This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A question database will be used for this article and […]. The post NaturalLanguageProcessing Using CNNs for Sentence Classification appeared first on Analytics Vidhya. A sentence is classified into a class in sentence classification.
They cover everything from the basics like embeddings and vector databases to the newest breakthroughs in tools. This guide is invaluable for understanding how LLMs drive innovations across industries, from naturallanguageprocessing (NLP) to automation.
Introduction In the field of artificial intelligence, Large Language Models (LLMs) and Generative AI models such as OpenAI’s GPT-4, Anthropic’s Claude 2, Meta’s Llama, Falcon, Google’s Palm, etc., LLMs use deep learning techniques to perform naturallanguageprocessing tasks.
Introduction Innovative techniques continually reshape how machines understand and generate human language in the rapidly evolving landscape of naturallanguageprocessing.
Introduction In the field of modern data management, two innovative technologies have appeared as game-changers: AI-language models and graph databases. AI language models, shown by new products like OpenAI’s GPT series, have changed the landscape of naturallanguageprocessing.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Vector databases are revolutionizing healthcare data management. Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information.
In the dynamic world of machine learning and naturallanguageprocessing (NLP), database optimization is crucial for effective data handling. Hence, the pivotal role of vector databases in the efficient storage and retrieval of embeddings has become increasingly apparent.
Introduction In the rapidly evolving field of NaturalLanguageProcessing (NLP), one of the most intriguing challenges is converting naturallanguage queries into SQL statements, known as Text2SQL.
Vector databases enable fast similarity search and scale across data points. For LLM apps, vector indexes can simplify architecture over full vector databases by attaching vectors to existing storage. Choosing indexes vs databases depends on specialized needs, existing infrastructure, and broader enterprise requirements.
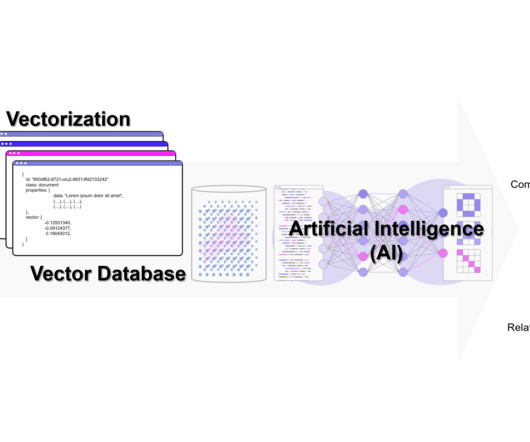
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.
These architectures are being used to develop new LLM applications in a variety of fields, such as naturallanguageprocessing, machine translation, and healthcare. These architectures are being used to develop new LLM applications in a variety of fields, such as naturallanguageprocessing, machine translation, and healthcare.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is NaturalLanguageProcessing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
LLMs like GPT-4 are pre-trained on massive public datasets, allowing for incredible naturallanguageprocessing capabilities out of the box. It supports a variety of data sources, including APIs, databases, and PDFs. The data is converted into a simple document format that is easy for LlamaIndex to process.
Artificial intelligence is no longer fiction and the role of AI databases has emerged as a cornerstone in driving innovation and progress. An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications.
RAG represents a powerful advancement in naturallanguageprocessing, effectively merging the strengths of generative and […] The post Graph RAG: Enhancing Retrieval-Augmented Generation with Graph Structures appeared first on Analytics Vidhya. That’s the magic of the Retrieval-Augmented Generation (RAG).
Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. Vector Similarity Search This video explains what vector databases are and how they can be used for vector similarity searches.
The well-known chatbot called ChatGPT, based on GPT architecture and developed by OpenAI, imitates humans by generating accurate and creative content, answering questions, summarizing massive textual paragraphs, and language translation. What are Vector Databases?
For example, if you’re building a chatbot, you can combine modules for naturallanguageprocessing (NLP), data retrieval, and user interaction. It also connects effortlessly with collaboration tools like Airtable, Trello, Figma, and Notion, as well as databases including Pandas, MongoDB, and Microsoft databases.
The learning program is typically designed for working professionals who want to learn about the advancing technological landscape of language models and learn to apply it to their work. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
DeepSeek AI is an advanced AI genomics platform that allows experts to solve complex problems using cutting-edge deep learning, neural networks, and naturallanguageprocessing (NLP). What is DeepSeek AI? DeepSeek AI, on the other hand, isnt just another fancy AI gadget, its a revolutionary breakthrough.
In parallel to the rise of end-to-end ASR systems, large language models (LLMs) have proven to be a versatile tool for various naturallanguageprocessing (NLP) tasks. In NLP tasks where a database of relevant knowledge is available, retrieval augmented generation (RAG) has achieved impressive results when used with LLMs.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Metadata filtering allows you to segment data inside of an OpenSearch Serverless vector database.
