This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications. Demand for applied ML scientists remains high, as more companies focus on AI-driven solutions for scalability.
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
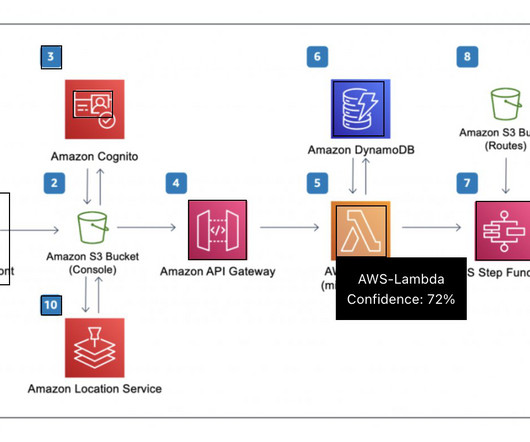
The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena , to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. Run SPARQL queries in the Neptune database to populate additional triples from inference rules.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs. Machine Learning In this section, we look beyond ‘standard’ ML practices and explore the 6 ML trends that will set you apart from the pack in 2021. They are skilled at deploying to any cloud or on-premises infrastructure.
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs. overall accuracy.
In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database. Incoming questions are converted to embeddings, and then the vector database runs a similarity search to find related content. The question and the reference data then go into the prompt for the LLM.
The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections. The attempt is disadvantaged by the current focus on data cleaning, diverting valuable skills away from building ML models for sensor calibration.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. or later image versions.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
Although these traditional machine learning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. Another boon for efficient work that SQL provides is its simple and consistent syntax that allows for collaboration across multiple databases.
But, it is not rare that data engineers and database administrators process, control, and store terabytes of data in projects that are not related to machine learning. Data from different formats, databases, and sources are combined together for modeling. Basically, every machine learning project needs data. DVC Git LFS neptune.ai
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Data Architect Designs complex databases and blueprints for data management systems.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
Let’s understand with an example if we consider web development so there are UI , UX , Database , Networking , and Servers and for implementing all these things we have different-different tools - technologies and frameworks , and when we have done with these things we just called this process as web development. If we talk about AI.
Generative AI empowers organizations to combine their data with the power of machine learning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. Based on the query embeddings, the relevant documents are retrieved from the embeddings database using similarity search.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
Learning about the framework of a service cloud platform is time consuming and frustrating because there is a lot of new information from many different computing fields (computer science/database, software engineering/developers, data science/scientific engineering & computing/research).
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. I would say the same happened in our case.
Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture. ETL tools act like skilled miners , extracting data from various source systems.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load. ETL ensures data quality and enables analysis and reporting.
Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods. While sensor data is typically numerical and has a well-defined format, such as timestamps and data points, it only fits the standard tabular structure of databases.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. A Lake Formation database populated with the TPC data.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). Machine Learning Training machine learning (ML) models can sometimes be resource-intensive. filter(col("id") == 1).select(col("name"),
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. Cloud Services: Google Cloud Platform, AWS, Azure.
Managing unstructured data is essential for the success of machine learning (ML) projects. This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data.
11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. You will need to learn to query different databases depending on which ones your company uses. Some projects may not require ML at all.
Higher data intelligence drives higher confidence in everything related to analytics and AI/ML. The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. for the popular database SQL Server. A pillar of Alation’s platform strategy is openness and extensibility.
With so many different ways to get data into Snowflakefrom traditional ETL tools to APIs, batch processing, and streaming datait can quickly become overwhelming to choose the right approach. Solution: Datavolo integrates this unstructured data into Snowflake, enabling AI/ML models to: Analyze medical images for early disease detection.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content