This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. How OpenSearch Uses Neural Search and k-NN Indexing Figure 6 illustrates the entire workflow of how OpenSearch processes a neural query and retrieves results using k-NearestNeighbor (k-NN) search.
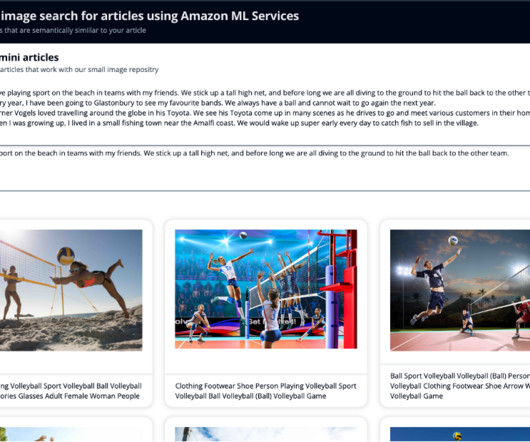
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. Display results : Display the top K similar results to the user. b64encode(resized_image).decode('utf-8')
Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. Each provisioned node was r7g.4xlarge,
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. OpenSearch Service then uses the vectors to find the k-nearestneighbors (KNN) to the vectorized search term and image to retrieve the relevant listings.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. Archana is an aspiring member of the AI/ML technical field community at AWS.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. For more information, see Creating connectors for third-party ML platforms. You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines.
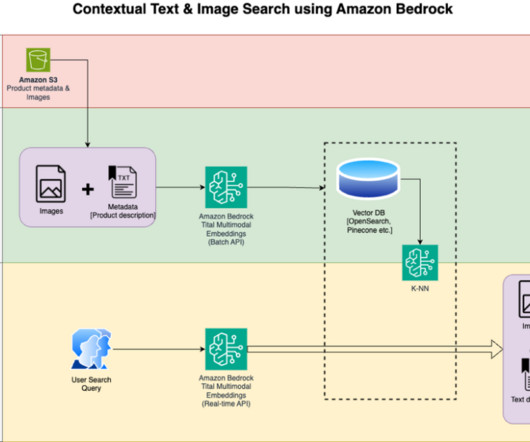
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. These steps are completed prior to the user interaction steps.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. In the user interaction phase, a question from the user is converted into embeddings and a similarity search is run on the vector database to find a slide that could potentially contain answers to user question.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. ML-based predictive models nowadays may consider time-dependent components — seasonality, trends, cycles, irregular components, etc. — to
In this series, we will set up AWS OpenSearch , which will serve as a vector database for a semantic search application that well develop step by step. Semantic search improves accuracy by leveraging machine learning (ML), natural language processing (NLP), and vector search techniques to deliver more relevant, intent-driven results.
In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). Deploy the solution as a local web application. About the Authors.
The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. In traditional RAG use cases, the chatbot relies on a database of text documents (.doc,pdf, In this first post, we focus on the basics of RAG architecture and how to optimize text-only RAG. doc,pdf, or.txt).
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
Kinesis Video Streams makes it straightforward to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. He is passionate about IoT, AI/ML and building smart home devices. It enables real-time video ingestion, storage, encoding, and streaming across devices.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
This includes sales collateral, customer engagements, external web data, machine learning (ML) insights, and more. AI-driven recommendations – By combining generative AI with ML, we deliver intelligent suggestions for products, services, applicable use cases, and next steps.
We use OpenSearch Serverless as a vector database for storing embeddings generated by the LVM. The query with embeddings is sent to the OpenSearch vector index, which performs a k-nearestneighbors (k-NN) search to retrieve relevant frame embeddings. The retrieved frame embeddings undergo temporal clustering.
The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. On one hand, there’s a data management community trying to understand data transformation and computing some functions over exponentially many databases for decades. A transcript of the talk follows.
The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. On one hand, there’s a data management community trying to understand data transformation and computing some functions over exponentially many databases for decades. A transcript of the talk follows.
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean. K-NN (knearestneighbors): K-NearestNeighbors (K-NN) is a simple yet powerful algorithm used for both classification and regression tasks in Machine Learning.
Powering Neural Search : Enables advanced similarity-based retrieval using OpenSearchs k-NN (k-NearestNeighbors) indexing. Registering the Model in OpenSearch We first register the model using OpenSearchs ML Commons API. It then initializes an OpenSearch client to connect to the database.
#LuxuryBrand #TimelessElegance #ExclusiveCollection Retrieve and analyze the top three relevant posts The next step involves using the generated image and text to search for the top three similar historical posts from a vector database. The following code snippet shows the implementation of this step.
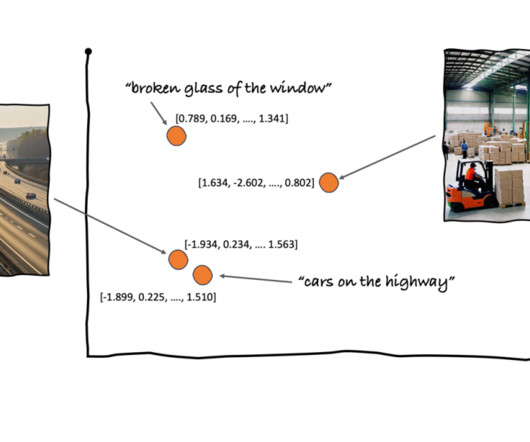
Source: [link] The previous system works this way: there is a bank of face images, their corresponding embeddings are stored in a vector database and the labels are also available. They also enable few-shot learning for training ML models, reducing the number of examples needed.
Let us first understand the meaning of bias and variance in detail: Bias: It is a kind of error in a machine learning model when an ML Algorithm is oversimplified. It is introduced into an ML Model when an ML algorithm is made highly complex. In such types of questions, we first need to ask what ML model we have to train.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content