Moreover, interest in small language models (SLMs) that enable resource-constrained devices to perform complex functionssuch as naturallanguageprocessing and predictive automationis growing. The generated embeddings are sent to the vector database and stored, completing the knowledge base creation.
This blog lists several YouTube channels that can help you get started with llms, generative AI, prompt engineering, and more. Large language models, like GPT-3.5, have revolutionized the field of naturallanguageprocessing.
Large language models, like GPT-3.5, have revolutionized the field of naturallanguageprocessing. These models are at the forefront of advancements in artificial intelligence and naturallanguageprocessing.
This means that when you ask a RAG-powered model a question, it doesn’t just rely on what it learned during training; instead, it can consult a vast, constantly updated external database to provide an accurate and relevant answer. But what exactly is a vector database? Why use RAG? Why vectors?:
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
It is an AI framework and a type of naturallanguageprocessing (NLP) model that enables the retrieval of information from an external knowledge base. It integrates retrieval-based and generation-based approaches to provide a robust database for LLMs. Language translation Translation is a tricky process.
These steps will guide you through deleting your knowledge base, vector database, AWS Identity and Access Management (IAM) roles, and sample datasets, making sure that you don’t incur unexpected costs. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. However, it can also be a time-consuming and computationally expensive process.
This blog lists several YouTube channels that can help you get started with llms, generative AI, prompt engineering, and more. Large language models, like GPT-3.5, have revolutionized the field of naturallanguageprocessing.
and other large language models (LLMs) have transformed naturallanguageprocessing (NLP). Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more.
With the advent of generative AI, the complexity of data makes vector embeddings a crucial aspect of modern-day processing and handling of information. Use cases of vector embeddings in generative AI There are different applications of vector embeddings in generative AI. The embeddings are also capable of.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
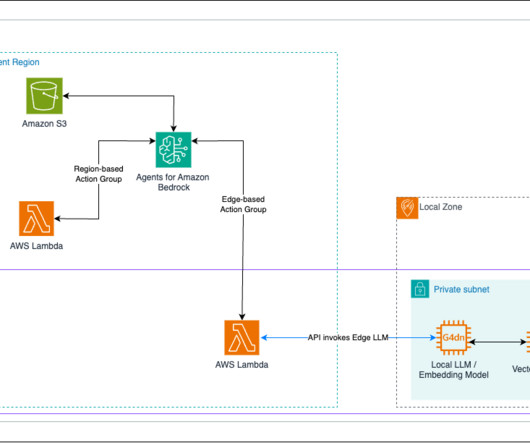
With AWS, you have access to scalable infrastructure and advanced services like Amazon Neptune , a fully managed graph database service. Implementing GraphRAG from scratch usually requires a process similar to the following diagram. Lettria provides an accessible way to integrate GraphRAG into your applications.
Für NaturalLanguageProcessing ( NLP ) benötigen Modelle des Deep Learnings die zuvor genannten Word Embedding, also hochdimensionale Vektoren, die Informationen über Worte, Sätze oder Dokumente repräsentieren.
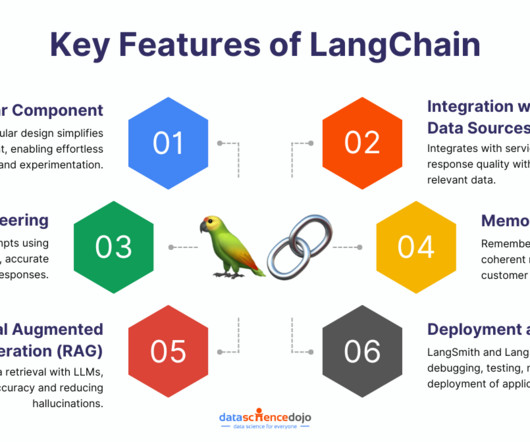
Agents: LangChain offers a flexible approach for tasks where the sequence of language model calls is not deterministic. The library also integrates with vector databases and has memory capabilities to retain the state between calls, enabling more advanced interactions.
Diagrams ⚡PRO BUILDER⚡ The Diagrams Pro Builder excels at visualizing codes and databases. Other outputs include database diagrams and code visualizations. It uses machine learning and naturallanguageprocessing for automation and enhancement of data analytical processes.
This addresses data management, conversational interface and naturallanguageprocessing needs with efficiency. IBM Db2 : A reliable, high-performance database built for enterprise-level applications, designed to efficiently store, analyze and retrieve data.
The RAG system combines machine learning and naturallanguageprocessing with a vast database of industry-specific information, enabling AI to provide highly accurate responses on professional topics. This success was made possible by integrating advanced AI technologies with a deep understanding of banking workflows.
Store these chunks in a vector database, indexed by their embedding vectors. While the overall process may be more complicated in practice, this is the gist. The various flavors of RAG borrow from recommender systems practices, such as the use of vector databases and embeddings. Split each document into chunks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content