This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Most of us are familiar with SQL, and many of us have hands-on experience with it. The post BigQuery: An Walkthrough of ML with Conventional SQL appeared first on Analytics Vidhya. Machine learning is an increasingly popular and developing trend among us.
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval.
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
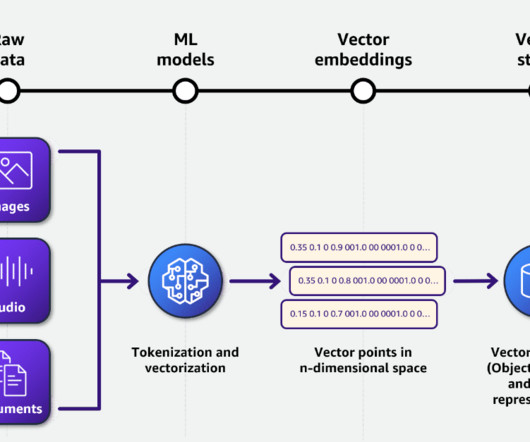
Data, undoubtedly, is one of the most significant components making up a machine learning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
By setting up automated policy enforcement and checks, you can achieve cost optimization across your machine learning (ML) environment. The following table provides examples of a tagging dictionary used for tagging ML resources. A reference architecture for the ML platform with various AWS services is shown in the following diagram.
Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications. Demand for applied ML scientists remains high, as more companies focus on AI-driven solutions for scalability.
It powers business decisions, drives AI models, and keeps databases running efficiently. Without proper organization, databases become bloated, slow, and unreliable. Essentially, data normalization is a database design technique that structures data efficiently. Think about itdata is everywhere.
Artificial intelligence is no longer fiction and the role of AI databases has emerged as a cornerstone in driving innovation and progress. An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. This application allows users to ask questions in natural language and then generates a SQL query for the users request.
In this post, we employ the LLM-as-a-judge technique to evaluate the text-to-SQL and chain-of-thought capabilities of Amazon Bedrock Agents. These include a sample RAG agent, a sample text-to-SQL agent, and pharmaceutical research agents that use multi-agent collaboration for cancer biomarker discovery.
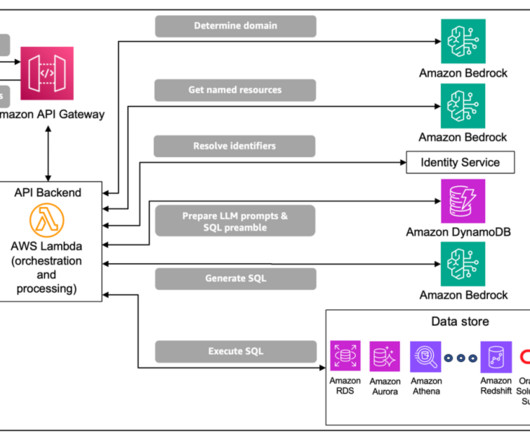
This post explores deploying a text-to-SQL pipeline using generative AI models and Amazon Bedrock to ask natural language questions to a genomics database. We demonstrate how to implement an AI assistant web interface with AWS Amplify and explain the prompt engineering strategies adopted to generate the SQL queries.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machine learning (ML) initiatives. This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Basic knowledge of a SQL query editor.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. With the emergence of large language models (LLMs), NLP-based SQL generation has undergone a significant transformation.
Solution overview Typically, a three-tier software application has a UI interface tier, a middle tier (the backend) for business APIs, and a database tier. Generate, run, and validate the SQL from natural language understanding using LLMs, few-shot examples, and a database schema as a knowledge base.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
NOTE : Since we used an SQL query engine to query the dataset for this demonstration, the prompts and generated outputs mention SQL below. NOTE : Since we used an SQL query engine to query the dataset for this demonstration, the prompts and generated outputs mention SQL below.
