This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To install Node.js, download it from nodejs.org To install pnpm, run the following command: npm install -g pnpm Step 3: Set Up Environment Variables cp.env.example.env Edit the.env file to include your OpenAI / Anthropic /OpenRouter API key and, optionally, your GitHub personal access token. and pnpm installed globally. start-database.sh
Downloading files for months until your desktop or downloads folder becomes an archaeological dig site of documents, images, and videos. What to build : Create a script that monitors a folder (like your Downloads directory) and automatically sorts files into appropriate subfolders based on their type. Let’s get started.
After Kaggle, this is one of the best sources for free datasets to download and enhance your data science portfolio. Ideal for data scientists and engineers working with databases and complex data models. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: No, thanks!
The PDF I’m using is publicly accessible, and you can download it using the link. Examples of Articles Conclusion In this guide, you’ve learned how to build a flexible and powerful PDF processing pipeline using only open-source tools. Show extracted image metadata") choice = input("Enter the number of your choice: ").strip()
Organizations manage extensive structured data in databases and data warehouses. Large language models (LLMs) have transformed naturallanguageprocessing (NLP), yet converting conversational queries into structured data analysis remains complex. For this post, we demonstrate the setup option with IAM access.
app downloads, DeepSeek is growing in popularity with each passing hour. DeepSeek AI is an advanced AI genomics platform that allows experts to solve complex problems using cutting-edge deep learning, neural networks, and naturallanguageprocessing (NLP). With numbers estimating 46 million users and 2.6M
Agents: LangChain offers a flexible approach for tasks where the sequence of language model calls is not deterministic. The library also integrates with vector databases and has memory capabilities to retain the state between calls, enabling more advanced interactions. smaller chunks may sometimes be more likely to match a query.
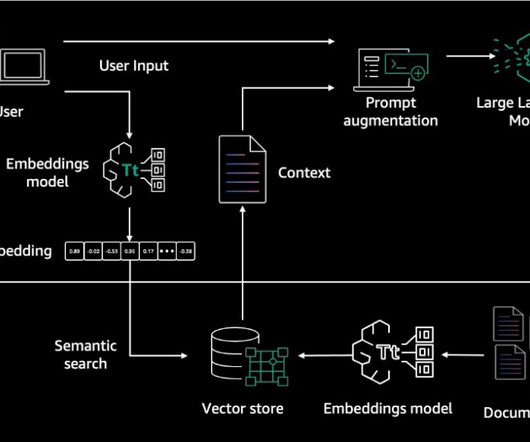
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
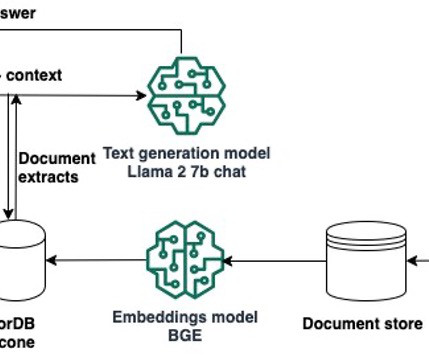
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
Learn NLP data processing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk on Unsplash At its core, the discipline of NaturalLanguageProcessing (NLP) tries to make the human language “palatable” to computers.
Amazon Redshift is a database optimized for online analytical processing (OLAP), which generally entails analyzing large amounts of data and performing complex analysis, as might be done by analysts looking at historical stock prices. Finance domain The Finance domain has two tables: Stock Price and Research Budgets.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning algorithms. You can download Pegasus using pip with simple instructions.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. You can download Pegasus using pip with simple instructions. Here’s how it works for paraphrasing.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. You can download Pegasus using pip with simple instructions. Here’s how it works for paraphrasing.
Amazon Comprehend is a fully, managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. Amazon Comprehend creates a JSON formatted output that needs to be transformed and processed into a database format using AWS Glue. Choose Add database. Choose Next.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and data scientists face significant challenges customizing these large models. Download the SQuaD dataset and upload it to SageMaker Lakehouse by following the steps in Uploading data.
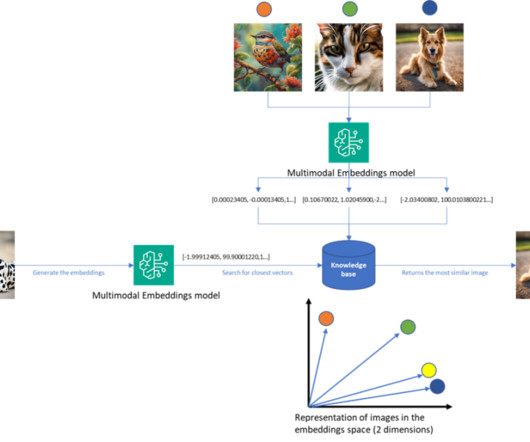
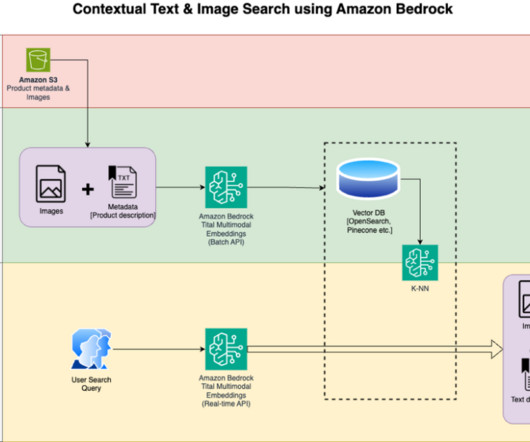
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. However, as data becomes increasingly multimodal in nature, extending these systems to handle various data types is crucial to provide more comprehensive and contextually rich responses.
