This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Heres how embeddings power these advanced systems: Semantic Understanding LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
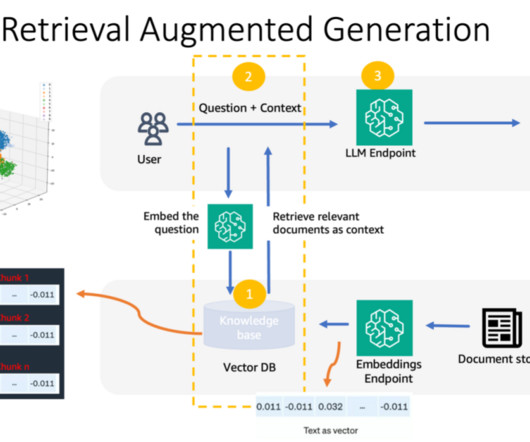
RAG workflow: Converting data to actionable knowledge RAG consists of two major steps: Ingestion Preprocessing unstructured data, which includes converting the data into text documents and splitting the documents into chunks. Document chunks are then encoded with an embedding model to convert them to document embeddings.
Artificial intelligence is no longer fiction and the role of AI databases has emerged as a cornerstone in driving innovation and progress. An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications.
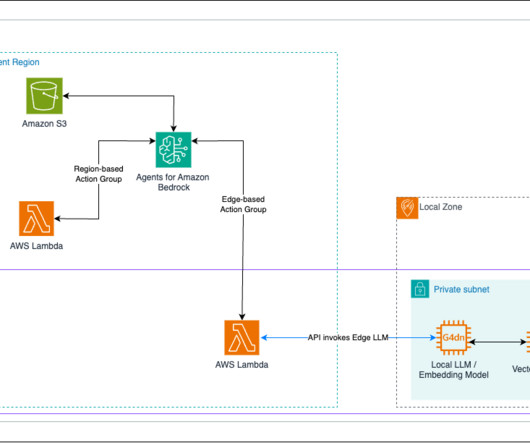
The documents uploaded to the knowledge base on the rack might be private and sensitive documents, so they wont be transferred to the AWS Region and will remain completely local on the Outpost rack. This vector database will store the vector representations of your documents, serving as a key component of your local Knowledge Base.
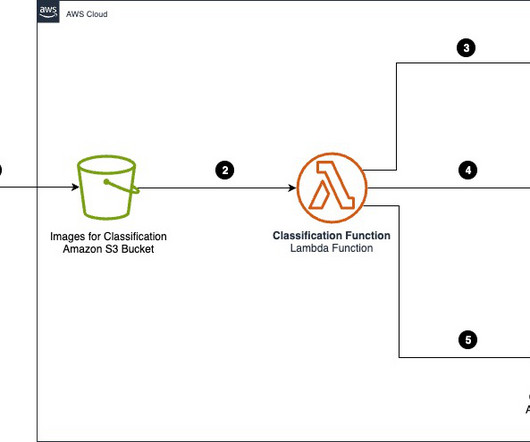
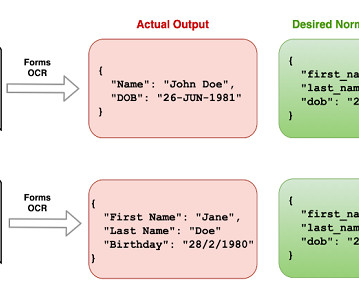
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. By “bringing the code to the data,” we’ve seen ML applications run anywhere from 4-100x faster than other architectures. A vector is stored as a simple Array of floating point numbers.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
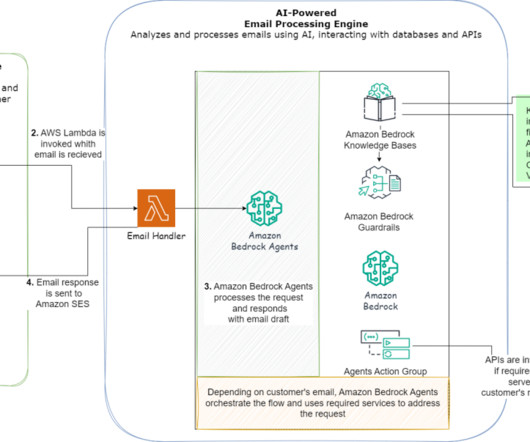
Organizations possess extensive repositories of digital documents and data that may remain underutilized due to their unstructured and dispersed nature. It interacts with databases and APIs, extracting necessary information and determining appropriate responses to provide timely and accurate customer service.
