This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
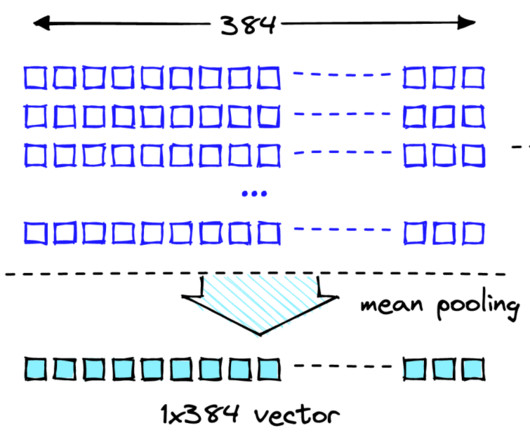
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
When you run the crawler, it creates metadata tables that are added to a database you specify or the default database. This approach is ideal for AWS Glue databases with a small number of tables. Fetch information for the database tables from the Data Catalog. Each table represents a single data store. Build the prompt.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Database name : Enter dev. Choose Add connection.
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. With this integration, SageMaker Canvas provides customers with an end-to-end no-code workspace to prepare data, build and use ML and foundations models to accelerate time from data to business insights.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The retrieved context and the user query are used to augment a prompt template.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
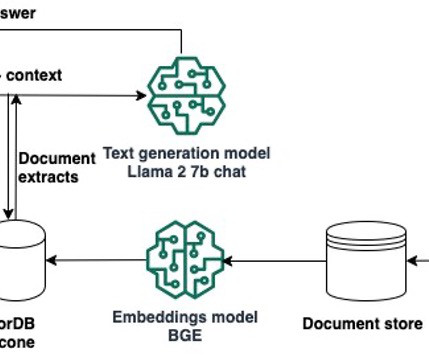
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
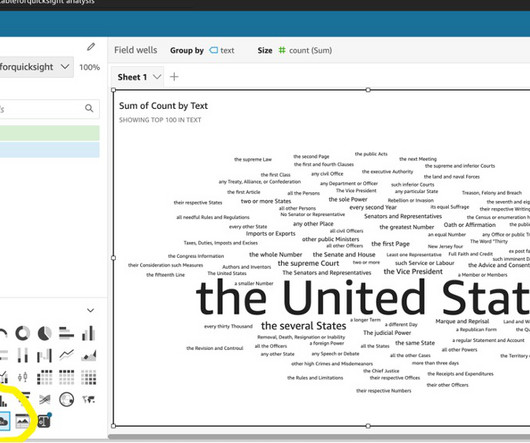
A traditional approach might be to use word counting or other basic analysis to parse documents, but with the power of Amazon AI and machine learning (ML) tools, we can gather deeper understanding of the content. Amazon Comprehend lets non-ML experts easily do tasks that normally take hours of time. Choose Create crawler.
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. script to download the model and tokenizer. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity. jpg") or doc.endswith(".png")) b64encode(fIn.read()).decode("utf-8")
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Learn how the synergy of AI and ML algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Paraphrasing tools in AI and ML algorithms Machine learning is a subset of AI. You can download Pegasus using pip with simple instructions.
Learn how the synergy of AI and ML algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Paraphrasing tools in AI and ML algorithms Machine learning is a subset of AI. You can download Pegasus using pip with simple instructions.
Download the free, unabridged version here. Machine Learning In this section, we look beyond ‘standard’ ML practices and explore the 6 ML trends that will set you apart from the pack in 2021. Give this technique a try to take your team’s ML modelling to the next level. Team How to determine the optimal team structure ?
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Enter a user name, password, and database name.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. or later image versions.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. For more information, see Creating connectors for third-party ML platforms. You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines.
SageMaker JumpStart is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. SageMaker Studio is a comprehensive IDE that offers a unified, web-based interface for performing all aspects of the ML development lifecycle. Deploy Llama 3.2
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. Access permission to the AWS Glue databases and tables are managed by AWS Lake Formation. Abhijit Kalita is a Senior AI/ML Evangelist at Amazon Web Services.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
Leverage the Watson NLP library to build the best classification models by combining the power of classic ML, Deep Learning, and Transformed based models. In this blog, you will walk through the steps of building several ML and Deep learning-based models using the Watson NLP library. So, let’s get started with this.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
The brand-new Forecasting tool created on Snowflake Data Cloud Cortex ML allows you to do just that. What is Cortex ML, and Why Does it Matter? Cortex ML is Snowflake’s newest feature, added to enhance the ease of use and low-code functionality of your business’s machine learning needs.
Code Snippet Output Image by Author Caching with Redis Redis is an in-memory database that runs completely on our machine’s RAM. Since accessing data from RAM is much faster than from disk, it's commonly used as a cache. This provides a point-in-time backup of the data, so if a failure happens, we can restore the last saved snapshot.
