This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Since the 1970s, relational database management systems have solved the problems of storing and maintaining large volumes of structured data. With the advent of big data, several organizations realized the benefits of big data processing and started choosing solutions like Hadoop to […].
The official description of Hive is- ‘Apache Hive data warehouse software project built on top of Apache Hadoop for providing data query and analysis. Hive gives an SQL-like interface to query data stored in various databases and […].
Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization. They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies.
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Data Sources and Collection Everything in data science begins with data.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is Apache Hadoop? What is Apache Spark?
With big data careers in high demand, the required skillsets will include: Apache Hadoop. Software businesses are using Hadoop clusters on a more regular basis now. Apache Hadoop develops open-source software and lets developers process large amounts of data across different computers by using simple models. NoSQL and SQL.
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., These datasets can range from terabytes to petabytes and beyond. XML, JSON), and unstructured data (e.g., text, images, videos).
Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks. Structured Data: Highly organized data, typically found in relational databases (like customer records with names, addresses, and purchase history). It comes in many different formats.
One common scenario that we’ve helped many clients with involves migrating data from Hive tables in a Hadoop environment to the Snowflake Data Cloud. Click Create cluster and choose software (Hadoop, Hive, Spark, Sqoop) and configuration (instance types, node count). Configure security (EC2 key pair). Find ElasticMapReduce-master.
Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases. Learn a programming language: Data engineers often use programming languages like Python or Java to write scripts and programs that automate data processing tasks.
They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization. Here’s a list of key skills that are typically covered in a good data science bootcamp: Programming Languages : Python : Widely used for its simplicity and extensive libraries for data analysis and machine learning.
PythonPython is perhaps the most critical programming language for AI due to its simplicity and readability, coupled with a robust ecosystem of libraries like TensorFlow, PyTorch, and Scikit-learn, which are essential for machine learning and deep learning.
Unlike the old days where data was readily stored and available from a single database and data scientists only needed to learn a few programming languages, data has grown with technology. Data engineering primarily revolves around two coding languages, Python and Scala. You should learn how to write Python scripts and create software.
Overview There are a plethora of data science tools out there – which one should you pick up? Here’s a list of over 20. The post 22 Widely Used Data Science and Machine Learning Tools in 2020 appeared first on Analytics Vidhya.
Programming skills A proficient data scientist should have strong programming skills, typically in Python or R, which are the most commonly used languages in the field. There are numerous online platforms offering free or low-cost courses in mathematics, statistics, and relevant programming languages such as Python, R, and SQL.
Introduction In the realm of Big Data, professionals are expected to navigate complex landscapes involving vast datasets, distributed systems, and specialized tools.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
The post A Beginners’ Guide to Apache Hadoop’s HDFS appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction With a huge increment in data velocity, value, and veracity, the volume of data is growing exponentially with time. A unique filesystem is required to […].
Familiarise yourself with essential tools like Hadoop and Spark. Variety Data comes in multiple forms, from highly organised databases to messy, unstructured formats like videos and social media text. What are the Main Components of Hadoop? What is the Role of a NameNode in Hadoop ? What is a DataNode in Hadoop?
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics. Yes, many people still need a data lake (for their relevant data, not all enterprise data).
They are responsible for managing database systems, scaling data architecture to multiple servers, and writing complex queries to sift through the data. Hadoop, SQL, Python, R, Excel are some of the tools you’ll need to be familiar using. Data Engineers. The Data Science Process.
Data Engineers work to build and maintain data pipelines, databases, and data warehouses that can handle the collection, storage, and retrieval of vast amounts of data. Data Storage: Storing the collected data in various storage systems, such as relational databases, NoSQL databases, data lakes, or data warehouses.
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). It is built on the Hadoop Distributed File System (HDFS) and utilises MapReduce for data processing.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
Key Skills Proficiency in programming languages like Python and R. Proficiency in programming languages like Python and SQL. Proficiency in programming languages like Python or Java. Key Skills Proficiency in programming languages such as C++ or Python. Familiarity with SQL for database management.
Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala. And you should have experience working with big data platforms such as Hadoop or Apache Spark. To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI.
Python: Versatile and Robust Python is one of the future programming languages for Data Science. However, with libraries like NumPy, Pandas, and Matplotlib, Python offers robust tools for data manipulation, analysis, and visualization. Enrol Now: Python Certification Training Data Science Course 2.
With databases, for example, choices may include NoSQL, HBase and MongoDB but its likely priorities may shift over time. For frameworks and languages, there’s SAS, Python, R, Apache Hadoop and many others. But no matter how difficult it is, data analysts must continue to stay at the forefront of that growth.
Furthermore, they must be highly efficient in programming languages like Python or R and have data visualization tools and database expertise. Effectively, Data Analysts use other tools like SQL, R or Python, Excel, etc., At length, use Hadoop, Spark, and tools like Pig and Hive to develop big data infrastructures.
Technical requirements for a Data Scientist High expertise in programming either in R or Python, or both. Familiarity with Databases; SQL for structured data, and NOSQL for unstructured data. Knowledge of big data platforms like; Hadoop and Apache Spark. Basic programming knowledge in R or Python.
Data scientists use a combination of programming languages (Python, R, etc.), Here is why: Skill and knowledge requirements: Data science is a multidisciplinary field that demands proficiency in statistics, programming languages (such as Python or R), machine learning algorithms, data visualization, and domain expertise.
Programming Languages (Python, R, SQL) Proficiency in programming languages is crucial. Python and R are popular due to their extensive libraries and ease of use. Python excels in general-purpose programming and Machine Learning , while R is highly effective for statistical analysis.
In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Strong programming language skills in at least one of the languages like Python, Java, R, or Scala. Sound knowledge of relational databases or NoSQL databases like Cassandra. What is Polybase?
It involves retrieving data from various sources, such as databases, spreadsheets, or even cloud storage. The ETL tool must work with your current systems, support your existing databases and applications, and be able to connect to various data sources. It supports a wide range of databases and provides robust ETL capabilities.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Key Takeaways Strong programming skills in Python and R are vital for Machine Learning Engineers. According to Emergen Research, the global Python market is set to reach USD 100.6
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Unlike data and business analysts, machine learning engineers will use Python and Python-based frameworks such as TensorFlow and PyTourch to develop and train their models.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Database Extraction: Retrieval from structured databases using query languages like SQL. Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation.
Integration: Integrates seamlessly with other data systems and platforms, including Apache Kafka, Spark, Hadoop and various databases. With its easy-to-use and no-code format, users without deep skills in SQL, Java, or Python can leverage events, enriching their data streams with real-time context, irrespective of their role.
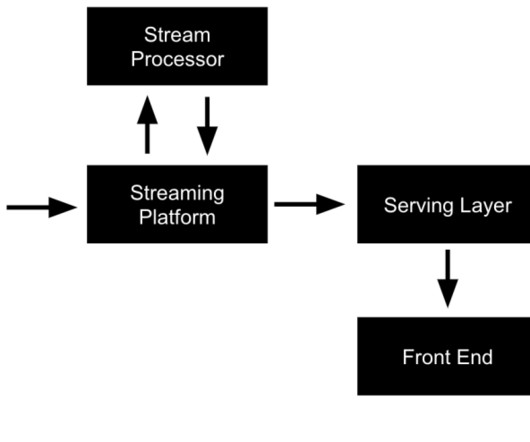
Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency. It can ingest from batch data sources (such as Hadoop HDFS, Amazon S3, and Google Cloud Storage) as well as stream data sources (such as Apache Kafka and Redpanda).
Crawlers then store this information in a database for indexing. Structured data can be easily imported into databases or analytical tools. Lead Generation Companies can scrape contact information from websites to build databases of potential customers. Beautiful Soup A Python library for parsing HTML and XML documents.
Data was extracted from mainframes and legacy systems into warehouse databases like Oracle and Teradata using custom-built ETL tools. Open source big data tools like Hadoop were experimented with – these could land data into a repository first before transformation. Data volumes exploded as web, mobile, and IoT took off.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content