What are Vector Databases? A new and unique type of database that is gaining immense popularity in the fields of AI and Machine Learning is the vector database. This is because vector embeddings are the only sort of data that a vector database is intended to store and retrieve.
Prerequisites Before diving in, you should have: Basic AI/ML understanding: concepts like language models, embeddings, and model inference. Models like Sentence Transformers map words, sentences, or documents into high-dimensional vectors. It scores documents based on: 1. Author(s): Syed Affan Originally published on Towards AI.
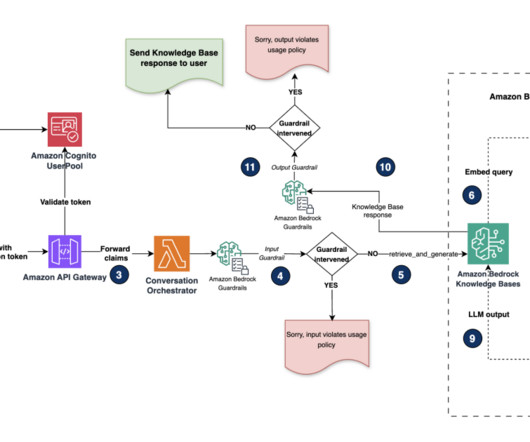
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data.
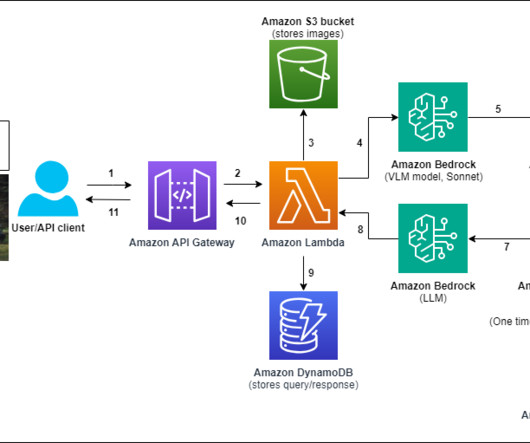
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
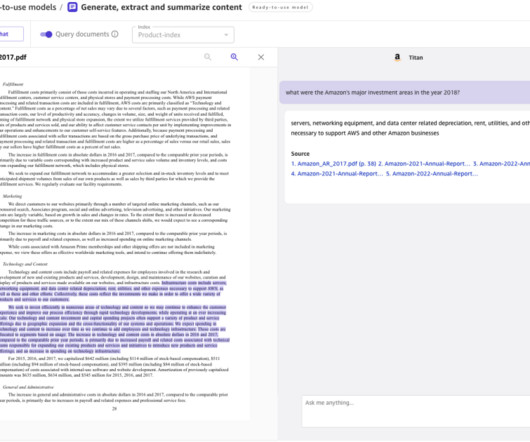
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
One of the key considerations while designing the chat assistant was to avoid responses from the default large language model (LLM) trained on generic data and only use the insurance policy documents. For our use case, we used a third-party embedding model.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
This is where ML CoPilot enters the scene. In this paper, the authors suggest the use of LLMs to make use of past ML experiences to suggest solutions for new ML tasks. This is where the utilization of vector databases like Pinecone becomes valuable to store all the past experiences and aids as the memory for LLMs.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
Enterprises seek to harness the potential of Machine Learning (ML) to solve complex problems and improve outcomes. Until recently, building and deploying ML models required deep levels of technical and coding skills, including tuning ML models and maintaining operational pipelines.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
Furthermore, healthcare decisions often require integrating information from multiple sources, such as medical literature, clinical databases, and patient records. Data is stored in a conversation history, and a member database (MemberDB) is used to store member information and the knowledge base has static documents used by the agent.
