This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This means that you can use natural language prompts to perform advanced dataanalysis tasks, generate visualizations, and train machine learning models without the need for complex coding knowledge. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and dataanalysis.
Photo by Luke Chesser on Unsplash EDA is a powerful method to get insights from the data that can solve many unsolvable problems in business. In the increasingly competitive world, understanding the data and taking quicker actions based on that help create differentiation for the organization to stay ahead!
The following steps are involved in pipeline development: Gathering data: The first step is to gather the data that will be used to train the model. For data scrapping a variety of sources, such as online databases, sensor data, or social media. This involves removing any errors or inconsistencies in the data.
There are many well-known libraries and platforms for dataanalysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. These tools will help make your initial data exploration process easy.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and clean data from multiple sources, ensuring it is suitable for analysis. Sources of DataData can come from multiple sources.
This can be done from various sources such as CSV files, Excel files, or databases. Loading the dataset allows you to begin exploring and manipulating the data. During EDA, you can: Check for missing values. Identify data types of each column. This allows you to evaluate model performance on unseen data.
Its flexibility allows you to produce high-quality graphs and charts, making it perfect for exploratoryDataAnalysis. Use cases for Matplotlib include creating line plots, histograms, scatter plots, and bar charts to represent data insights visually.
Comet is an MLOps platform that offers a suite of tools for machine-learning experimentation and dataanalysis. It is designed to make it easy to track and monitor experiments and conduct exploratorydataanalysis (EDA) using popular Python visualization frameworks.
Integration also helps avoid duplication and redundancy of data, providing a comprehensive view of the information. Exploratorydataanalysis (EDA) Before preprocessing data, conducting exploratorydataanalysis is crucial to understand the dataset’s characteristics, identify patterns, detect outliers, and validate missing values.
Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Key Processes and Techniques in DataAnalysisData Collection: Gathering raw data from various sources (databases, APIs, surveys, sensors, etc.). Data Cleaning & Preparation: This is often the most time-consuming step. EDA: Calculate overall churn rate. Avoid overly complex visuals.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Separately, the company uses AWS data services, such as Amazon Simple Storage Service (Amazon S3), to store data related to patients, such as patient information, device ownership details, and clinical telemetry data obtained from the wearables.
It is a data integration process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target system. ETL ensures data quality and enables analysis and reporting. Figure 9: Writing name of our database and save it Excellent! ? Windows NT 10.0;
Web Scraping : Extracting data from websites and online sources. Sensor Data: Capturing real-time data from IoT devices or sensors. Public Datasets: Utilising publicly available datasets from repositories like Kaggle or government databases.
Step 2: Data Gathering Collect relevant historical data that will be used for forecasting. This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., databases, APIs, CSV files). Making Data Stationary: Many forecasting models assume stationarity.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
Later R&D on this subject routes to dynamic analytics, data-informed decision-making, and stride to mitigate asymmetric facts and truth about climate change. Two Data Sets were used to weigh carbon emission rates under two different metrics: Co2 (Carbon Dioxide) and GHG (Green House Gases).
Top 7 diagrams as code tools for software architecture Copilot [link] Good for: Create a list of all states in US Repetitive task like insert all database fields (no need to type manually of everything) [link] Don’t let copilot generate function (no comment-driven development), but let copilot complete some part Is GitHub Copilot Worth Being Paid?
The Clickstream Data usually contains <SessionId, User, Query, Item, Click, ATC, Order> Maintaining session-level data for each user over a long history could be overkill, and ML model development might not always require that level of granular data. are present in the data.
In this article, let’s dive deep into the Natural Language Toolkit (NLTK) data processing concepts for NLP data. Before building our model, we will also see how we can visualize this data with Kangas as part of exploratorydataanalysis (EDA).
Guide users on how to clean and preprocess data, handle missing values, normalize datasets, and provide insights on exploratorydataanalysis (EDA) and inferential statistics.
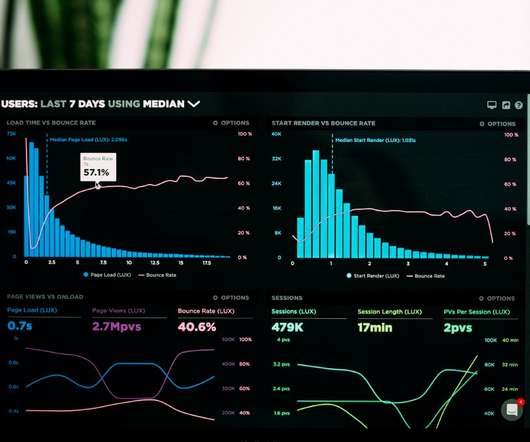
The term “data visualization” refers to the visual representation of data using tables, charts, graphs, maps, and other aids to analyze and interpret information. It is a crucial component of the Exploration DataAnalysis (EDA) stage, which is typically the first and most critical step in any data project.
: I enjoy participating in machine learning/data-science challenges and have been doing it for a while. This particular competition gave me the opportunity to use/evaluate recent trends/SOTA in Large Language models, semantic search, knowledge graphs, and vector databases, which was different from my computer-vision background.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content