This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview In this article, we will be predicting that whether the patient has diabetes or not on the basis of the features we will provide to our machinelearning model, and for that, we will be using the famous Pima Indians Diabetes Database. Image […].
Introduction In this article, we will learn about machinelearning using Spark. Our previous articles discussed Spark databases, installation, and working of Spark in Python. The post Machinelearning Pipeline in Pyspark appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Image 1 Introduction In this article, I will use the YouTube Trends database and Python programming language to train a language model that generates text using learning tools, which will be used for the task of making youtube video articles or for your blogs. […].
Introduction Source – mccinnovations.com Do you ever wonder how companies develop and train machinelearning models without experts? Well, the secret is in the field of Automated MachineLearning (AutoML).
This blog discusses vector databases, specifically pinecone vector databases. A vector database is a type of database that stores data as mathematical vectors, which represent features or attributes. These vectors have multiple dimensions, capturing complex data relationships.
7 MachineLearning Portfolio Projects to Boost the Resume • How to Select Rows and Columns in Pandas Using [ ],loc, iloc,at and.iat • Decision Tree Algorithm, Explained • Free SQL and Database Course • 5 Tricky SQL Queries Solved.
The machinelearning lifecycle is an intricate series of stages that guides the development and deployment of machinelearning models. What is the machinelearning lifecycle? The machinelearning lifecycle serves as a framework for managing projects that incorporate machinelearning techniques.
Databricks, the lakehouse company, announced the launch of Databricks Model Serving to provide simplified production machinelearning (ML) natively within the Databricks Lakehouse Platform. Model Serving removes the complexity of building and maintaining complicated infrastructure for intelligent applications.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
In the dynamic world of machinelearning and natural language processing (NLP), database optimization is crucial for effective data handling. Hence, the pivotal role of vector databases in the efficient storage and retrieval of embeddings has become increasingly apparent.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
Whether you’re an expert, a curious learner, or just love data science and AI, there’s something here for you to learn about the fundamental concepts. They cover everything from the basics like embeddings and vector databases to the newest breakthroughs in tools.
Certain solutions in this space combine vector databases and applications of LLMs alongside knowledge graph environs, which are ideal for employing Graph Neural Networks and other forms of advanced machinelearning.
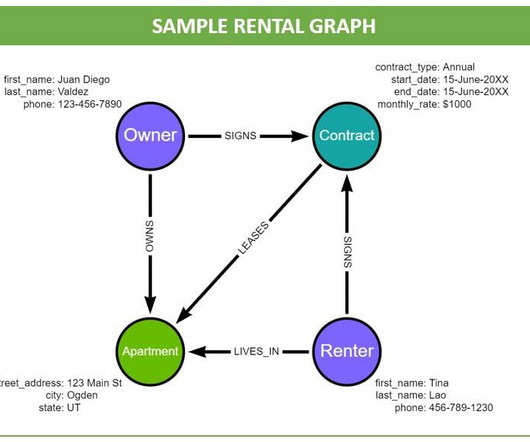
Introduction Graph databases have gained significant popularity in recent years due to their ability to store and analyze highly connected data efficiently. This article will explore the top 9 […] The post Top 9 Open Source Graph Databases appeared first on Analytics Vidhya.
It follows a declarative syntax to define Services and their Configurations for your applications, which can […] The post A Comprehensive Guide on Using Docker Compose for MachineLearning Containers appeared first on Analytics Vidhya.
It powers business decisions, drives AI models, and keeps databases running efficiently. Without proper organization, databases become bloated, slow, and unreliable. Essentially, data normalization is a database design technique that structures data efficiently. Think about itdata is everywhere.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
Introduction In the rapidly evolving landscape of generative AI, the pivotal role of vector databases has become increasingly apparent. This article dives into the dynamic synergy between vector databases and generative AI solutions, exploring how these technological bedrocks are shaping the future of artificial intelligence creativity.
Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Applied MachineLearning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
From humble beginnings to influential […] The post The Journey of a Senior Data Scientist and MachineLearning Engineer at Spice Money appeared first on Analytics Vidhya. In this article, we explore Tajinder’s inspiring success story.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
Graph databases are quickly becoming a core part of the analytics toolset for enterprise IT organizations. If you know SQL, you can easily learn Cypher and open up a huge opportunity for data analysis.
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Database name : Enter dev. Choose Add connection.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
MongoDB is a type of NoSQL database which is open-sourced and widely used in data science and machinelearning in form of a database. This article was published as a part of the Data Science Blogathon. Hence, knowledge of it is important in the long run, especially in the field of data science and analytics. […].
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
Among such tools, today we will learn about the workings and functions of ChromaDB, an open-source vector database to store embeddings from […] The post Build Semantic Search Applications Using Open Source Vector Database ChromaDB appeared first on Analytics Vidhya.
Source: [link] Introduction Amazon Web Services (AWS) is a cloud computing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machinelearning, etc. AWS has seven types of storage services which include Elastic Block Storage […].
They require strong programming skills, knowledge of statistical analysis, and expertise in machinelearning. MachineLearning Engineer Machinelearning engineers are responsible for designing and building machinelearning systems.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machinelearning, AI and deep learning. The team here at insideBIGDATA is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machinelearning, AI and deep learning. The team here at insideAI News is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
In this contributed article, Dave Voutila, solutions engineer at Redpanda, does a dive deep into the world of graph and vector databases, explores how these technologies are converging in the age of generative AI and provides real-time insights on how organizations can effectively leverage each approach to drive their businesses.
Nearest neighbour search over dense vector collections has important applications in information retrieval, retrieval augmented generation (RAG), and content ranking. Performing efficient search over large vector collections is a well studied problem with many existing approaches and open source implementations.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machinelearning, AI and deep learning. The team here at insideBIGDATA is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machinelearning, AI, and deep learning. Our industry is constantly accelerating with new products and services being announced everyday.
It is a programming language used to manipulate data stored in relational databases. Here are some essential SQL concepts that every data scientist should know: First, understanding the syntax of SQL statements is essential in order to retrieve, modify or delete information from databases.
Patients and methods In this study, we used a machinelearning approach that used the US-based nationwide de-identified Flatiron Health and Foundation Medicine non-small cell lung carcinoma (NSCLC) clinico-genomic database to identify genomic markers that predict clinical responses to CPI therapy.
ChatGPT can also use Wolfram Language to perform more complex tasks, such as simulating physical systems or training machinelearning models. Deploy machinelearning Models: You can use the plugin to train and deploy machinelearning models.
In this column, we present a variety of short time-critical news items grouped by category such as M&A activity, people movements, funding news, financial results, industry alignments, customer wins, rumors and general scuttlebutt floating around the big data, data science and machinelearning industries including behind-the-scenes anecdotes and (..)
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machinelearning, AI and deep learning. The team here at insideBIGDATA is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content