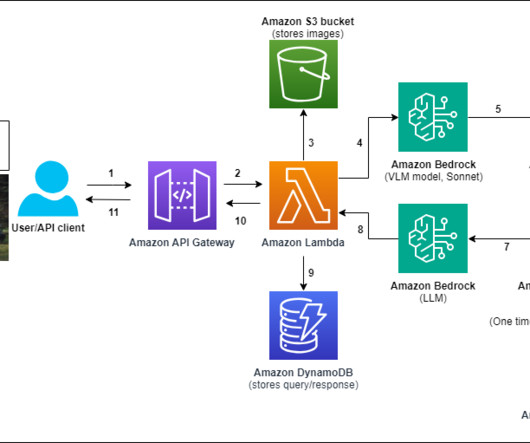
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Prepare data for machinelearning. Choose Add connection.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machinelearning (ML) models into vectors (numerical encodings). To learn more, refer to the documentation.
The significance of RAG is underscored by its ability to reduce hallucinationsinstances where AI generates incorrect or nonsensical informationby retrieving relevant documents from a vast corpora. Document Retrieval: The retriever processes the query and retrieves relevant documents from a pre-defined corpus.
Enterprises seek to harness the potential of MachineLearning (ML) to solve complex problems and improve outcomes. Canvas users select the index where their documents are, and can ideate, research, and explore knowing that the output will always be backed by their sources-of-truth.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
This article breaks down what Late Chunking is, why its essential for embedding larger or more intricate documents, and how to build it into your search pipeline using Chonkie and KDB.AI When you have a document that spans thousands of words, encoding it into a single embedding often isnt optimal. as the vector store. Image By Author.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Stage 1: Data Ingestion Pipeline The ingestion stage is a preparation step for building a RAG pipeline, similar to the data cleaning and preprocessing steps in a machinelearning pipeline. These complex structures require specialized techniques to extract the relevant information accurately. Finding the optimal balance is crucial.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content