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. With this integration, SageMaker Canvas provides customers with an end-to-end no-code workspace to prepare data, build and use ML and foundations models to accelerate time from data to business insights.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The retrieved context and the user query are used to augment a prompt template.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. Store these chunks in a vector database, indexed by their embedding vectors. The various flavors of RAG borrow from recommender systems practices, such as the use of vector databases and embeddings.
Photo by Mariia Shalabaieva on Unsplash Over the past few months, I’ve been captivated by the flood of apps claiming to be the ultimate “ChatGPT for your documents” on Product Hunt. Decoding the technique Document Embeddings — First things first, we need to convert our documents into something called “ embeddings ”.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity. jpg") or doc.endswith(".png")) b64encode(fIn.read()).decode("utf-8")
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models.
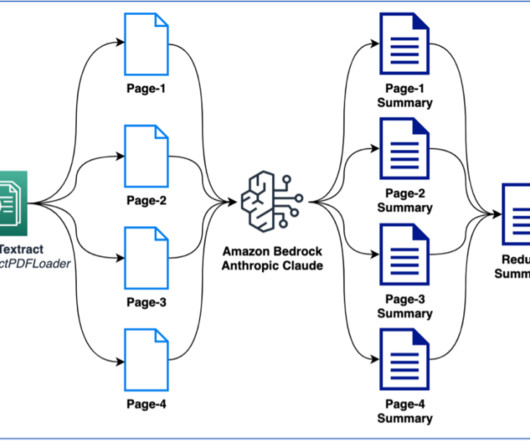
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Layout is a new feature that allows customers to automatically extract layout elements such as paragraphs, titles, subtitles, headers, footers, and more from documents.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. For more information on managing credentials securely, see the AWS Boto3 documentation.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
In addition, customers are looking for choices to select the most performant and cost-effective machine learning (ML) model and the ability to perform necessary customization (fine-tuning) to fit their business use cases. Their training on predominantly generalized data diminishes their efficacy in domain-specific tasks. Lewis et al.
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query.
Machine learning (ML) can help companies make better business decisions through advanced analytics. Companies across industries apply ML to use cases such as predicting customer churn, demand forecasting, credit scoring, predicting late shipments, and improving manufacturing quality. MB to 100 MB in size.
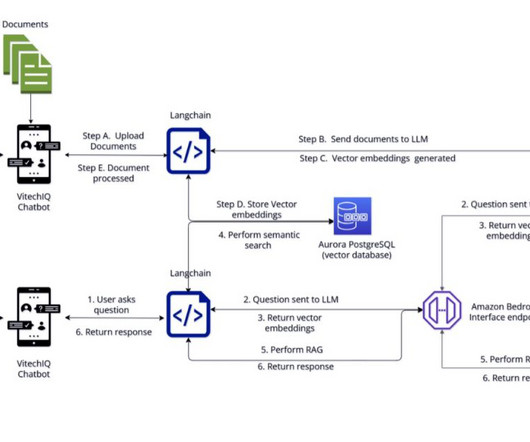
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
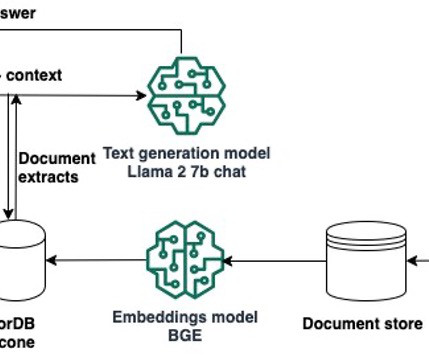
Solution components In this section, we discuss two key components to the solution: the data sources and vector database. Data sources We use Spack documentation RST (ReStructured Text) files uploaded in an Amazon Simple Storage Service (Amazon S3) bucket. For this solution, we boosted the results for the Spack documentation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content