This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization. They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies.
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. It is important to note that in the Lambda architecture, the serving layer can be omitted, allowing batch processing and event streaming to remain separate entities.
Summary: This comprehensive guide delves into the structure of Database Management System (DBMS), detailing its key components, including the database engine, database schema, and user interfaces. Database Management Systems (DBMS) serve as the backbone of data handling.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB. Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. This ensures data consistency and integrity.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. It seeks to identify the root causes of specific outcomes or issues.
Extraction, Transform, Load (ETL). Profisee notices changes in data and assigns events within the systems. Panoply also has an intuitive dashboard for management and budgeting, and the automated maintenance and scaling of multi-node databases. Databases can be SQL or Blob storage for unstructured object data.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. This is where Apache Flink shines, offering a powerful solution to harness the full potential of an event-driven business model through efficient computing and processing capabilities.
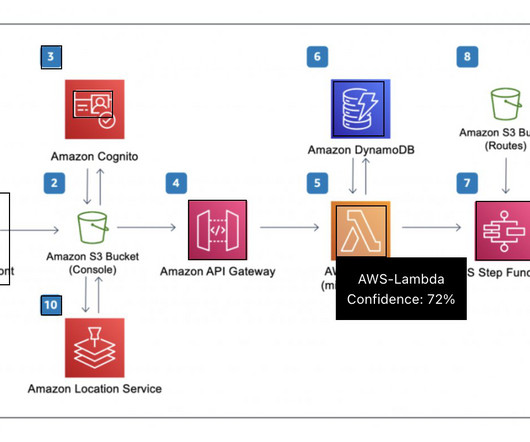
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures. It maintains a write-ahead log to ensure that the state of FlowFiles preserved, even in the event of a failure. Provenance Repository : This repository records all provenance events related to FlowFiles.
Production databases are a data-rich environment, and Fivetran would help us to migrate data by moving data from on-prem to the supported destinations; ensuring that this data remains uncorrupted throughout enhancements and transformations is crucial. Hence, Fivetran must have a way to connect or establish access to your source database.
The entire process is also achieved much faster, boosting not just general efficiency but an organization’s reaction time to certain events, as well. With databases, for example, choices may include NoSQL, HBase and MongoDB but its likely priorities may shift over time.
Hyper Supercharge your analytics with in-memory data engine Hyper is Tableau's blazingly fast SQL engine that lets you do fast real-time analytics, interactive exploration, and ETL transformations through Tableau Prep. You can see the impacts of joins as you create data sources or write back to your database. table or workbook).
AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. When the ETL process is complete, the output file is placed back into Amazon S3, ready for ingestion into Amazon Personalize via a dataset import job.
Apache Kafka is an open-source event distribution platform. Its use cases range from real-time analytics, fraud detection, messaging, and ETL pipelines. Confluent Kafka is also powered by a user-friendly interface that enables the development of event-driven microservices and other real-time use cases.
One Data Engineer: Cloud database integration with our cloud expert. ” Hence the very first thing to do is to make sure that the data being used is of high quality and that any errors or anomalies are detected and corrected before proceeding with ETL and data sourcing. We primarily used ETL services offered by AWS.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. Interested in attending an ODSC event? Learn more about our upcoming events here.
David: My technical background is in ETL, data extraction, data engineering and data analytics. NeuML was working on a real-time sports event tracking application, neuspo but sports along with everything else was being shut down and there were no sports to track. David, what can you tell us about your background?
They may also be involved in data modeling and database design. BI developer: A BI developer is responsible for designing and implementing BI solutions, including data warehouses, ETL processes, and reports. They may also be involved in data integration and data quality assurance.
They may also be involved in data modeling and database design. BI developer: A BI developer is responsible for designing and implementing BI solutions, including data warehouses, ETL processes, and reports. They may also be involved in data integration and data quality assurance.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
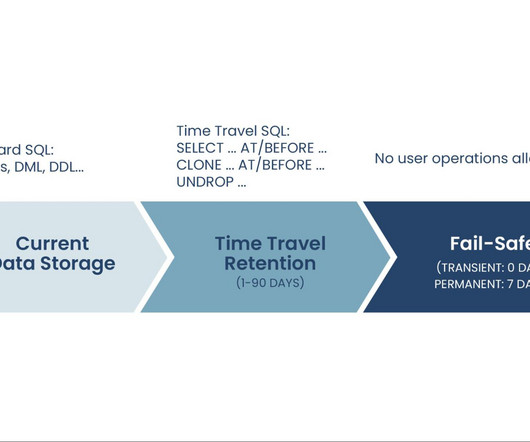
To ensure your queries aren’t lost or fail in such an event, Snowflake will automatically restart the query in another availability zone or begin another compute instance if one fails without the user having to restart the query. Query Resiliency Snowflake uses virtual warehouses for compute execution in one availability zone.
The figure below illustrates a high-level overview of our asynchronous event-driven architecture. Step 3 The S3 bucket is configured to trigger an event when the user uploads the input content. When the asynchronous SageMaker endpoint completes a prediction, an Amazon SNS event is triggered.
Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake.
In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more. It often involves specialized databases designed to handle this kind of atomic, temporal data.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Relational database connectors are available. Relational database connectors such as Teradata, Oracle, and Microsoft SQL servers are available. Pricing Up to a million events/month on the free plan.
These tasks often go through several stages, similar to the ETL process (Extract, Transform, Load). This means data has to be pulled from different sources (such as systems, databases, and spreadsheets), transformed (cleaned up and prepped for analysis), and then loaded back into its original spot or somewhere else when it’s done.
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Replicate can interact with a wide variety of databases, data warehouses, and data lakes (on-premise or based in the cloud).
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database.
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Understanding the differences between SQL and NoSQL databases is crucial for students. Once data is collected, it needs to be stored efficiently.
These tables are called “factless fact tables” or “junction tables” They are used for modelling many-to-many relationships or for capturing timestamps of events. A star schema forms when a fact table combines with its dimension tables. This schema serves as the foundation of dimensional modeling.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. Airflow uses Directed Acyclic Graphs (DAGs) to represent workflows as tasks with defined dependencies.
For example, you can use alerts to send notifications, capture data, or execute SQL commands when certain events or thresholds are reached in your data. Tasks can be used to automate data processing workflows, such as ETL jobs, data ingestion, and data transformation. daily or weekly). How does CRON work for scheduling alerts?
It also supports ETL (Extract, Transform, Load) processes, making data warehousing and analytics essential. This component bridges the gap between traditional SQL databases and big data processing. What is Apache Spark? Apache Spark is an open-source, unified analytics engine for large-scale data processing.
Data enrichment” refers to the merging of third-party data from an external, authoritative source with an existing database of customer information you’ve gathered yourself. Is data enrichment a one-time event, or an ongoing process? What is data enrichment? How does data enrichment work? That depends on your objectives.
Vector Database : A vector database is a specialized database designed to efficiently store, manage, and retrieve high-dimensional vectors, also known as vector embeddings. Vector databases support similarity search operations, allowing users to find vectors most similar to a given query vector.
Modern low-code/no-code ETL tools allow data engineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance. The default value is Python3.
Introduction MongoDB is a robust NoSQL database, crucial in today’s data-driven tech industry. MongoDB is a NoSQL database that handles large-scale data and modern application requirements. Unlike traditional relational databases, MongoDB stores data in flexible, JSON-like documents, allowing for dynamic schemas.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content