This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the rapidly evolving field of NaturalLanguageProcessing (NLP), one of the most intriguing challenges is converting naturallanguage queries into SQL statements, known as Text2SQL.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
Introduction In the field of modern data management, two innovative technologies have appeared as game-changers: AI-language models and graph databases. AI language models, shown by new products like OpenAI’s GPT series, have changed the landscape of naturallanguageprocessing.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
Artificial intelligence is no longer fiction and the role of AI databases has emerged as a cornerstone in driving innovation and progress. An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. With the emergence of large language models (LLMs), NLP-based SQL generation has undergone a significant transformation.
One such area that is evolving is using naturallanguageprocessing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Deep Learning with KNIME: This tutorial will provide theoretical and practical introductions to three deep learning topics using the KNIME Analytics Platform’s Keras Integration; first, how to configure and train an LSTM network for language generation; we’ll have some fun with this and generate fresh rap songs!
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and naturallanguageprocessing (NLP) tasks since 2010.
Neben den relationalen Datenbanken (SQL) gibt es auch die NoSQL -Datenbanken wie den Key-Value-Store, Dokumenten- und Graph-Datenbanken mit recht speziellen Anwendungsgebieten. In diesen geht nur leider dann doch irgendwann das Wissen verloren… Und das auch dann, wenn es nie aus ihnen herausgelöscht wird!
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. However, it can also be a time-consuming and computationally expensive process.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
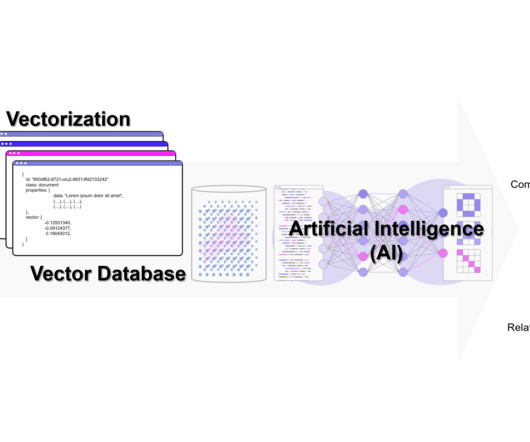
In our previous article on Retrieval Augmented Generation (RAG), we discussed the need for a Vector Database to retrieve additional information for our prompts. Today, we will dive into the inner workings of a Vector Database to better understand exactly how this technology functions. What is a Vector Database in Simple Terms?
Photo by Sneaky Elbow on Unsplash The advent of large language models (LLMs), such as OpenAI’s GPT-3, has ushered in a new era of possibilities in the realm of naturallanguageprocessing. At present, there’s a growing buzz around Vector Databases. However, these new technologies bring their own set of challenges.
The naturallanguage capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. The CloudFormation script created a database called sagemaker. Let’s populate this database with tables for the RStudio user to query. Loading data in Amazon Redshift Serverless.
We use Knowledge Bases for Amazon Bedrock to fetch from historical data stored as embeddings in the Amazon OpenSearch Service vector database. An LLM evaluates each question along with the chat history from the same session to determine its nature and which subject area it falls under (such as SQL, action, search, or SME).
NaturalLanguageProcessing (NLP) for application design One of the most significant intersections between Gen AI and low-code development is through NLP. Developers can interact with LCNC platforms using naturallanguage queries or prompts. Gen AI plays a pivotal role in automating these processes.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Amazon Bedrock Guardrails implements content filtering and safety checks as part of the query processing pipeline.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing.
We formulated a text-to-SQL approach where by a user’s naturallanguage query is converted to a SQL statement using an LLM. The SQL is run by Amazon Athena to return the relevant data. Amazon Kendra uses naturallanguageprocessing (NLP) to understand user queries and find the most relevant documents.
Their work has set a gold standard for integrating advanced naturallanguageprocessing (NLP ) into clinical settings. Speed: Handling large patient histories stretches GPT models, even with long context windows, and demands pre-optimized databases. Consistency: Variability in responses undermines clinician trust.
Vector Databases — Long Term Memory for AI Photo by Sven Brandsma on Unsplash Introduction In naturallanguageprocessing (NLP), a vector is a mathematical representation of a word or text document. The Database One such solution for this problem is Elasticsearch. Conclusion So easy right!!
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using naturallanguage, without the need to write SQL queries or learn a BI tool.
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. Multiple days of data can be processed by separate Processing jobs simultaneously. Employ AWS Glue for data crawling after processing multiple days of data.
These models are the technology behind Open AI’s DALL-E and GPT-3 , and are powerful enough to understand naturallanguage commands and generate high-quality code to instantly query databases. They can be fine-tuned on a smaller dataset to perform a specific task, such as language translation or summarization.
