This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Store these chunks in a vector database, indexed by their embedding vectors. While the overall process may be more complicated in practice, this is the gist. The various flavors of RAG borrow from recommender systems practices, such as the use of vector databases and embeddings. Split each document into chunks.
Generative AI brings powerful capabilities to threat modeling, combining naturallanguageprocessing with visual analysis to simultaneously evaluate systemarchitectures, diagrams, and documentation.
Or was the database password for the central subscription service rotated again? It requires checking many systems and teams, many of which might be failing, because theyre interdependent. Architecture Tool The Architecture Tool uses C4 diagrams to provide a comprehensive view of the systemsarchitecture.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The idea was to use the LLM to first generate a SQL statement from the user question, presented to the LLM in naturallanguage.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Amazon Bedrock Guardrails implements content filtering and safety checks as part of the query processing pipeline.
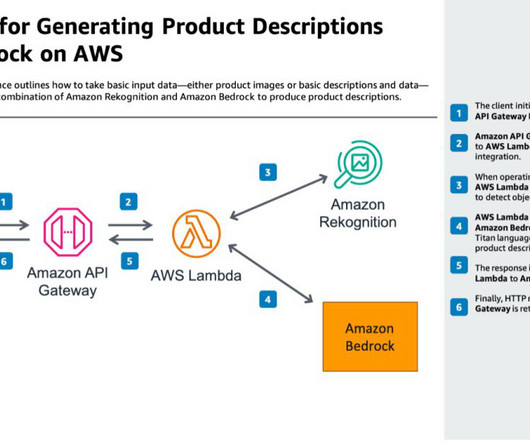
The systemarchitecture comprises several core components: UI portal – This is the user interface (UI) designed for vendors to upload product images. AWS Lambda – AWS Lambda provides serverless compute for processing. Product database – The central repository stores vendor products, images, labels, and generated descriptions.
Utilising advanced naturallanguageprocessing algorithms. 8,45000 Database management, programming (e.g., Java, Scala), data warehousing Build a strong foundation in databases, gain programming skills, and engage in hands-on projects and internships. Implementing transparent data privacy policies.
Systemarchitecture for GNN-based network traffic prediction In this section, we propose a systemarchitecture for enhancing operational safety within a complex network, such as the ones we discussed earlier. He received his PhD in computer systems and architecture at the Fudan University, Shanghai, in 2014.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content