This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Vector databases are revolutionizing healthcare data management. That’s where vector databases come in handy—they are made on purpose to handle this special kind of data.
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. Imagine a database with billions of samples ( ) (e.g., Traditional exact nearestneighbor search methods (e.g.,
4] Dataset The dataset comes from Kaggle [5], which contains a database of 3206 brain MRI images. The three weak learner models used for this implementation were k-nearestneighbors, decision trees, and naive Bayes. For the meta-model, k-nearestneighbors were used again.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. Display results : Display the top K similar results to the user. b64encode(resized_image).decode('utf-8')
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Association rule mining Association rule mining identifies interesting relations between variables in large databases.
The available data sources are: Stock Prices Database Contains historical stock price data for publicly traded companies. Analyst Notes Database Knowledge base containing reports from Analysts on their interpretation and analyis of economic events. Stock Prices Database The question is about a stock price.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. Each provisioned node was r7g.4xlarge,
Vector Databases 101: A Beginners Guide to Vector Search and Indexing Photo by Google DeepMind on Unsplash Introduction Alright, folks! The secret sauce behind all of this is vector search and vector databases, helping power similarity-based recommendations and retrieval! Traditional databases? They tap out.
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. OpenSearch Service then uses the vectors to find the k-nearestneighbors (KNN) to the vectorized search term and image to retrieve the relevant listings.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. When combined with Amazon OpenSearch Service , it enables robust Retrieval Augmented Generation (RAG) applications.
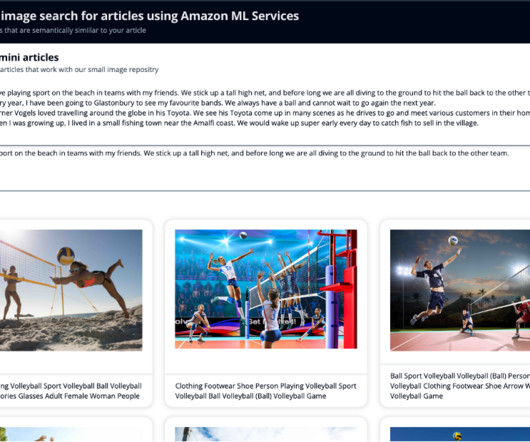
You then use Exact k-NN with scoring script so that you can search by two fields: celebrity names and the vector that captured the semantic information of the article. You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
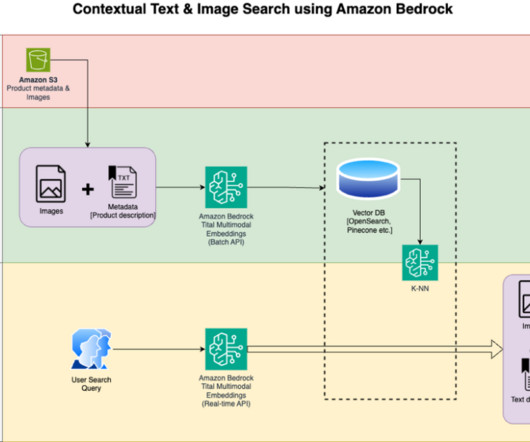
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. These steps are completed prior to the user interaction steps.
Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others. Association algorithms allow data scientists to identify associations between data objects inside large databases, facilitating data visualization and dimensionality reduction.
We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. In the user interaction phase, a question from the user is converted into embeddings and a similarity search is run on the vector database to find a slide that could potentially contain answers to user question.
Home Table of Contents Approximate NearestNeighbor with Locality Sensitive Hashing (LSH) What Is Locality Sensitive Hashing (LSH)? Refinement: The candidate set is then refined by computing the actual distances between the query point and the candidates to find the approximate nearestneighbors.
It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean. K-NN (knearestneighbors): K-NearestNeighbors (K-NN) is a simple yet powerful algorithm used for both classification and regression tasks in Machine Learning.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
You can integrate existing data from AWS data lakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. The Asynchronous Request Handler function stores results in a DynamoDB database along with the generated requestId.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. To make this work, we need to transform the textual interactions into a format that allows algebraic operations.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). You split the video files into frames and save them in a S3 bucket (Step 1).
In this post, we present a solution to handle OOC situations through knowledge graph-based embedding search using the k-nearestneighbor (kNN) search capabilities of OpenSearch Service. Solution overview. The key AWS services used to implement this solution are OpenSearch Service, SageMaker, Lambda, and Amazon S3.
K-NearestNeighbor Regression Neural Network (KNN) The k-nearestneighbor (k-NN) algorithm is one of the most popular non-parametric approaches used for classification, and it has been extended to regression. Decision Trees ML-based decision trees are used to classify items (products) in the database.
#LuxuryBrand #TimelessElegance #ExclusiveCollection Retrieve and analyze the top three relevant posts The next step involves using the generated image and text to search for the top three similar historical posts from a vector database. The following code snippet shows the implementation of this step.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
On one hand, there’s a data management community trying to understand data transformation and computing some functions over exponentially many databases for decades. You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier.
On one hand, there’s a data management community trying to understand data transformation and computing some functions over exponentially many databases for decades. You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier.
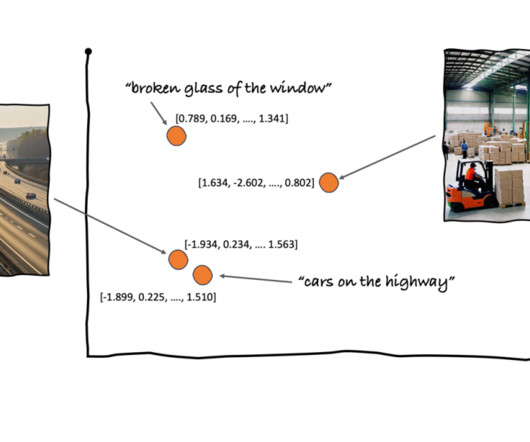
Source: [link] The previous system works this way: there is a bank of face images, their corresponding embeddings are stored in a vector database and the labels are also available.
Structured data refers to neatly organised data that fits into tables, such as spreadsheets or databases, where each column represents a feature and each row represents an instance. This data can come from databases, APIs, or public datasets. K-NearestNeighbors), while others can handle large datasets efficiently (e.g.,
Adding vectors to the index (xb are database vectors that are to be indexed). index.add(xb) # xq are query vectors, for which we need to search in xb to find the knearestneighbors. # The search returns D, the pairwise distances, and I, the indices of the nearestneighbors. . # Creating the index.
The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance. This trade-off can easily be reversed by increasing the k value which in turn results in increasing the number of neighbours. Let us see some examples. So, prepare well for that as well.
He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearchs vector database capabilities. Dylan has decades of experience working directly with customers and creating products and solutions in the database, analytics and AI/ML domain.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. She is passionate about sharing knowledge and fostering interest in emerging talent.
Databases to be migrated can have a wide range of data representations and contents. For the sake of argument, let’s ignore the fact that the use of such data types in databases is justified only in a few specific cases, as this problem often arises when migrating complex systems. in XML, CLOB, BLOB etc.
The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. In traditional RAG use cases, the chatbot relies on a database of text documents (.doc,pdf, Practically, this can be achieved in OpenSearch by combining a k-nearestneighbors (k-NN) query with keyword matching.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content