They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
For structured data, the agent uses the SQL Connector and SQLAlchemy to analyze databases, which includes Amazon Athena. Session(region_name=region_name) athena_client = session.client('athena') database=database_name table=table_Name. It can query a stocks database to answer questions on stocks.
Analysts need to learn new tools and even some programming languages such as SQL (with different variations). Action groups – Action groups are interfaces that an agent uses to interact with the different underlying components such as APIs and databases.
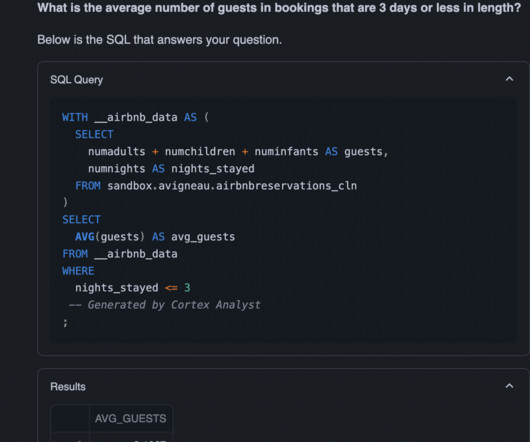
With Cortex Analyst from the Snowflake AI Data Cloud , business users can transform plain English questions into SQL queries, enabling self-service analytics and making data insights more accessible. This is especially powerful for users who may have pressing questions about their data but might not have the SQL-writing experience to do so.
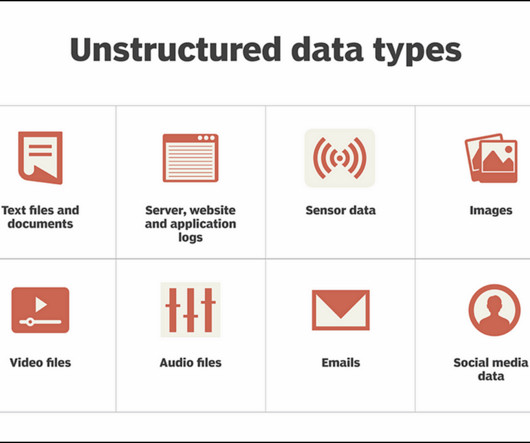
A database that help index and search at blazing speed. Relational databases (like MySQL) or No-SQLdatabases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. Unstructured data is hard to store in relational databases.
Additionally, its naturallanguageprocessing capabilities and Machine Learning frameworks like TensorFlow and scikit-learn make Python an all-in-one language for Data Science. SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases.
To ensure security and JSON/pickle benefits, you can save your model to a dedicated database. Next, you will see how you can save an ML model in a database. Storing ML models in a database There is also scope for you to save your ML models in relational databases PostgreSQL , MySQL , Oracle SQL , etc.
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional naturallanguageprocessing remains essential: Plan, Prepare Data, Engineer Model, Evaluate, Deploy, Operate, and Monitor. Previously, consultants spent weeks manually querying data.
Origins of Generative AI and NaturalLanguageProcessing with ChatGPT Joining in on the fun of using generative AI, we used ChatGPT to help us explore some of the key innovations over the past 50 years of AI. Databases for the Era of Artificial Intelligence Everyone is talking about ChatGPT.
Whether you want nodes to publish your data to Tableau Server, connect to a Snowflake Data Cloud database , or perform image or audio analyses, there is an extension for you. If you need to connect to a database for any purpose, this extension cannot be ignored. These include Microsoft SQL Server, MySQL, Oracle, and PostgreSQL.
This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. Access to Amazon OpenSearch as a vector database. The choice of vector database is an important architectural decision. Clean data is important for good model performance.
It offers AI-driven analytics, including NaturalLanguageProcessing. Supports diverse data sources: Excel, SQL Server, Azure, and more. Also, it supports a wide range of data sources, including Excel spreadsheets, cloud services like Azure, and on-premises databases. Can Power BI Handle Real-Time Data?
This opens up a data engineer to create their transformation in Snowflake using python code instead of just SQL. Sentiment Analysis is a naturallanguageprocessing (NLP) technique that tries to determine if data is positive or negative. Models are created via SQL or Python and can be materialized in various ways.
His past roles have included work in analytics, big data, R, SQL, data mining, and more. Vargas’ responsibilities at Microsoft also include advisor to Microsoft CTO, AI scalability, and strategy expert, and lead for the organization’s AI at Scale Initiative and Azure Database Services. Looking for something a little sooner?
Proficiency in programming languages like Python and SQL. Familiarity with SQL for database management. Key Skills Proficiency in programming languages such as Python or Java. Strong understanding of database management systems (e.g., Salary Range: 12,00,000 – 35,00,000 per annum.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Dolt Dolt is an open-source relational database system built on Git. Streaming pipelines to ingest and transform real-time data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content