By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, ML engineers, and application developers to harness the full potential of FMs while addressing unique application requirements. We use the sql-create-context dataset available on Hugging Face for fine-tuning.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
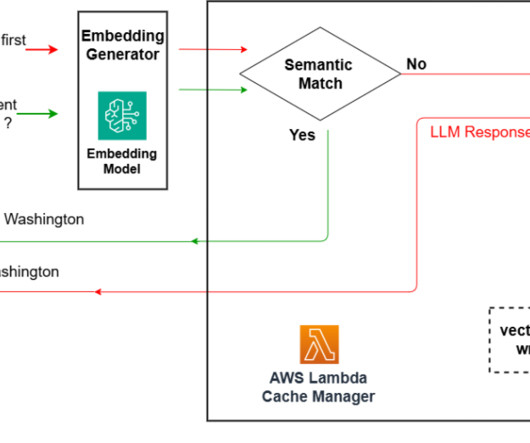
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
By employing a multi-modal approach, the solution connects relevant data elements across various databases. Based on the customer query and context, the system dynamically generates text-to-SQL queries, summarizes knowledge base results using semantic search , and creates personalized vehicle brochures based on the customers preferences.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. Use Amazon Athena SQL queries to provide insights.
Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL. But why is SQL, or Structured Query Language , so important to learn? Let’s start with the first clause often learned by new SQL users, the WHERE clause.
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. The primary goal is to automatically generate SQL queries from natural language text. What percentage of customers are from each region?”
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Meta Llama 3’s capabilities enhance accuracy and efficiency in understanding and generating SQL queries from natural language inputs.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
For example, with MCP an AI model could fetch information from a database, edit a design in Figma, or control a music app all by sending natural-language instructions through a standardized interface. Developers were dealing with fragmented integrations everywhere. Not only is this labor-intensive; its brittle and doesnt scale.
Now, consider a different scenario: an AI assistant, designed to assist back desk agents at this travel company, uses an LLM to translate natural language queries into SQL commands. We need every user request mapped accurately to its corresponding SQL command, leaving no room for error. Precision is key here.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
Additionally, how ML Ops is particularly helpful for large-scale systems like ad auctions, where high data volume and velocity can pose unique challenges. Getting Started with SQL Programming: Are you starting your journey in data science? If you’re new to SQL, this beginner-friendly tutorial is for you!
By harnessing the power of threat intelligence, machine learning (ML), and artificial intelligence (AI), Sophos delivers a comprehensive range of advanced products and services. The Sophos Artificial Intelligence (AI) group (SophosAI) oversees the development and maintenance of Sophos’s major ML security technology.
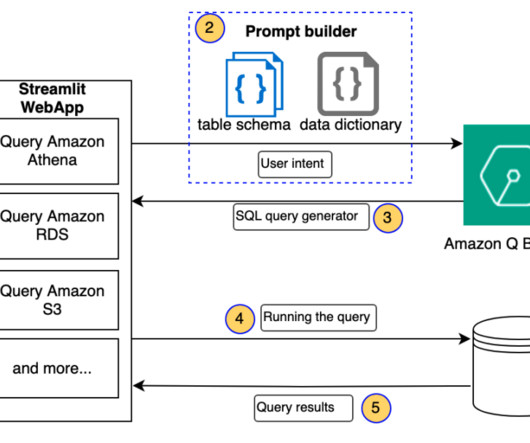
For example, SQL queries can be complex and unintuitive for non-technical users. Handling complex queries involving multiple tables, joins, and aggregations makes it difficult to interpret user intent and translate it into correct SQL operations. Amazon Q Business analyzes intent, accesses data sources, and generates the SQL query.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
What do machine learning engineers do: ML engineers design and develop machine learning models The responsibilities of a machine learning engineer entail developing, training, and maintaining machine learning systems, as well as performing statistical analyses to refine test results. Is ML engineering a stressful job?
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQLdatabases, Amazon CloudWatch logs, and third-party tools to check the live system health status. This removed a considerable amount of data in the ETL process even before ingesting into the knowledge base.
Dataiku’s join recipe lets you customize how to join tables together From Data to Predictions Using Visual ML Dataiku’s automated feature engineering tools further accelerate the preparation process by automatically generating features based on the dataset’s content. Dataiku and Snowflake: A Good Combo?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content