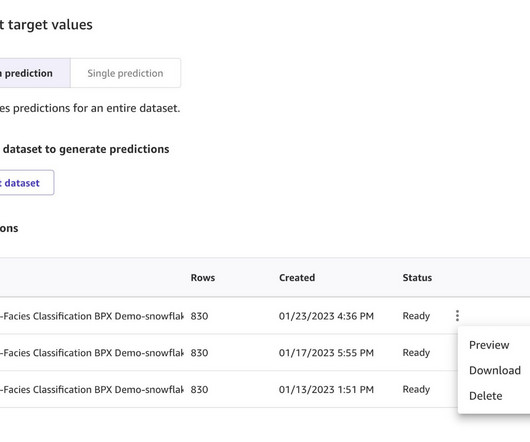
Facies classification using AI and machine learning (ML) has become an increasingly popular area of investigation for many oil majors. Many data scientists and business analysts at large oil companies don’t have the necessary skillset to run advanced ML experiments on important tasks such as facies classification. Choose Edit in SQL.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query.
As companies continue to adopt machine learning (ML) in their workflows, the demand for scalable and efficient tools has increased. In this blog post, we will explore the performance benefits of Snowpark for ML workloads and how it can help businesses make better use of their data. For each step, we’ll record how long it takes too.
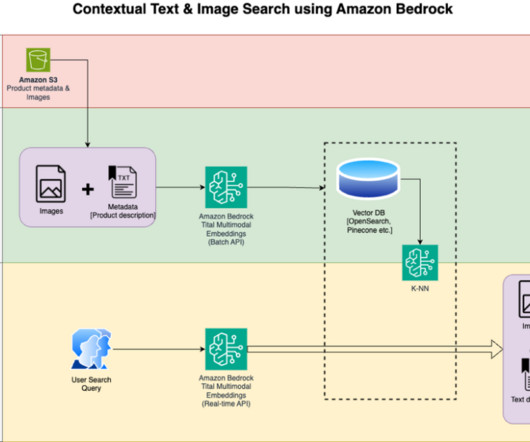
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS.
Machine learning (ML) methods can help identify suitable compounds at each stage in the drug discovery process, resulting in more streamlined drug prioritization and testing, saving billions in drug development costs (for more information, refer to AI in biopharma research: A time to focus and scale ).
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. In these cases, the model sizes are smaller, which means the communication overhead with GPUs or ML accelerator instances outweighs their compute performance benefits.
We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. In the user interaction phase, a question from the user is converted into embeddings and a similarity search is run on the vector database to find a slide that could potentially contain answers to user question.
It is also called the second brain as it can store data that is not arranged according to a present data model or schema and, therefore, cannot be stored in a traditional relational database or RDBMS. ’ If someone wants to use Quivr without any limitations, then they can download it locally on their device.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Second, you might need to build text-to-SQL features for every database because data is often not stored in a single target. This table is used for finding the correct table, database, and attributes.
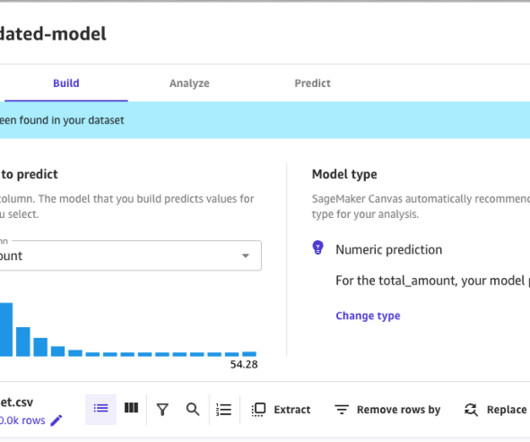
Amazon SageMaker Canvas is a visual interface that enables business analysts to generate accurate machine learning (ML) predictions on their own, without requiring any ML experience or having to write a single line of code. Download the following two datasets to your local computer. Set up SageMaker Canvas.
The solution uses AWS AI and machine learning (AI/ML) services, including Amazon Transcribe , Amazon SageMaker , Amazon Bedrock , and FMs. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
Evaluating LLMs is an undervalued part of the machine learning (ML) pipeline. Dataset The MIMIC Chest X-ray (MIMIC-CXR) Database v2.0.0 Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
As a senior data scientist, I often encounter aspiring data scientists eager to learn about machine learning (ML). The ML Process The machine learning process typically consists of the following steps: Data Collection Gathering relevant data is the first step in the machine learning process.
Both plans provide the necessary capabilities to create a custom application, download a JWT token as an administrator, and then configure the connector to ingest relevant data from Box. Complete the two-step verification process and choose OK to download the JSON file to your computer. Download the zip file to your computer.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content