It is also called the second brain as it can store data that is not arranged according to a present data model or schema and, therefore, cannot be stored in a traditional relational database or RDBMS. ’ If someone wants to use Quivr without any limitations, then they can download it locally on their device.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
Solution overview The AI-powered asset inventory labeling solution aims to streamline the process of updating inventory databases by automatically extracting relevant information from asset labels through computer vision and generative AI capabilities. It invokes the API to process the data.
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here.
Second, using this graph database along with generative AI to detect second and third-order impacts from news events. This post demonstrates a proof of concept built on two key AWS services well suited for graph knowledge representation and naturallanguageprocessing: Amazon Neptune and Amazon Bedrock.
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. The same approach can be used with different models and vector databases.
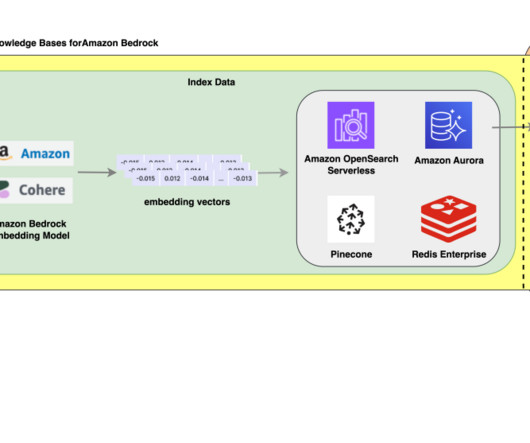
To address this, the company decides to build a GraphRAG application using Amazon Bedrock Knowledge Bases , usign the graph databases to represent complex relationships within the data. Data exploration : With the graph database populated, users can quickly explore the data using Graph Explorer.
Retrieval Augmented Generation (RAG) is a process in which a language model retrieves contextual documents from an external data source and uses this information to generate more accurate and informative text. This technique is particularly useful for knowledge-intensive naturallanguageprocessing (NLP) tasks.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. indexify server -d (These are two separate lines.)
SageMaker Canvas supports multiple ML modalities and problem types, catering to a wide range of use cases based on data types, such as tabular data (our focus in this post), computer vision, naturallanguageprocessing, and document analysis. To download a copy of this dataset, visit.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. indexify server -d (These are two separate lines.)
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. Retrieval Augmented Generation RAG is an approach to naturallanguage generation that incorporates information retrieval into the generation process.
Its fast and flexible NoSQL database service accommodates high-performance needs. PDF download: Downloads the PDF file from S3. Image processing: Saves the images locally and uploads them back to S3. Amazon DynamoDB : Used for storing metadata and other necessary information for quick retrieval during search operations.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. join(batch_text_arr) s3.put_object(
In this series, we will set up AWS OpenSearch , which will serve as a vector database for a semantic search application that well develop step by step. Jump Right To The Downloads Section Introduction What Is AWS OpenSearch? 1 Creating a Sample Index An index in OpenSearch is like a database table where data is stored.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. on Amazon Bedrock.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. These steps are completed prior to the user interaction steps.
Your video may be exported in high definition and then shared on social media or downloaded to your mobile device. You can export your video in HD quality and share it directly to social media or download it to your device. It also selects relevant images or footage from its database or online sources.
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. You then display the top similar results.
Generative language models have proven remarkably skillful at solving logical and analytical naturallanguageprocessing (NLP) tasks. DynamoDB table An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database. Enable read-through caching on the Aurora database.
When you download KNIME Analytics Platform for the first time, you will no doubt notice the sheer number of nodes available to use in your workflows. This is where KNIME truly shines and sets itself apart from its competitors: the scores of free extensions available for download.
To ensure security and JSON/pickle benefits, you can save your model to a dedicated database. Next, you will see how you can save an ML model in a database. To save the model using ONNX, you need to have onnx and onnxruntime packages downloaded in your system. or NoSQL databases like MongoDB , Cassandra , etc.
Intelligent insights and recommendations Using its large knowledge base and advanced naturallanguageprocessing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. You can download a sample file and review the contents.
The synthetic data generation notebook automatically downloads the CUAD_v1 ZIP file and places it in the required folder named cuad_data. His area of research is all things naturallanguage (like NLP, NLU, and NLG). His research publications are on naturallanguageprocessing, personalization, and reinforcement learning.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using naturallanguageprocessing (NLP) and advanced search algorithms. Access permission to the AWS Glue databases and tables are managed by AWS Lake Formation. amazonaws.com docker build -t.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









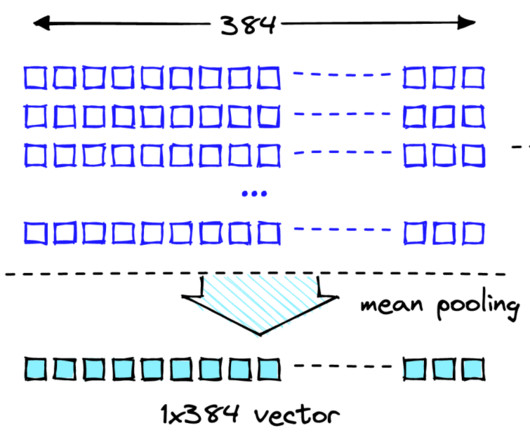





























Let's personalize your content