This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. Imagine a database with billions of samples ( ) (e.g., Imagine a database with billions of samples ( ) (e.g.,
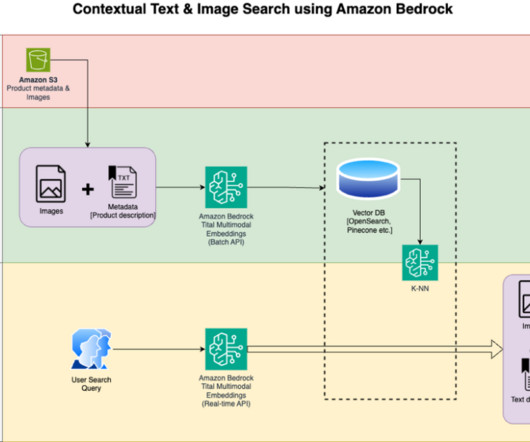
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. Display results : Display the top K similar results to the user. b64encode(resized_image).decode('utf-8')
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. When combined with Amazon OpenSearch Service , it enables robust Retrieval Augmented Generation (RAG) applications.
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. You then display the top similar results.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. In the user interaction phase, a question from the user is converted into embeddings and a similarity search is run on the vector database to find a slide that could potentially contain answers to user question.
Home Table of Contents Approximate NearestNeighbor with Locality Sensitive Hashing (LSH) What Is Locality Sensitive Hashing (LSH)? Jump Right To The Downloads Section What Is Locality Sensitive Hashing (LSH)? On Line 28 , we sort the distances and select the top knearestneighbors.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In this post, we present a solution to handle OOC situations through knowledge graph-based embedding search using the k-nearestneighbor (kNN) search capabilities of OpenSearch Service. Solution overview.
Run the following command on the terminal to download the sample code from Github: git clone [link] Generate sample posts and compute multimodal embeddings In the code repository, we provide some sample product images (bag, car, perfume, and candle) that were created using the Amazon Titan Image Generator model. Choose Open JupyterLab.
Databases to be migrated can have a wide range of data representations and contents. For the sake of argument, let’s ignore the fact that the use of such data types in databases is justified only in a few specific cases, as this problem often arises when migrating complex systems. in XML, CLOB, BLOB etc.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content